 并行分布式框架 Celery
并行分布式框架 Celery
# 概念
# 异步任务
异步任务是 web 开发中一个很常见的方法。对于一些耗时耗资源的操作,往往从主应用中隔离,通过异步的方式执行。简而言之,做一个注册的功能,在用户使用邮箱注册成功之后,需要给该邮箱发送一封激活邮件。如果直接放在应用中,则调用发邮件的过程会遇到网络 IO 的阻塞,比好优雅的方式则是使用异步任务,应用在业务逻辑中触发一个异步任务。
# 生产者-消费者模式
在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类、函数、线程、进程等)。产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。
单单抽象出生产者和消费者,还够不上是生产者消费者模式。该模式还需要有一个缓冲区处于生产者和消费者之间,作为一个中介。生产者把数据放入缓冲区,而消费者从缓冲区取出数据。
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过消息队列(缓冲区)来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给消息队列,消费者不找生产者要数据,而是直接从消息队列里取,消息队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个消息队列就是用来给生产者和消费者解耦的。
解耦
假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果消费者的代码发生变化,可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。生产者直接调用消费者的某个方法,还有另一个弊端。由于函数调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只好一直等在那边。万一消费者处理数据很慢,生产者就会白白糟蹋大好时光。缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。等生产者的制造速度慢下来,消费者再慢慢处理掉。
# 组件
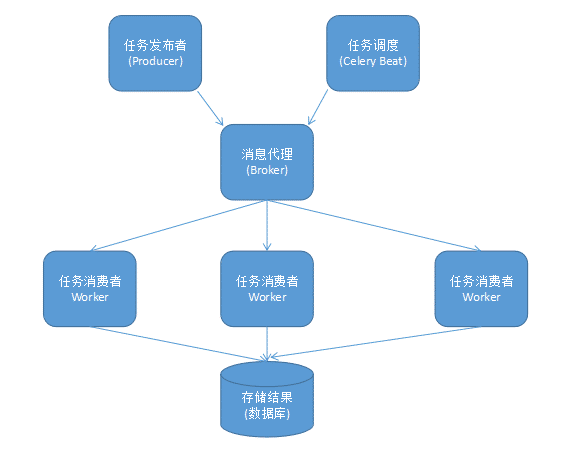
+----------------+ +----------------+ +----------------+
| | | | | |
| 任务生产者 +--->+ Broker +--->+ Worker |
| | | (消息队列) | | (工作进程) |
+----------------+ +----------------+ +----------------+
^ |
| v
+----------------+ +----------------+
| | | |
| Web应用/定时 | | 结果存储 |
| 任务/其他应用 | | (Result Backend)|
| | | |
+----------------+ +----------------+
2
3
4
5
6
7
8
9
10
11
12
13
Task
- 是一个具体的函数或方法,使用
@app.task装饰器标记 - 定义了需要被异步执行的具体业务逻辑
- 例如:发送邮件、处理图片、计算数据等
包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往任务队列,而定时任务由 Celery Beat 进程周期性地将任务发往任务队列。
- Producer
调用了 Celery 提供的 API、函数或者装饰器而产生任务并交给任务队列处理的都是任务生产者。
- Celery Beat
任务调度器,Beat 进程会读取配置文件的内容,周期性地将配置中到期需要执行的任务发送给任务队列。
- 是一个具体的函数或方法,使用
任务生产者 (Task Producer)
- 是调用任务的应用程序部分
- 负责创建任务实例并发送到 Broker
- 可以是 Web 请求处理函数、定时任务或任何需要执行异步操作的代码
Broker
消息代理,又称消息中间件,接受任务生产者发送过来的任务消息,存进队列再按序分发给任务消费方(通常是消息队列或者数据库)。Celery 目前支持 RabbitMQ、Redis、MongoDB、Beanstalk、SQLAlchemy、Zookeeper 等作为消息代理,但适用于生产环境的只有 RabbitMQ 和 Redis, 官方推荐 RabbitMQ。
- Celery Worker
执行任务的消费者,它实时监控消息队列,获取队列中调度的任务并执行。生产中通常会在多台服务器运行多个消费者来提高执行效率。
- Result Backend
任务处理完后保存状态信息和结果,以供查询。Celery 默认已支持 Redis、RabbitMQ、MongoDB、Django ORM、SQLAlchemy 等方式。
# 架构
Celery 的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
- 消息中间件 (Broker)
Celery 本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。包括,RabbitMQ,Redis,MongoDB (experimental), Amazon SQS (experimental),CouchDB (experimental), SQLAlchemy (experimental),Django ORM (experimental),IronMQ
职责:作为任务的 "邮局",负责接收、存储和分发任务
特点:
- 完全独立于 Celery 的第三方服务
- 常见实现:RabbitMQ、Redis、Amazon SQS 等
- 提供可靠的任务缓冲,防止任务丢失
- 支持任务优先级、超时处理等高级特性
任务执行单元 (Worker)
Worker 是 Celery 提供的任务执行的单元,worker 并发的运行在分布式的系统节点中。
职责:作为任务的 "快递员",负责从 Broker 获取任务并执行
特点:
- Celery 的核心组件,专门用于执行任务
- 可以启动多个 Worker 实例形成集群
- 支持动态伸缩(根据负载增加或减少 Worker)
- 可以配置不同类型的 Worker 处理特定类型的任务
任务结果存储
Task result store 用来存储 Worker 执行的任务的结果,Celery 支持以不同方式存储任务的结果,包括 AMQP,redis,memcached,mongodb,SQLAlchemy,Django ORM,Apache Cassandra,IronCache 等。
# 最佳实践
ref:Deni Bertovic :: Celery - Best Practices (opens new window),不习惯看英文的可以看这里 (opens new window)
不要使用数据库作为 AMQP 代理
我们经常为了方便(不需要新的中间件和配置即可使用)而使用数据库作为消息队列,但是在生产环境中可能因为轮询的 io 操作导致数据库崩溃。
使用更多的队列(而不仅仅是默认 default 队列)
默认不做配置的时候,所有的工作都会交给 default 队列去做,可能导致不太重要的任务 b 在做而重要的任务 a 一直在等待
使用优先 workers
- 手动定义队列
CELERY_QUEUES = ( Queue('default', Exchange('default'), routing_key='default'), Queue('for_task_A', Exchange('for_task_A'), routing_key='for_task_A'), Queue('for_task_B', Exchange('for_task_B'), routing_key='for_task_B'), )1
2
3
4
5- route 决定每个任务进入的队列
CELERY_ROUTES = { 'my_taskA': {'queue': 'for_task_A', 'routing_key': 'for_task_A'}, 'my_taskB': {'queue': 'for_task_B', 'routing_key': 'for_task_B'}, }1
2
3
4运行之后我们可以看到如下信息:
celery worker -E -l INFO -n workerA -Q for_task_A celery worker -E -l INFO -n workerB -Q for_task_B1
2使用 celery 的错误处理
retry机制@app.task(bind=True, default_retry_delay=300, max_retries=5) def my_task_a(): try: print("doing stuff here...") except SomeNetworkException as e: print("maybe do some clean up here....") self.retry(e)1
2
3
4
5
6
7由于第三方接口或者网络问题导致的错误,应该使用重试机制。
-
Flower 项目是一个很好的工具,可以监控你的 tasks 和 workers。
只有在你真正需要的时候才记录结果
需要注意的是这里的结果是指 task 的退出状态不是任务执行的作业的结果,通过
CELERY_IGNORE_RESULT = True配置禁用记录保存不要将 Database/ORM 对象传递给任务
序列化的对象可能包含陈旧数据。您需要做的是向任务提供 User id,并让任务向数据库请求一个新的 User 对象。
# 面试题
简述 celery 是什么以及应用场景?
Celery 是一个基于 Python 的分布式任务队列框架,用于实现异步任务和定时任务的调度。
Celery 的主要特点是简单易用、高效稳定、支持分布式、可扩展性强。它可以将耗时的任务放入队列中,由 worker 进行异步处理,从而提高系统的响应速度和并发处理能力。同时,Celery 还支持任务的优先级管理、任务结果的追踪和管理、任务的定时调度等功能。
Celery 的应用场景广泛,适用于各种需要异步处理的场景,例如:
Web 应用中的后台任务:例如发送邮件、生成报表、处理图片等耗时任务,可以将这些任务放入 Celery 队列中由 worker 异步处理,提高 Web 应用的响应速度和并发能力。
分布式任务的调度:Celery 支持多个 worker 的分布式部署,可以实现任务的负载均衡和高可用性,适用于大规模任务的处理场景。
定时任务的调度:Celery 支持任务的定时调度,可以按照设定的时间间隔或指定的时间点执行任务,适用于定时数据处理、定时任务调度等场景。
总之,Celery 是一个强大的分布式任务队列框架,可以帮助开发者实现异步任务和定时任务的调度,提高系统的性能和可扩展性。
简述 celery 运行机制?
Celery 是一个分布式任务队列系统,它通过消息传递来实现任务的分发和执行。Celery 的运行机制可以概括为以下几个步骤:
定义任务:首先,在你的 Celery 应用程序中定义任务函数,这些函数将被异步执行。任务函数通常使用
@app.task装饰器进行修饰,以便 Celery 能够识别它们。配置 Celery 应用程序:配置 Celery 应用程序的参数,包括消息代理的 URL、结果存储的 URL 等。你可以通过
Celery类来创建一个 Celery 应用程序对象,并传入相应的配置参数。启动 Celery 工作者:运行 Celery 工作者(也称为消费者),它将监听消息代理上的任务队列,等待接收任务消息。工作者可以通过命令行或代码启动,例如
celery -A your_app_name worker --loglevel=info。提交任务:在需要执行任务的地方,通过调用任务函数的
apply_async方法提交任务。任务将被序列化并发送到消息代理的任务队列中等待执行。任务分发和执行:工作者从任务队列中获取任务消息,并根据任务的要求执行任务。任务执行的结果可以被发送到结果存储中,以供后续查询。
监控和管理:Celery 提供了丰富的工具和接口来监控和管理任务的执行。你可以使用 Celery 的监控工具来查看任务的执行状态、执行时间等信息。此外,还可以使用 Celery 提供的管理工具来管理任务队列、监控工作者的状态等。
总结起来,Celery 的运行机制是通过消息传递来实现任务的分发和执行。任务通过消息代理传递给工作者,工作者从任务队列中获取任务消息并执行,任务的执行结果可以被发送到结果存储中。Celery 还提供了监控和管理工具来方便地管理任务的执行和监控任务的状态。
celery 如何实现定时任务?
Celery 可以通过定时任务调度器来实现定时任务的功能。下面是使用 Celery 实现定时任务的步骤:
配置 Celery:
- 首先,需要配置 Celery 的消息代理和任务队列。可以选择使用 Redis、RabbitMQ 等作为消息代理,以及定义任务队列的名称。
- 在配置文件中设置 Celery 的相关参数,如消息代理的地址、任务队列的名称等。
创建定时任务:
- 在 Celery 项目中创建一个 tasks.py 文件,用于定义定时任务的函数。
- 在函数上方使用 Celery 的装饰器(如
@app.task)将函数声明为 Celery 任务。 - 在函数内部编写定时任务的逻辑。
设置定时任务调度器:
- 在 Celery 项目中创建一个 beat_schedule.py 文件,用于配置定时任务的调度器。
- 在该文件中,定义一个字典,将定时任务的名称作为键,将任务的调度规则和执行函数作为值进行配置。
- 调度规则可以使用 Crontab 格式来设置,如
crontab(minute=0, hour=0)表示每天 0 点执行。
启动 Celery worker 和 beat:
- 在终端中使用命令
celery -A <celery项目名称> worker --loglevel=info启动 Celery worker,用于执行定时任务。 - 在另一个终端中使用命令
celery -A <celery项目名称> beat --loglevel=info启动 Celery beat,用于定时触发任务。
- 在终端中使用命令
通过以上步骤,Celery 将会按照定时任务调度器中配置的规则来定时触发任务的执行。定时任务的执行结果将会返回给消息代理,并可以在需要时进行查看和处理。
需要注意的是,定时任务调度器(Celery beat)和任务执行者(Celery worker)需要同时运行,才能实现定时任务的功能。
python 测试开发 django-160.Celery 定时任务 (beat) - 上海-悠悠 - 博客园 (opens new window)
简述 celery 多任务结构目录
pro_cel ├── celery_tasks # celery相关文件夹 │ ├── celery.py # celery连接和配置相关文件 │ └── tasks.py # 所有任务函数 ├── check_result.py # 检查结果 └── send_task.py # 触发任务1
2
3
4
5
6celery 中装饰器 @app.task 和 @shared_task 的区别?
在 Celery 中,@app.task 和@shared_task 都是用于定义任务的装饰器。它们的区别在于:
@app.task:这是 Celery 应用程序实例上的装饰器,它用于将函数注册为 Celery 任务。它将任务函数与特定的 Celery 应用程序实例相关联,并在该应用程序上进行任务调度和执行。通常,您将在您的 Celery 应用程序实例上使用这个装饰器来定义您的任务。
@shared_task:这是一个全局装饰器,它可以用于将函数注册为任何 Celery 应用程序的任务。它不需要与特定的 Celery 应用程序实例相关联,因此可以在多个应用程序之间共享任务函数。这在您希望在多个 Celery 应用程序之间共享任务函数时非常有用。
总结来说,@app.task 适用于与特定的 Celery 应用程序实例相关的任务,而@shared_task 适用于在多个 Celery 应用程序之间共享的任务。
在 celery V4 中,我们如下使用:
from myproject.tasks import app @app.task def foo(): pass1
2
3
4
5在编写可重用库或 django 应用程序的实例中如下使用。例如,如果您正在编写一组开源任务,允许您使用 celery 管理 aws ec2 实例,那么您可以使用
shared_task,这样任务就可以在 celery 上运行,可以让使用库的人自行配置 celery。from celery import shared_task @shared_task def foo(): pass1
2
3
4
5ref:python - Difference between different ways to create celery task - Stack Overflow (opens new window)
# 示例
注意
此处直接粘贴复制的,没有验证过,可能与目前最新版存在配置差异,需要读者自行尝试。
# Getting Starting
使用 celery 包含三个方面,其一是定义任务函数,其二是运行 celery 服务,最后是客户应用程序的调用。
创建一个文件 tasks.py
输入下列代码:
from celery import Celery
brokers = 'redis://127.0.0.1:6379/5'
backend = 'redis://127.0.0.1:6379/6'
app = Celery('tasks', broker=broker, backend=backend)
@app.task
def add(x, y):
return x + y
2
3
4
5
6
7
8
9
10
11
上述代码导入了 celery,然后创建了 celery 实例 app,实力话的过程中,指定了任务名tasks(和文件名一致),传入了 broker 和 backend。然后创建了一个任务函数add。
下面就启动 celery 服务
在当前命令行终端运行:
celery -A tasks worker --loglevel=info
2
此时会看见输出,包括注册的任务。
客户端程序如何调用呢?打开一个命令行,进入 Python 环境
In [0]:from tasks import add
In [1]: r = add.delay(2, 2)
In [2]: add.delay(2, 2)
Out[2]: <AsyncResult: 6fdb0629-4beb-4eb7-be47-f22be1395e1d>
In [3]: r = add.delay(3, 3)
In [4]: r.re
r.ready r.result r.revoke
In [4]: r.ready()
Out[4]: True
In [6]: r.result
Out[6]: 6
In [7]: r.get()
Out[7]: 6
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
在 celery 命令行可以看见 celery 执行的日志:
[2015-09-20 21:37:06,086: INFO/MainProcess] Task proj.tasks.add[76beb980-0f55-4629-a4fb-4a1776428ea8] succeeded in 0.00089102005586s: 6
2
打开 backend 的 redis,也可以看见 celery 执行的信息。
现在是在 python 环境中调用的 add 函数,实际上通常在应用程序中调用这个方法。需要注意,如果把返回值赋值给一个变量,那么原来的应用程序也会被阻塞,需要等待异步任务返回的结果。因此,实际使用中,不需要把结果赋值。
# 计划任务
上述的使用是简单的配置,下面介绍一个更健壮的方式来使用 celery。首先创建一个 python 包,celery 服务,姑且命名为 proj。目录文件如下:
☁ proj tree
.
├── __init__.py
├── celery.py # 创建 celery 实例
├── config.py # 配置文件
└── tasks.py # 任务函数
2
3
4
5
6
首先是 celery.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from celery import Celery
app = Celery('proj', include=['proj.tasks'])
app.config_from_object('proj.config')
if __name__ == '__main__':
app.start()
2
3
4
5
6
7
8
9
10
11
12
这一次创建 app,并没有直接指定 broker 和 backend。而是在配置文件中。
# config.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/5'
BROKER_URL = 'redis://127.0.0.1:6379/6'
2
3
4
5
6
7
8
9
10
剩下的就是 tasks.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from proj.celery import app
@app.task
def add(x, y):
return x + y
2
3
4
5
6
7
8
9
使用方法也很简单,在 proj 的同一级目录执行 celery:
celery -A proj worker -l info
现在使用任务也很简单,直接在客户端代码调用 proj.tasks 里的函数即可。
# Scheduler
一种常见的需求是每隔一段时间执行一个任务。配置如下
# config.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/5'
BROKER_URL = 'redis://127.0.0.1:6379/6'
CELERY_TIMEZONE = 'Asia/Shanghai'
from datetime import timedelta
CELERYBEAT_SCHEDULE = {
'add-every-30-seconds': {
'task': 'proj.tasks.add',
'schedule': timedelta(seconds=30),
'args': (16, 16)
},
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
注意配置文件需要指定时区。这段代码表示每隔 30 秒执行 add 函数。
一旦使用了 scheduler, 启动 celery 需要加上-B 参数
celery -A proj worker -B -l info
# crontab
计划任务当然也可以用 crontab 实现,celery 也有 crontab 模式。修改 config.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/5'
BROKER_URL = 'redis://127.0.0.1:6379/6'
CELERY_TIMEZONE = 'Asia/Shanghai'
from celery.schedules import crontab
CELERYBEAT_SCHEDULE = {
# Executes every Monday morning at 7:30 A.M
'add-every-monday-morning': {
'task': 'tasks.add',
'schedule': crontab(hour=7, minute=30, day_of_week=1),
'args': (16, 16),
},
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
总而言之,scheduler 的切分度更细,可以精确到秒。crontab 模式就不用说了。当然 celery 还有更高级的用法,比如多个机器使用,启用多个 worker 并发处理等。