 2022 面试记录
2022 面试记录
# 捷风数据
- (问答题)以任何语言打印一个矩阵,输入是矩阵的行数 rowNum 和矩阵的列数 colNum,这里保证输入的必然是自然数,且小于 Integer.MAX 要求在命令行打印一个如下的蛇形矩阵:
>>> 3*5
# 输出为:
1,6,7,12,13
2,5,8,11,14
3,4,9,10,15
>>> 2*2
# 输出为:
1, 4
2, 3
2
3
4
5
6
7
8
9
10
要求实现的人提供一个 JAR 包或者一个 python 文件, 在命令行使用
python test.py 34
java -jar xxxjar 3 4.
2
3
来打印一个 3*4 的矩阵
# 深光科技
# 1. 索引原理,回表查询,b+树和 b 树区别?为什么不使用红黑树/二叉树,聚簇索引
# 1. 索引的核心原理
索引的核心目标是减少数据检索的磁盘 I/O 次数。数据库通过特定的数据结构(如 B+树)组织索引,使查询时能快速定位数据位置。
# 2. B 树 vs B+树
# B 树(B-Tree)
- 结构特点:
- 每个节点存储键(Key)和对应的数据指针(指向实际数据行的地址)。
- 所有节点均可直接访问数据,类似于“分散式存储”。
- 查询场景:
- 适合随机查询(如主键查询),路径上可能直接命中数据。
- 缺点:
- 范围查询效率低(需跨多个节点遍历)。
- 节点存储数据指针,导致单个节点能存储的键数量较少,树的高度较高。
# B+树(B+Tree)
- 结构特点:
- 非叶子节点仅存储键,不存储数据指针,仅用于导航。
- 所有数据指针集中在叶子节点,且叶子节点通过双向链表连接。
- 优势:
- 树的高度更低:非叶子节点不存数据指针,单个节点可容纳更多键,减少树的高度。
- 范围查询高效:叶子节点的链表结构可直接遍历,无需回溯到上层节点。
- 全盘扫描更快:所有数据均存储在叶子节点,顺序访问性能极佳。
# B 树与 B+树对比
| 特性 | B 树 | B+树 |
|---|---|---|
| 数据存储位置 | 所有节点均可存储数据指针 | 仅叶子节点存储数据指针 |
| 范围查询效率 | 低(需中序遍历) | 高(叶子节点链表直接遍历) |
| 树的高度 | 较高 | 较低 |
| 适用场景 | 随机查询为主 | 范围查询、顺序访问为主 |
# 3. 为什么不用红黑树或二叉树
# 关键问题:磁盘 I/O 效率
- 红黑树/二叉树是二叉树结构:
- 每个节点最多 2 个子节点,树的高度为
O(log N)(以 2 为底)。 - 对于海量数据(例如 1 亿行),树的高度可能达到约 30 层,每次查询需要 30 次磁盘 I/O。
- 每个节点最多 2 个子节点,树的高度为
- B+树是多路平衡树:
- 每个节点可包含大量子节点(如 1000 个),树的高度为
O(log_m N)(m 为分支因子)。 - 同样 1 亿行数据,B+树高度仅需 3 层,大幅减少磁盘 I/O 次数。
- 每个节点可包含大量子节点(如 1000 个),树的高度为
# 示例对比
假设每个节点存储 1000 个键:
- B+树高度为 3 时,可存储
1000^3 = 10亿个键。 - 二叉树高度为 30 时,仅能存储
2^30 ≈ 10亿个键,但需要 30 次磁盘 I/O。
# 其他原因
- 磁盘预读特性:B+树一个节点的大小通常设计为磁盘块大小(如 4KB),充分利用磁盘预读(一次 I/O 读取整个节点)。
- 平衡代价:红黑树的旋转操作频繁,维护平衡的代价高;B+树通过分裂/合并操作更适应磁盘存储。
# 4. 聚簇索引(Clustered Index)
# 定义
- 聚簇索引决定了表中数据的物理存储顺序,即数据行按索引键的顺序存储。
- 一个表只能有一个聚簇索引(通常是主键索引)。
# 优势
范围查询高效:相邻数据物理上连续存储,减少磁盘寻道时间。
SELECT * FROM user WHERE id BETWEEN 100 AND 200; -- 主键范围查询1覆盖索引优化:若查询字段包含在聚簇索引中,可直接返回数据,无需回表。
# 与非聚簇索引的区别
| 特性 | 聚簇索引 | 非聚簇索引(二级索引) |
|---|---|---|
| 数据存储 | 索引叶子节点直接存储数据行 | 叶子节点存储主键值 |
| 查询流程 | 直接命中数据 | 需回表查询(通过主键二次查找) |
| 数量限制 | 一个表仅一个 | 可创建多个 |
# 什么是回表查询
回表查询是数据库查询优化中的一个重要概念,主要与数据库索引结构(尤其是B+树索引)的设计和查询过程相关。以下是通俗易懂的解释:
当数据库使用非聚集索引(二级索引)进行查询时,如果查询所需的字段没有完全包含在索引中,数据库需要通过索引找到主键值后,再回到聚集索引(主键索引)中查找完整的数据行。这种“先查索引,再查主键索引”的过程称为回表查询(Bookmark Lookup 或 Index Lookup)。
# 为什么需要回表
索引的结构:
- 非聚集索引(如普通索引)的叶子节点存储的是主键值(而非完整数据)。
- 聚集索引的叶子节点存储的是完整的数据行(如 InnoDB 的主键索引)。
查询流程:
- 当通过非聚集索引查询时,数据库会先找到符合条件的主键值。
- 如果需要的字段不在非聚集索引中,数据库必须根据主键值回到聚集索引中查找完整数据行。
# 举个实际例子
假设有一张用户表 user,结构如下:
CREATE TABLE user (
id INT PRIMARY KEY, -- 主键(聚集索引)
name VARCHAR(50), -- 用户名
age INT, -- 年龄
INDEX idx_age (age) -- 非聚集索引(二级索引)
);
2
3
4
5
6
执行查询:
SELECT name FROM user WHERE age = 25;
查询过程:
- 通过非聚集索引
idx_age快速找到age=25的所有主键值(即对应的id)。 - 根据这些
id回到聚集索引(主键索引)中查找对应的完整数据行。 - 从完整数据行中提取
name字段返回。
这里就发生了回表查询!
# 回表查询的性能问题
- 额外 I/O 开销:需要两次索引查找(非聚集索引 → 聚集索引)。
- 性能下降:当数据量较大时,回表可能导致查询速度显著降低。
# 如何避免回表
覆盖索引(Covering Index)
确保查询的字段全部包含在索引中,避免回表。
例如,对上面的查询,如果创建索引idx_age_name (age, name),则无需回表:CREATE INDEX idx_age_name ON user (age, name);1使用主键查询
如果直接通过主键查询(如WHERE id = 1),直接访问聚集索引,无需回表。减少 SELECT 的字段
只查询索引中包含的字段,例如只查age:SELECT age FROM user WHERE age = 25; -- 无需回表1
# 总结
| 场景 | 是否需要回表 | 优化方法 |
|---|---|---|
| 查询字段在索引中 | 否 | 使用覆盖索引 |
| 查询字段不在索引中 | 是 | 优化索引或调整查询字段 |
回表是数据库查询优化的关键点之一,理解其原理有助于设计更高效的索引和 SQL 语句。
# 2. redis 使用,集群选举制度
Redis 集群的选举制度(故障转移机制)是其实现高可用性的核心,并非基于 Raft 算法,而是使用一套自研的、基于 Gossip 协议和投票的机制。以下是其核心流程和要点:
# 1. 触发条件:主节点确认失效 (FAIL)
- 集群中的每个节点通过 Gossip 协议定期交换信息。
- 当某个主节点(Master A)被集群中大多数主节点 (N/2 + 1) 标记为
PFAIL(疑似下线)并在一定时间(通常是cluster-node-timeout * 2)内未恢复,这些主节点会将其状态升级为FAIL(确认下线)。
# 2. 从节点竞选资格
- 只有 Master A 的从节点 (Slaves) 有资格参与竞选新主节点。
- 从节点必须满足复制偏移量要求(拥有最新或足够新的数据),才被允许发起选举。
# 3. 从节点发起选举请求 (FAILOVER_AUTH_REQUEST)
- 有资格的从节点不会立即发起请求。它们会等待一个延迟时间 (DELAY):
DELAY = 500ms + random(0 ~ 500ms) + (1000ms - slave-priority * 100ms)slave-priority是从节点配置文件中的参数(默认 100)。优先级越高(数值越小),等待延迟越短,越能更快发起投票请求。
- 等待结束后,从节点向集群中的所有主节点广播一条
FAILOVER_AUTH_REQUEST消息,请求投票。
# 4. 主节点投票 (FAILOVER_AUTH_ACK)
- 收到请求的主节点(不包括从节点)根据以下规则决定是否投票:
- 规则 1:已失效主节点状态: 本节点必须也认为 Master A 是
FAIL状态。 - 规则 2:未投过票: 在当前的
currentEpoch内,本节点尚未对 Master A 的槽位故障转移投过票(每个主节点在一个配置纪元内对同一槽故障转移只能投一次票)。 - 规则 3:请求时效性: 请求在合理的竞选期内(通常也是
cluster-node-timeout * 2)收到。
- 规则 1:已失效主节点状态: 本节点必须也认为 Master A 是
- 如果所有规则都满足,主节点会立刻给第一个收到的合法
FAILOVER_AUTH_REQUEST发送FAILOVER_AUTH_ACK投票响应。投票决策是“先到先得”,不比较不同从节点的优先级或数据新旧。
# 5. 赢得选举
- 发起请求的从节点开始收集
FAILOVER_AUTH_ACK投票。
- 如果在
2 * cluster-node-timeout时间内,收到了大多数主节点 (N/2 + 1) 的投票,则该从节点赢得选举。 N是集群中负责处理槽位 (hash slots) 的主节点总数。
# 6. 从节点晋升与配置更新
- 赢得选举的从节点:
- 将自身提升为新的主节点 (New Master)。
- 接管原主节点 Master A 负责的所有哈希槽 (hash slots)。
- 向整个集群广播一条
PONG消息,通知其他节点自己角色的变化和负责的新槽位信息。
- 其他节点收到
PONG后更新本地集群配置信息。 - 新主节点开始处理写入请求,它的从节点(如果有)开始从它同步数据。
# 关键总结与区别
- 不是 Raft: 使用自研的 Gossip+投票机制,非 Raft。
- 选举发起者: 失效主节点的从节点发起,不是任意节点。
- 投票者: 集群中所有主节点投票,从节点不投票。
- 投票规则:
- 主节点基于 FAIL 状态确认、未投过票、请求时效性 三个硬性条件判断。
- “先到先得”:满足条件的主节点投给第一个收到的合法请求。不比较不同从节点的优先级 (
slave-priority) 或复制偏移量。
- 优先级的作用:
slave-priority仅影响从节点发起投票请求的延迟时间(优先级越高,等待时间越短,越可能先发出请求),不影响主节点的投票决策。 - 赢得条件: 获得 大多数主节点 (N/2 + 1) 的投票。
N是负责槽的主节点数。 - 数据一致性基础: 从节点的竞选资格要求(复制偏移量)确保了新主节点拥有足够新的数据。
这套机制设计目标是快速、简单、高效地在主节点失效时从它的从节点中选出一个新主,保证集群的可用性。其核心在于利用 Gossip 进行故障检测,利用主节点的投票(基于简单规则和先到先得)快速达成多数派共识。
# 3. WSGI 实现了什么
WSGI(Web Server Gateway Interface)是 Python Web 应用程序和 Web 服务器之间的一种统一接口标准。它定义了 Web 服务器如何与 Python 应用程序进行通信,以便处理 HTTP 请求和响应。
通过实现 WSGI,Python Web 框架和 Web 服务器可以实现解耦,使得可以在不同的框架和服务器之间自由切换和组合。WSGI 接口规定了两个主要的组件:
应用程序:即 Python Web 应用程序,它是一个可调用的对象或函数,它接收一个字典作为参数,包含了 HTTP 请求的环境变量和其他相关信息,并返回一个包含 HTTP 响应的可迭代对象。
接收两个参数:
environ:一个包含 HTTP 请求信息的字典(由 Web 服务器提供),包含如请求方法、URL、环境变量等。start_response:一个回调函数,用于发送 HTTP 状态码和响应头,必须由应用程序调用。
返回一个可迭代对象:
该对象包含响应的主体内容(如 HTML 页面),通常是一个字符串列表。
服务器:是一个符合 WSGI 协议的 Web 服务器,它负责接收 HTTP 请求,并将请求转发给应用程序进行处理,最后将应用程序返回的响应发送回客户端。
通过 WSGI 的实现,Web 服务器可以与各种不同的 Python Web 框架进行交互,例如 Django、Flask、Tornado 等,而且相同的应用程序也可以在不同的 Web 服务器上运行,提供更大的灵活性和可扩展性。
总结来说,WSGI 实现了 Python Web 应用程序与 Web 服务器之间的统一接口,使得不同的应用程序和服务器可以更加灵活地组合和切换,提高了 Python Web 开发的可移植性和可扩展性。
# 4. web.py、flask、django 技术选型为什么倾向于选用 flask,(面试官倾向于选择 Django)
# 事务
# flask 运行机制
# 基类,在哪看到过
# 脑裂是什么
在计算机领域,“脑裂”(Brain Split)是分布式系统中一种严重的故障场景,通常发生在多节点集群中。当集群节点间的通信链路出现异常,导致部分节点无法与其他节点通信时,集群会被分割成多个独立的“子集群”,每个子集群都认为自己是“主集群”,从而引发数据不一致、服务异常等问题。以下是关于计算机领域脑裂的详细解析:
# 一、脑裂的核心成因与场景
# 1. 通信故障
- 网络分区:节点间的网络链路因硬件故障(如交换机故障)、网络拥塞、防火墙策略错误等导致通信中断,形成多个无法互通的网络分区。
- 心跳机制失效:集群通过“心跳检测”(如周期性发送 ping 包)确认节点存活,若心跳信号丢失,节点会误认为其他节点“失效”。
# 2. 典型场景
- 分布式数据库/存储集群(如 MySQL 主从集群、MongoDB 副本集):多个节点争夺“主节点”身份,导致数据写入冲突。
- 分布式协调服务(如 ZooKeeper、etcd):节点间无法达成共识,导致服务注册与发现异常。
- 容器编排系统(如 Kubernetes):控制平面节点分裂,导致 Pod 调度混乱或服务中断。
# 二、脑裂的危害
# 1. 数据不一致
- 若多个子集群同时接收写请求(如双主节点同时写入数据),会导致数据冲突。例如:MySQL 主从集群脑裂后,两个“主节点”分别写入数据,恢复通信时会因数据不一致引发错误。
# 2. 服务不可用或异常
- 子集群各自处理请求,可能导致部分用户访问到旧数据或服务无响应。例如:分布式缓存集群脑裂后,不同客户端可能读取到不同版本的数据。
# 3. 资源浪费与冲突
- 多个子集群可能重复占用资源(如 IP 地址、端口、存储资源),甚至导致“脑裂漂移”(节点在不同子集群间频繁切换),加剧系统不稳定。
# 三、常见解决方案
# 1. 增加仲裁机制(Quorum)
- 多数投票原则:集群决策需超过半数节点同意(如 MongoDB 副本集要求多数节点存活才能选举主节点),避免小规模子集群获得控制权。
- 引入仲裁节点:通过独立的“仲裁者”(如 ZooKeeper 的 Observer 节点、etcd 的仲裁节点)判断哪个子集群合法,仲裁节点不存储数据,仅参与投票。
# 2. 优化心跳与超时机制
- 多级心跳检测:同时使用 TCP 心跳、应用层心跳(如数据库协议心跳),减少误判。
- 动态调整超时时间:根据网络状况自动调整心跳超时阈值,避免因短暂网络波动触发脑裂。
# 3. 资源独占策略
- fencing 机制(隔离):通过硬件或软件手段确保只有一个子集群能操作关键资源。例如:存储集群中,脑裂发生时,非仲裁子集群的节点被“物理隔离”(如通过电源管理强制下线)。
- 分布式锁机制:使用分布式锁(如 ZooKeeper 的临时顺序节点)确保同一时间只有一个主节点处理写请求。
# 4. 数据一致性保障
- 强一致性协议:采用 Raft、Paxos 等共识算法,确保所有写操作必须经多数节点确认,避免脑裂时的数据冲突。
- 读写分离与冲突检测:读请求可分发至多个子集群,但写请求仅允许主集群处理,脑裂恢复后自动同步冲突数据。
# 四、典型案例与实践
# 1. MySQL MHA(Master High Availability)
- 通过检测主节点故障并触发自动切换,同时利用“二次确认”机制(检查主节点是否真的失效),减少脑裂误判。
# 2. Kubernetes 的脑裂防护
- 控制平面节点通过 etcd 集群实现共识,要求至少半数节点存活才能维持集群正常运作;节点失联超时时,自动将 Pod 从故障节点驱逐。
# 3. MongoDB 副本集
- 配置“投票节点数”为奇数(如 3 个或 5 个),确保脑裂时只有包含多数投票节点的子集群能成为主集群,避免双主问题。
# 五、总结
脑裂是分布式系统设计中必须规避的核心风险,其本质是“分布式共识失效”。通过引入仲裁机制、优化通信协议、强化数据一致性策略,可有效降低脑裂发生的概率及影响。在实际架构中,需根据业务场景选择合适的解决方案(如金融场景优先采用强一致性+仲裁,而互联网场景可结合最终一致性+快速恢复策略),确保集群在异常情况下仍能稳定运行。
# dict 的实现
- python 源码分析:dict 对象的实现 - 木易小邪 - 博客园 (opens new window)
- Python dictionary implementation – Laurent Luce's Blog (opens new window)
# celery 实际推荐使用 rabbitMQ,为什么
redis 不是一个真正的消息队列,我们只是把 list 当作消息队列来使用,而 rabbitMQ 实现了消息队列中的更多功能。
具体来说:
- 可靠性:
- RabbitMQ 是一个可靠的消息队列系统,它使用 AMQP(Advanced Message Queuing Protocol)作为消息传递协议,提供了丰富的功能和机制来确保消息的可靠传递。它使用持久化存储消息,即使在 RabbitMQ 服务器重新启动后也能保证消息的不丢失。
- Redis 作为一个内存数据库,在消息代理方面相对简单,对于持久化和可靠性的支持较弱。在 Redis 的默认配置下,如果 Redis 服务器重启,未被消费的消息将会丢失,可能会影响系统的稳定性和可靠性。
- 灵活性和扩展性:
- RabbitMQ 提供了强大的消息路由和交换机机制,可以根据实际需求定制复杂的消息流程。它支持多种消息模式,如发布/订阅、工作队列、RPC 等,能够满足各种复杂的消息处理场景。
- Redis 在消息代理方面的功能相对简单,主要用作一个简单的消息队列,不如 RabbitMQ 的灵活性和扩展性。
- 可管理性:
- RabbitMQ 提供了丰富的管理工具和接口,可以很方便地监控、管理和配置消息队列系统。它提供了 Web 界面、CLI 工具和 RESTful API 等多种管理方式,使得运维人员可以更好地管理和监控系统。
- Redis 的管理功能相对较弱,虽然也提供了一些基本的管理命令和工具,但对于复杂的消息队列管理需求而言,可能较为不足。
综上所述,尽管 Redis 作为一种内存数据库也可以用作 Celery 的消息代理,但在实际生产中,由于 RabbitMQ 具有更强的可靠性、灵活性和可管理性,以及更适合复杂消息队列处理的特点,更推荐将 RabbitMQ 作为 Celery 的消息代理。
# 二面
# 1. nginx 配置,字段含义 $host,还有哪些关键字
在 nginx 配置中,$host是一个内置变量,它指代客户端请求中的 Host 头部字段的值。host 变量的值按照如下优先级获得:
- 请求行中的 host;
- 请求头中的 Host 头部;
- 与一条请求匹配的 server name
除了$host,nginx 还有许多其他的关键字和变量,其中一些常用的关键字包括:
1. $uri:请求的URI(不包括查询参数)
2. $args:请求的查询参数
3. $request_method:请求的HTTP方法,如GET、POST等
4. $remote_addr:客户端的IP地址
5. $server_name:当前服务器的名称
6. $request_uri:完整的请求URI(包括查询参数)
7. $http_user_agent:客户端的User-Agent头部字段的值
8. $http_referer:客户端的Referer头部字段的值
9. $http_cookie:客户端的Cookie头部字段的值
10. $http_x_forwarded_for:客户端的X-Forwarded-For头部字段的值
2
3
4
5
6
7
8
9
10
这些关键字和变量可以在 nginx 配置文件中的任何地方使用,例如在 location 块、if 语句中等,以便根据需要进行条件判断、重定向、日志记录等操作。
Nginx Cheatsheet (opens new window) Nginx 配置文件中的关键字是什么?详细解释来了-简易百科 (opens new window)
# 2. iteritems,items 区别
在 Python 2 中,iteritems()和items()是字典对象的两个方法,用于返回字典中的键值对。它们的区别在于返回的对象类型和性能。
iteritems()方法返回一个迭代器对象,该迭代器逐个返回字典中的键值对。这种方法在处理大型字典时效率更高,因为它不会立即生成一个完整的列表,而是按需生成每个键值对。这在节省内存和提高性能方面非常有用。items()方法返回一个包含所有键值对的列表。这种方法会立即生成并返回一个完整的列表对象。这在小型字典上使用效果更好,因为它可以一次性返回所有的键值对。# python2 >>> a = {'a':1,'b':2} >>> b = a.iteritems() >>> type(b) <type 'dictionary-itemiterator'> >>> next(b) ('a', 1)1
2
3
4
5
6
7在 Python 3 中,
iteritems()方法已被删除,只保留了items()方法,它返回一个视图对象,可以用于遍历字典中的键值对。这种视图对象在遍历时动态地反映了字典的变化。In [1]: a = {'a':1,'b':2} In [2]: b = a.items() In [3]: type(b) Out[3]: dict_items In [4]: next(b) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-4-adb3e17b0219> in <module> ----> 1 next(b) TypeError: 'dict_items' object is not an iterator In [6]: c = iter(b) In [7]: next(c) Out[7]: ('a', 1)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 3. 多线程多进程编程?进程通信方式,queue 无法跳出,遇到过吗,如何解决的
如果在进程通信中使用队列(queue)时无法跳出,可能是由于以下几个原因:
队列中没有数据:在使用队列进行进程通信时,如果发送方没有往队列中放入数据,接收方将会一直等待队列中有数据才能取出。因此,可以检查一下是否确保在发送方向队列中放入了数据。
队列中的数据无法被取出:在使用队列进行进程通信时,如果接收方无法取出队列中的数据,可能是由于接收方的代码逻辑有误。可以检查一下接收方的代码,确保正确地使用了队列的取出操作。
在使用 Queue 的时候,如果使用的默认的 get 后者 put 方法,(即(block=True, timeout=None))不管是多线程,还是多进程,在从队列中取出 url 的时候一定要加上判定条件,while queue.qsize()!=0 或者 while not queue.empty(),不然进程或者线程会一直等待。
ref: Python 多进程使用 Queue 后卡死问题解决方案_python 进程池传 queue 卡死_kikilover 的博客-CSDN 博客 (opens new window)
# 4. 数据库索引优化举例
# 5. Python 底层加速
在 Python 开发中,底层加速通常指通过优化代码执行效率或利用底层语言(如 C/C++)提升性能。以下是 Python 底层加速的核心方法、工具和场景,结合具体示例说明:
# 一、Python 性能瓶颈的根源
- 解释性语言特性:逐行解释执行,动态类型检查。
- 全局解释器锁(GIL):限制多线程并行执行 CPU 密集型任务。
- 内存管理开销:对象引用计数和垃圾回收机制。
# 二、底层加速的核心方法
# 1. 使用高性能库替代原生代码
- 适用场景:数值计算、数据处理。
- 工具示例:
NumPy:基于 C 的数组操作,向量化计算。
import numpy as np # 原生 Python 列表求和 sum_list = sum([i for i in range(1000000)]) # 慢 # NumPy 向量化求和 sum_np = np.arange(1000000).sum() # 快 100 倍1
2
3
4
5Pandas:高效处理结构化数据。
SciPy:科学计算优化。
# 2. C 扩展与 Cython
- 适用场景:关键代码段(如循环、数学计算)的极致优化。
- 实现方式:
Cython:将 Python 代码编译为 C 扩展。
# cython_example.pyx def cython_sum(int n): cdef int i, total = 0 for i in range(n): total += i return total1
2
3
4
5
6编译后调用:
import pyximport; pyximport.install() from cython_example import cython_sum print(cython_sum(1000000)) # 比原生 Python 快 50 倍1
2
3手写 C 扩展:通过 Python C API 编写模块(复杂但灵活)。
# 3. 即时编译(JIT)
工具:Numba(基于 LLVM,适合数值计算)。
from numba import jit @jit(nopython=True) def numba_sum(n): total = 0 for i in range(n): total += i return total print(numba_sum(1000000)) # 接近 C 的速度1
2
3
4
5
6
7
8
9
10适用场景:科学计算、高频调用的函数。
# 4. 多进程与并行计算
解决 GIL 限制:利用多进程(
multiprocessing)或分布式计算。from multiprocessing import Pool def process_chunk(data): # 处理数据块 return sum(data) data = [list(range(1000))] * 1000 with Pool(4) as p: results = p.map(process_chunk, data) # 4 进程并行1
2
3
4
5
6
7
8
9框架:Dask、Ray(分布式任务调度)。
# 5. 异步编程
- 适用场景:IO 密集型任务(如网络请求、文件读写)。
- 工具:
asyncio、aiohttp。
import aiohttp
import asyncio
async def fetch(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
urls = ["http://example.com"] * 10
loop = asyncio.get_event_loop()
results = loop.run_until_complete(asyncio.gather(*[fetch(url) for url in urls]))
2
3
4
5
6
7
8
9
10
11
# 6. 调用底层库(cffi、ctypes)
- 直接调用 C 代码:
from cffi import FFI
ffi = FFI()
ffi.cdef("int add(int a, int b);")
lib = ffi.dlopen("./libadd.so") # 加载编译好的 C 库
print(lib.add(2, 3)) # 调用 C 函数
2
3
4
5
6
# 四、性能分析工具
- 代码级分析:
cProfile:统计函数调用时间和频率。
python -m cProfile -s time my_script.py
line_profiler:逐行分析代码耗时。
@profile
def slow_function():
# 被分析的函数
2
3
- 内存分析:
tracemalloc:跟踪内存分配。memory_profiler:逐行分析内存使用。
# 五、总结
| 方法 | 适用场景 | 性能提升 | 复杂度 |
|---|---|---|---|
| NumPy/Pandas | 数值计算、数据处理 | 高 | 低 |
| Cython | 关键循环、数学运算 | 极高 | 中 |
| Numba | 科学计算、JIT 优化 | 高 | 低 |
| 多进程 | CPU 密集型任务 | 高 | 中 |
| 异步编程 | IO 密集型任务(网络/文件) | 高 | 高 |
| C 扩展 | 极致性能需求 | 极高 | 高 |
实战建议:
- 优先使用高性能库(如 NumPy)和 JIT(Numba)。
- 对瓶颈代码针对性优化(先用
cProfile定位)。 - 复杂场景结合多进程/异步提升整体吞吐量。
内存不足杀死进程如何调试?
Python 内存泄漏问题定位分析索引无效的情况都有哪些?
索引无效的情况有以下几种:
索引列没有被包含在查询条件中:如果查询条件没有使用到索引列,那么索引就无效,查询会扫描全表而不是使用索引。
索引列上使用了函数或表达式:如果在索引列上使用了函数或表达式,那么索引就无效,查询会扫描全表而不是使用索引。
索引列上存在类型转换:如果在索引列上进行了类型转换,那么索引就无效,查询会扫描全表而不是使用索引。
索引列上存在大量重复值:如果索引列上存在大量重复值,那么索引的选择性就很低,查询优化器可能会选择全表扫描而不是使用索引。
索引列上数据分布不均匀:如果索引列上的数据分布不均匀,即某些值出现的频率很高,而其他值出现的频率很低,那么索引的选择性就很低,查询优化器可能会选择全表扫描而不是使用索引。
索引列上存在大量更新操作:如果索引列上存在大量的更新操作,那么频繁的更新操作可能会导致索引的维护成本过高,查询优化器可能会选择全表扫描而不是使用索引。
需要注意的是,以上情况并不是绝对的,查询优化器会根据具体情况来选择使用索引还是全表扫描。
线上 linux 查看问题点的命令?
netstat、top、lsof -i 、ps
各个 web 框架的区别或者优缺点?
Web.py:
- 简单、轻量级的框架,适合小型项目或快速原型开发。
- 没有内置的 ORM(对象关系映射)工具,需要手动处理数据库操作。
- 灵活性高,可以自由选择组件和库。
- 性能较好,因为它没有过多的抽象层。
Django:
- 全功能的框架,适合中大型项目开发。
- 内置了强大的 ORM 工具,简化了数据库操作。
- 提供了许多内置的功能模块和插件,如认证、管理后台等。
- 学习曲线较陡峭,配置复杂,但一旦熟悉,可以提高开发效率。
Flask:
- 简洁、灵活的框架,适合小型项目或快速原型开发。
- 与 Django 相比,学习曲线较平缓,配置相对简单。
- 没有内置的 ORM 工具,但可以与其他 ORM 库集成。
- 可扩展性强,可以根据项目需求选择需要的插件和库。
总结:
- Web.py 是一个轻量级的框架,适合小型项目或快速原型开发。
- Django 是一个全功能的框架,适合中大型项目开发。
- Flask 是一个简洁、灵活的框架,适合小型项目或快速原型开发。 选择适合自己项目需求的框架,可以提高开发效率和便利性。
# 集简慧通
- left join 与 right join

left join:顾名思义,就是“左连接”,表 1 左连接表 2,以左为主,表示以表 1 为主,关联上表 2 的数据,查出来的结果显示左边的所有数据,然后右边显示的是和左边有交集部分的数据。
right join:“右连接”,表 1 右连接表 2,以右为主,表示以表 2 为主,关联查询表 1 的数据,查出表 2 所有数据以及表 1 和表 2 有交集的数据。
join:其实就是“inner join”,为了简写才写成 join,两个是表示一个的,内连接,表示以两个表的交集为主,查出来是两个表有交集的部分,其余没有关联就不额外显示出来,这个用的情况也是挺多的。
- Django 的生命周期
Django 的生命周期指的是 Django 应用程序的运行过程中,各个组件的创建、初始化、处理请求、返回响应以及销毁的过程。下面是 Django 应用程序的典型生命周期:
启动 Django:在启动 Django 时,会加载项目的配置文件和各个应用程序的设置,并创建 Django 的应用程序实例。
URL 解析:当接收到一个 HTTP 请求时,Django 会根据 URL 配置文件中的规则来解析请求的 URL,找到匹配的视图函数或视图类。
视图处理:Django 调用匹配的视图函数或视图类来处理请求。在这个阶段,Django 可能会执行一些预处理的操作,例如身份验证、权限检查等,同时涉及到对 Model 进行处理。
模板渲染:如果视图函数或视图类需要使用模板来生成响应内容,Django 会根据指定的模板文件和上下文数据来渲染模板,并生成最终的响应内容。
响应返回:Django 将生成的响应内容返回给客户端,并关闭与客户端的连接。
清理资源:在请求处理完毕后,Django 会进行一些清理操作,例如关闭数据库连接、释放内存等。
销毁应用程序:当 Django 应用程序关闭时(例如服务器关闭或重启),Django 会执行一些最终的清理操作,并销毁应用程序实例。
需要注意的是,Django 的生命周期是循环的,即每次接收到一个 HTTP 请求,都会经历上述的生命周期过程。
- 静态方法和类方法的区别
静态方法使用@staticmethod 装饰器,不接受类或者示例参数,无法访问或修改实例或者类的属性和方法;类方法使用@classmethod 装饰,接受的第一个参数为 cls,可以访问类对象或属性,并进行修改。
- MySQL B+树索引和哈希索引的区别
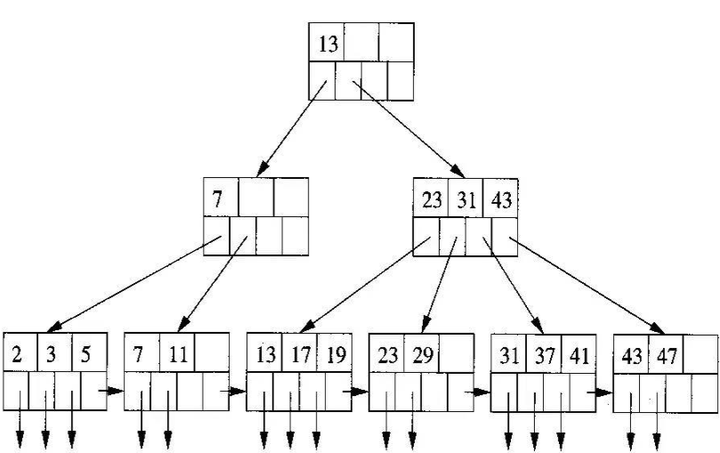
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过 1,而且同层级的节点间有指针相互链接。
在 B+树上的常规检索,从根节点到叶子节点的搜索效率基本相当,不会出现大幅波动,而且基于索引的顺序扫描时,也可以利用双向指针快速左右移动,效率非常高。
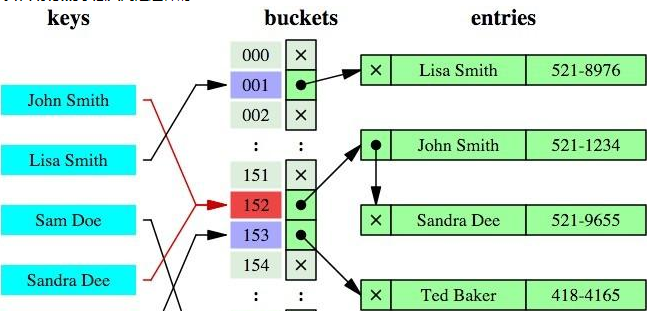
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似 B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值;当然了,这个前提是,键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到相应的数据;
从示意图中也能看到,如果是范围查询检索,哈希索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索;
同理,哈希索引也没办法利用索引完成排序,以及 like "xxx%" 这样的部分模糊查询(这种部分模糊查询,其实本质上也是范围查询);
哈希索引也不支持多列联合索引的最左匹配规则;
B+树索引的关键字检索效率比较平均,不像 B 树那样波动幅度大,在有大量重复键值情况下,哈希索引的效率也是极低的,因为存在所谓的哈希碰撞问题。
MySQL 中的 B+树索引和哈希索引是两种常见的索引类型,它们在实现原理和适用场景上有一些区别。
实现原理:
- B+树索引:B+树是一种平衡树的数据结构,它将索引的键值按照一定的规则组织成树形结构,可以在 O(logN)的时间复杂度内进行查找、插入和删除操作。
- 哈希索引:哈希索引使用哈希函数将索引的键值映射为一个固定长度的哈希值,然后将哈希值作为索引进行查找。哈希索引的查找速度非常快,通常可以在 O(1)的时间复杂度内完成。
适用场景:
- B+树索引:适用于范围查询、排序和分组等操作,可以高效地支持任意范围的查找。B+树索引适合于有序的、有重复值的数据集。
- 哈希索引:适用于等值查询,即通过精确的条件查找数据。哈希索引不支持范围查询,因为哈希函数的特性决定了哈希索引中的键值是无序的。
存储空间:
- B+树索引:B+树索引需要占用一定的存储空间来存储索引的节点和键值,随着数据量的增加,索引的大小也会增加。
- 哈希索引:哈希索引需要占用较小的存储空间,因为哈希值的长度是固定的,不随数据量的增加而增加。
内存使用:
- B+树索引:B+树索引可以利用操作系统的缓存机制,将热点数据存储在内存中,提高查询性能。
- 哈希索引:哈希索引需要将全部索引数据加载到内存中,如果数据量过大,可能会导致内存不足的问题。
综上所述,B+树索引适用于范围查询和有序数据集,而哈希索引适用于等值查询和较小的数据集。在选择索引类型时,需要根据具体的业务需求和数据特点进行选择。
- 主键索引和唯一索引的区别
- 主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。
- 主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。
- 唯一性索引列允许空值,而主键列不允许为空值。
- 主键可以被其他表引用为外键,而唯一索引不能。
- 一个表最多只能创建一个主键,但可以创建多个唯一索引。
- 主键索引和普通索引的区别
主键索引和普通索引是数据库中常见的两种索引类型,它们的区别主要体现在以下几个方面:
唯一性:主键索引要求索引列的值是唯一的,即每个索引值只能对应一条记录,而普通索引则允许索引列的值重复。
空值:主键索引不允许存在空值,即索引列的值不能为空,而普通索引可以包含空值。
表现形式:主键索引可以是聚集索引(clustered index)或非聚集索引(non-clustered index),而普通索引只能是非聚集索引。
存储方式:主键索引的存储方式与数据行的存储方式相同,即主键索引和数据行存储在同一位置,而普通索引则是独立存储的。在 MySQL 中,主键索引的叶子节点存储的是整个数据行的值,而普通索引的叶子节点存储的是索引字段的值和对应的主键值。
查询性能:主键索引的查询性能通常比普通索引更高,因为主键索引的唯一性和聚集性可以减少磁盘 I/O 的次数,提高查询效率。
总的来说,主键索引是一种特殊的索引类型,用于唯一标识一条记录,具有唯一性和非空性的特点;而普通索引是一种常见的索引类型,用于提高查询性能,可以包含重复值和空值。
__new__和__init__区别
- Python 传值还是传引用
- Python 是否支持重载
不支持,但是也不影响。因为 Python 可以处理这种问题。 python-中重载
- 闭包
- 迭代器与生成器
- 下划线和双下划线的区别
Python 中没有真正的私有属性,但是可以用这种方式来表示私有;但是单下划线可以强制导入,而双下划线只能通过_ClassName__var来获取。
# 龙创悦动
- token 的工作机制
在后端开发中,Token 是一种用于身份验证和授权的安全机制,常见于前后端分离、分布式系统或微服务架构中。以下是其核心工作机制的详细解析,适合面试场景的结构化回答:
# 一、Token 的核心类型(常见场景)
- JWT(JSON Web Token)
最常用的无状态令牌,适用于单点登录(SSO)和微服务架构。
- 结构:由 Header(头部)、Payload(载荷)、Signature(签名) 三部分组成,通过
.分隔,Base64 编码后传输。 - 特点:无状态(后端无需存储会话)、自包含(载荷携带用户信息)、可自定义过期时间(
exp字段)。
- OAuth 2.0 中的 Access Token
用于授权第三方应用访问资源(如微信登录、GitHub 授权),常配合 Refresh Token 刷新有效期。
# 二、Token 的工作流程(以 JWT 为例)
# 1. 令牌生成(登录阶段)
用户通过前端提交用户名/密码等凭证。
后端接收到请求后,验证凭证合法性(如查询数据库对比密码)。
验证通过后,生成 JWT:
- Header:指定签名算法(如
HS256、RS256)和令牌类型(JWT)。 - Payload:包含用户标识(如
user_id)、角色(role)、过期时间(exp,如60分钟)等非敏感信息。 - Signature:通过 密钥(Secret) 对 Header 和 Payload 进行签名(防止令牌被篡改)。
- Header:指定签名算法(如
示例代码(伪代码):
import jwt from datetime import datetime, timedelta payload = { "user_id": "123", "role": "user", "exp": datetime.utcnow() + timedelta(minutes=30) } token = jwt.encode(payload, secret_key, algorithm="HS256")1
2
3
4
5
6
7
8
9后端将生成的
token返回给前端(通常通过 HTTP 响应体或Set-Cookie头)。
# 2. 令牌传输(前端存储)
前端接收
token后,需选择安全的存储方式:- Cookie:设置
HttpOnly(防 XSS)和Secure(仅 HTTPS 传输)属性,适合 CSRF 场景。 - LocalStorage/SessionStorage:需配合前端框架(如 Vue/React)手动在请求头中携带,但存在 XSS 风险。
- Cookie:设置
每次前端发起请求时,需在 请求头 中携带
token:Authorization: Bearer <token>1
# 3. 令牌验证(后端校验)
后端接收到请求后,从
Authorization头中提取token。解析并验证令牌:
- 验证签名是否匹配(确保未被篡改)。
- 检查
exp字段是否未过期。 - 校验通过后,从 Payload 中提取用户信息(如
user_id),用于后续权限判断(如访问控制、路由权限)。
示例代码(伪代码):
try: payload = jwt.decode(token, secret_key, algorithms=["HS256"]) user_id = payload["user_id"] # 执行后续业务逻辑 except jwt.ExpiredSignatureError: return "Token 已过期", 401 except jwt.InvalidTokenError: return "无效的 Token", 4011
2
3
4
5
6
7
8
# 4. 令牌刷新(处理过期)
- 问题:JWT 过期后需重新登录,体验较差。
- 解决方案:使用 Refresh Token(长有效期令牌,存储于安全位置如 HttpOnly Cookie):
- 登录时同时返回
Access Token(短有效期,如 30 分钟)和Refresh Token(长有效期,如 7 天)。 - 当
Access Token过期时,前端用Refresh Token向后端请求新的Access Token。 - 后端验证
Refresh Token有效后,生成新的Access Token返回,同时可刷新Refresh Token以防泄漏。
- 登录时同时返回
# 三、关键安全机制
- 密钥安全
- 签名密钥(Secret)必须严格保密,存储于环境变量或安全配置中心(如 AWS Secrets Manager),禁止硬编码。
- 对于 `RS256` 等非对称算法,私钥需仅由后端持有,公钥可公开用于验证。
- 防止令牌泄漏
- 避免在日志、URL 中暴露 `token`。
- 前端存储 `token` 时,优先使用 `HttpOnly Cookie`(防 XSS),避免使用 `LocalStorage`(易被 XSS 窃取)。
- 令牌撤销(应对泄漏)
- JWT 无状态,无法直接撤销已签发的令牌。
- 解决方案:
- **黑名单/白名单**:将泄漏的令牌存入 Redis 等缓存,设置过期时间,验证时检查是否在黑名单中。
- 缩短 `Access Token` 有效期,配合 `Refresh Token` 降低风险。
- CSRF 防护
- 若使用 `Cookie` 存储 `token`,需配合 `SameSite` 属性(设置为 `Strict/Lax`)和 `CSRF Token` 双校验。
# 四、对比传统 Session-Cookie 机制
| 维度 | Token(JWT) | Session-Cookie |
|---|---|---|
| 存储位置 | 前端(无状态) | 后端(内存/数据库) |
| 扩展性 | 适合分布式、微服务 | 需共享会话(如 Redis 集群) |
| 跨域支持 | 方便(只需在请求头携带) | 依赖 Cookie 同源策略 |
| 安全性 | 依赖密钥和前端存储安全 | 需防范 CSRF,后端存储有成本 |
# 五、面试高频问题
JWT 为什么适合微服务?
无状态,后端无需共享会话存储,各服务可独立验证令牌,降低架构复杂度。如何解决 JWT 无法主动失效的问题?
使用黑名单(缓存泄漏令牌)或缩短有效期,配合Refresh Token机制。Payload 中能否存储敏感数据?
不能。Payload 会被 Base64 解码(非加密),仅应存放必要的非敏感信息(如用户 ID、角色)。
# 总结
Token 的工作机制核心是 “登录生成令牌 → 前端携带令牌 → 后端验证授权”,通过无状态设计提升扩展性,同时依赖密钥安全、有效期管理和刷新机制保障安全性。面试中需结合具体场景(如 JWT/OAuth),清晰阐述流程、安全措施及与传统方案的对比。 2. 索引、事务/innoDB 和 MyISAM 的对比
事务:一个最小的不可再分的工作单元
- web 框架的对比
# 大地量子
- range 返回的对象类型
Python3 range() 函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表。
Python3 list() 函数是对象迭代器,可以把range()返回的可迭代对象转为一个列表,返回的变量类型为列表。
python2 中xrange返回惰性可迭代对象,可以遍历而不消耗,类型为 range对象,而不是迭代器,无法使用next取值!有len方法
- python 版本问题(py2 与 py3 对比)
- 一行打印乘法口诀表
print('\n'.join(['\t'.join(f'{j} * {i} = {i*j}' for j in range(1,i+1)) for i in range(1,10)]))
列表生成式
聚集索引的概念,每页数据为什么是 16k,可以是 32k 吗?可以使用 uuid 作为聚簇索引的主键吗?
聚集索引是一种特殊的数据库索引,在聚集索引中,数据按照索引的顺序存储,因此聚集索引决定了数据在磁盘上的物理排列方式。
每页数据 16k 是因为数据库管理系统(DBMS)在处理数据时,将数据分成固定大小的块,称为页面(page)。16k 是一种常见的页面大小,它是经过优化和平衡后的一个折衷选择。较小的页面大小可能会导致额外的磁盘 IO 操作,而较大的页面大小可能会浪费存储空间。因此,16k 被广泛应用于许多数据库系统。
虽然理论上可以使用 32k 作为页面大小,但是这种情况很少见。较大的页面大小可能会导致内存利用率下降,增加 IO 操作的开销,并且可能导致数据碎片化。
提示
可以把页面大小的设计类比成一本书的纸张大小。页面太大,会降低书本的便携性;而页面太小,则会导致每页存储的有效信息太少,所以常见书本以 16 开或 32 开为主。
可以使用 UUID 作为聚簇索引的主键,但是通常不建议这样做。UUID 是一个全局唯一的标识符,它的值是随机生成的。将 UUID 作为聚簇索引的主键会导致数据在磁盘上的随机分布,增加了插入和更新操作的开销,并且可能导致数据碎片化。在大规模的数据库系统中,通常会选择使用自增主键作为聚簇索引的主键,以提高性能和减少碎片化的可能性。
增加 page_size 的大小:如改为 32k,64k。数据库的页块大小改变需要改动源码。
- 聚集索引的非顺序插入问题
聚集索引不是物理上连续的,而是逻辑上连续的。(面试官怎么问这个问题的记不住了,好像是说先插入主键为 1,3,4,之后插入 2 是否可以插入?)
聚集索引是按照索引列的值进行物理排序的,它决定了数据在磁盘上的存储顺序。当你插入主键 id 为 1、2、4 的数据后,聚集索引会按照主键 id 的值进行排序,数据会按照 1、2、4 的顺序存储在磁盘上。
因此,你可以在插入主键 id 为 3 的数据,数据库会根据聚集索引的顺序将其插入到正确的位置,使得数据仍然保持有序。
在 MySQL 中,无论是按照顺序插入还是非顺序插入,只要主键是唯一的,就可以成功插入。但在实际应用中,这两种插入方式可能会有以下区别:
插入效率:如果是 InnoDB 存储引擎,主键是聚簇索引,数据记录是按照主键顺序存储的。如果按照主键顺序插入,数据页分裂的可能性会小一些,插入效率可能会高一些。如果是非顺序插入,可能会引起更多的数据页分裂,插入效率可能会低一些。
数据查询效率:如果数据是按照主键顺序插入的,查询效率可能会更高,因为数据物理存储的顺序和主键的顺序一致,可以更好地利用磁盘的顺序读取特性。
空间使用:如果是非顺序插入,可能会导致数据页的利用率不高,占用更多的存储空间。
但这些区别在实际应用中可能并不明显,具体情况还需要根据实际的数据量、数据分布、查询模式等因素来考虑。
以下是一个基于 MySQL InnoDB 引擎的简单示例,通过对比顺序插入和非顺序插入,说明聚集索引如何影响数据物理存储位置:
# 一、表结构与索引定义
CREATE TABLE students (
id INT PRIMARY KEY, -- 聚集索引(物理存储按id排序)
name VARCHAR(50),
age INT
) ENGINE=InnoDB;
2
3
4
5
- 聚集索引:以
id字段作为主键,数据行在磁盘上按id值的顺序物理存储。
# 二、场景 1:顺序插入数据(无物理位置调整)
# 插入语句
INSERT INTO students (id, name, age) VALUES
(1, 'Alice', 18),
(2, 'Bob', 19),
(3, 'Charlie', 20);
2
3
4
# 物理存储示意图(简化版)
| 磁盘页 1(物理顺序) | 数据行 |
|---|---|
| 位置 1 | id=1, name=Alice, age=18 |
| 位置 2 | id=2, name=Bob, age=19 |
| 位置 3 | id=3, name=Charlie, age=20 |
# 特点
- 新数据直接追加到当前数据页末尾,无需移动已有数据,插入效率高。
# 三、场景 2:非顺序插入数据(触发物理位置调整)
# 插入语句
-- 插入id=0(小于现有最小id=1)
INSERT INTO students (id, name, age) VALUES (0, 'Zero', 17);
2
# 物理存储调整过程
- 定位插入位置:根据聚集索引(id)的顺序,新数据应插入到
id=1之前。 - 数据页空间不足时的处理:
- 若当前数据页(页 1)剩余空间足够容纳
id=0,则将后续数据(id=1,2,3)向后移动,腾出位置插入id=0。 - 若空间不足,触发页分裂(Page Split):
- 创建新数据页(页 2)。
- 将部分数据(如
id=2,3)移动到页 2。 - 在页 1 插入
id=0,保持页内数据有序。
# 调整后的物理存储示意图
| 磁盘页 1 | 磁盘页 2 |
|---|---|
| id=0, name=Zero, age=17 | id=2, name=Bob, age=19 |
| id=1, name=Alice, age=18 | id=3, name=Charlie, age=20 |
# 关键开销
- 数据移动:已有数据需向后偏移,消耗 CPU 和 I/O。
- 页分裂:产生碎片,降低磁盘利用率,影响后续查询性能。
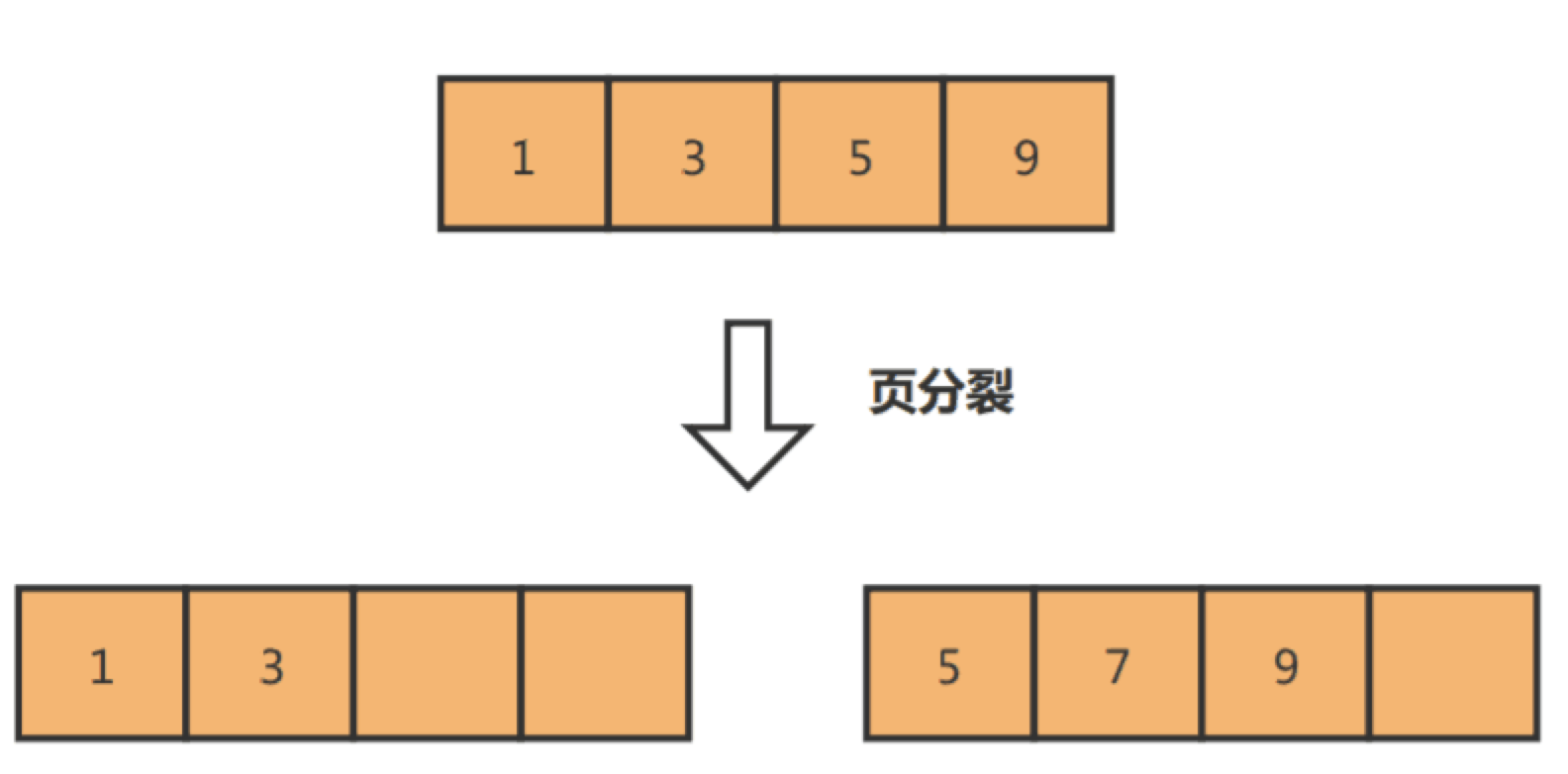
页分裂
页分裂是指当一个数据页存储的数据满时,需要将其分裂成两个数据页来存储更多的数据。 在数据库中,数据是按照数据页的形式存储的,每页可以存储 16KB 的数据(默认)。当一页数据满了之后,如果需要继续存储更多的数据,就会导致数据页的分裂。页分裂会导致索引树的混乱,使得一部分数据在老页面,一部分在新的页面,并且新页面可能被分配到任何可用的页,这样就会影响数据库查询的性能。
# 四、为什么自增主键是推荐实践
# 示例:自增主键顺序插入
-- 自增主键场景(假设id为AUTO_INCREMENT)
INSERT INTO students (name, age) VALUES
('David', 21), -- id=4(自动生成,按顺序插入)
('Eve', 22); -- id=5
2
3
4
# 物理存储示意图
| 磁盘页 1 | 磁盘页 2 | 磁盘页 3 |
|---|---|---|
| id=0,1,2,3 | id=4,5 | ... |
# 优势
- 新数据始终追加到最后一个数据页末尾,无需移动已有数据,避免页分裂。
- 聚集索引 B+树保持高效的顺序插入,提升写入性能。
# 五、总结:聚集索引插入的核心逻辑
- 物理顺序依赖:聚集索引的数据行按索引键值顺序存储在磁盘,插入非顺序值时需调整位置。
- 性能影响:
- 顺序插入(如自增主键):效率高,无数据移动。
- 非顺序插入(如随机 UUID):可能触发页分裂,导致写入性能下降和索引碎片化。
- 最佳实践:
- 优先使用自增整数作为聚集索引(如`AUTO_INCREMENT`)。
- 避免使用 UUID、随机字符串等作为主键。
- 事务四大特性,之间是否存在关联?
事务四大特性是指原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
这四个特性之间存在一定的关联。
原子性和一致性:原子性指事务中的操作要么全部成功执行,要么全部不执行,不会出现部分执行的情况。一致性指事务执行前后数据库的状态要保持一致。原子性和一致性是相互关联的,如果事务中的操作是原子性的,即要么全部成功执行,要么全部不执行,那么事务执行前后数据库的状态就能保持一致。
隔离性和一致性:隔离性指并发执行的事务之间是相互隔离的,每个事务都感觉不到其他事务的存在。一致性指事务执行前后数据库的状态要保持一致。隔离性和一致性是相互关联的,如果事务之间是相互隔离的,互不干扰,那么事务执行前后数据库的状态就能保持一致。
持久性和一致性:持久性指事务一旦提交,其结果就是永久性的,即使系统发生故障也不会丢失。一致性指事务执行前后数据库的状态要保持一致。持久性和一致性是相互关联的,如果事务一旦提交,其结果是永久性的,即使系统发生故障,也能保持事务执行前后数据库的状态一致。
综上所述,事务四大特性之间存在关联,彼此相互支持和保证数据库的一致性。
- innoDB 和 MyISAM 的对比
InnoDB 引擎的四大特性是:
事务支持:InnoDB 引擎支持 ACID(原子性、一致性、隔离性和持久性)事务,可以确保数据的完整性和一致性。它支持提交(commit)和回滚(rollback)操作,可以保证在多个并发事务处理过程中的数据一致性。
行级锁定:InnoDB 引擎支持行级锁定,这意味着在同一时间可以对不同的行进行并发操作,提高了并发性能。与其他引擎如 MyISAM 相比,InnoDB 引擎的行级锁定能够减少锁冲突,提高并发性能。
外键约束:InnoDB 引擎支持外键约束,可以定义表与表之间的关系,保证数据的引用完整性。外键约束可以自动检查和维护数据的完整性,避免了数据不一致的问题。
高可靠性及快速恢复数据:InnoDB 引擎具有高可靠性,支持数据的持久性存储和恢复。它使用 redo log 和 undo log 来记录和恢复数据的更改,可以在系统崩溃或断电后恢复数据的一致性。此外,InnoDB 引擎还支持自动崩溃恢复和自动故障切换,提高了数据库的稳定性和可靠性。
生成器取元素的方式,除了 next 还有哪些?
除了使用 next 方法取出生成器的下一个元素之外,还可以使用以下方法:
- 使用
for循环:可以直接在for循环中迭代生成器,自动调用next方法取出元素,直到生成器耗尽或达到停止条件。
for item in generator:
# 处理元素
2
- 使用
list函数:可以将生成器转换为列表,通过一次性调用list函数获取生成器的所有元素。
elements = list(generator)
- 使用
iter函数:可以将生成器转换为迭代器对象,然后使用iter函数的__next__方法取出元素。
iterator = iter(generator)
element = iterator.__next__()
2
- 使用
*运算符:可以将生成器的所有元素解包到一个列表中。
elements = [*generator]
需要注意的是,生成器是一种惰性计算的机制,只有在需要时才会生成元素。因此,每次取出元素时都会从生成器中消耗一个元素,直到生成器耗尽。如果生成器已经耗尽,再次调用 next 方法会引发 StopIteration 异常。
- 新式类和经典类
# py2
class Py2Old:
pass
class Py2New(object):
pass
#py3
class Py3New:
pass
2
3
4
5
6
7
8
9
10
- 垃圾回收机制
gc.get_threshold()
(700, 10, 10)
2
700 代表新创建的对象减去从新创建的对象中回收的数量的差值大于 700 就进行一次 0 代回收当 0 代回收进行 10 次的时候就进行一代回收(并且一代回收的时候也进行 0 代回收),同理,当一代回收进行 10 次的时候就进行 2 代回收(并且二代回收的时候也进行 0 代回收和一代回收)
# 众趣科技
三次握手,四次挥手
索引的原理
顺序访问指针,所以查询快
怎么分析慢查询?
explain 查询是否为全表扫描,是的话加索引
最左匹配原则?
MySQL 索引的最左匹配原则是指,在使用联合索引时,可以利用索引的最左边的列来进行查询,但是如果查询中没有使用到索引的最左边的列,那么该索引将不会被使用。
举个例子,假设有一个联合索引(col1, col2, col3),如果查询语句中只使用了 col2 和 col3 进行筛选,而没有使用 col1,那么该索引将不会被使用。因为 MySQL 的索引是按照索引列的顺序来存储和搜索的,如果查询中没有使用到索引的最左边的列,那么 MySQL 无法利用该索引进行快速搜索。
需要注意的是,最左匹配原则并不是说只能使用联合索引的最左边的列进行查询,而是指如果查询语句中没有使用到索引的最左边的列,那么该索引将不会被使用。也就是说,如果查询中使用了索引的最左边的列,那么 MySQL 可以利用该索引进行搜索,但是如果查询中没有使用到索引的最左边的列,那么该索引将不会被使用。
最左匹配原则在设计索引时非常重要,可以根据查询的特点来选择合适的索引列顺序,以提高查询性能。
乐观锁、悲观锁?
乐观锁和悲观锁是数据库中常用的并发控制机制。
乐观锁(Optimistic Locking)是一种乐观的并发控制策略。在乐观锁机制中,假设不会发生并发冲突,因此在读取数据的时候不会加锁,只有在更新数据的时候才会检查是否有其他事务修改了数据。乐观锁通常使用版本号或时间戳来实现。当一个事务要更新数据时,会先读取数据并记录版本号或时间戳,然后在更新时检查是否有其他事务修改了数据,如果有则回滚操作,重新读取数据并重新尝试更新。
悲观锁(Pessimistic Locking)是一种悲观的并发控制策略。在悲观锁机制中,假设会发生并发冲突,因此在读取数据的时候会加锁,确保其他事务无法修改数据。悲观锁通常使用行级锁或表级锁来实现。当一个事务要读取数据时,会先加锁,其他事务无法修改数据,直到该事务释放锁。这种机制可以防止并发冲突,但也会导致并发性能下降。
乐观锁适用于读操作较多的场景,因为读操作不会加锁,可以提高并发性能。悲观锁适用于写操作较多的场景,因为写操作需要加锁保证数据的一致性。选择乐观锁还是悲观锁取决于具体的业务需求和并发情况。
当涉及到实现乐观锁和悲观锁时,具体的实现方式会根据数据库的类型和使用的框架而有所不同。以下是一个使用 Python 和 MySQL 数据库的示例代码:
- 乐观锁的实现:
import pymysql def update_data(id, new_value, version): conn = pymysql.connect(host='localhost', user='root', password='password', db='test') cursor = conn.cursor() try: # 表中需要有版本号字段 cursor.execute("SELECT value, version FROM data WHERE id = %s", (id,)) row = cursor.fetchone() if row: current_value, current_version = row if current_version == version: cursor.execute("UPDATE data SET value = %s, version = version + 1 WHERE id = %s", (new_value, id)) conn.commit() print("Update successful!") else: print("Conflict detected! Retry the operation.") else: print("Data not found!") except Exception as e: print("Error:", e) conn.rollback() finally: cursor.close() conn.close()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26在上述代码中,首先通过
SELECT语句获取要更新的数据的当前值和版本号。然后,检查当前版本号是否与传入的版本号相同。如果相同,则执行UPDATE语句更新数据并增加版本号。如果版本号不相同,则说明有其他事务修改了数据,需要重新尝试更新。- 悲观锁的实现:
import pymysql def update_data(id, new_value): conn = pymysql.connect(host='localhost', user='root', password='password', db='test') cursor = conn.cursor() try: cursor.execute("SELECT * FROM data WHERE id = %s FOR UPDATE", (id,)) row = cursor.fetchone() if row: cursor.execute("UPDATE data SET value = %s WHERE id = %s", (new_value, id)) conn.commit() print("Update successful!") else: print("Data not found!") except Exception as e: print("Error:", e) conn.rollback() finally: cursor.close() conn.close()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21在上述代码中,通过
SELECT ... FOR UPDATE语句获取要更新的数据并加锁,确保其他事务无法修改数据。然后,执行UPDATE语句更新数据,并提交事务。需要注意的是,上述代码仅为示例,实际实现中需要根据具体的业务需求和数据库类型进行相应的调整。
深拷贝,浅拷贝?
gRPC 工作原理?
多态解释一下?
A 类中的 walk 和 b 类中的 walk 方法可以接受不同类型的参数,但执行的逻辑不一样。 面向对象之封装、继承、多态 | 别院牧志知识库
WSGI 与 ASGI
什么是 WSGI
先说一下CGI,(通用网关接口, Common Gateway Interface/CGI),定义客户端与 Web 服务器的交流方式的一个程序。例如正常情况下客户端发来一个请求,根据HTTP协议 Web 服务器将请求内容解析出来,经过计算后,再将内容封装好,例如服务器返回一个HTML页面,并且根据HTTP协议构建返回内容的响应格式。涉及到TCP连接、HTTP原始请求和相应格式的这些,都由一个软件来完成,这时,以上的工作需要一个程序来完成,而这个程序便是CGI。
那什么是WSGI呢?维基 (opens new window) 上的解释为,Web 服务器网关接口(Python Web Server Gateway Interface,WSGI),是为Python语言定义的 Web 服务器和 Web 应用程序或框架之间的一种简单而通用的接口。从语义上理解,貌似WSGI就是Python为了解决Web 服务器端与客户端之间的通信问题而产生的,并且WSGI是基于现存的CGI标准而设计的,同样是一种程序(或者Web组件的接口规范)。
WSGI (opens new window) 区分为两部分:一种为“服务器”或“网关”,另一种为“应用程序”或“应用框架”。
所谓的WSGI中间件同时实现了API的两方,即在WSGI服务器和WSGI应用之间起调解作用:从WSGI服务器的角度来说,中间件扮演应用程序,而从应用程序的角度来说,中间件扮演服务器。中间件具有的功能:
- 重写环境变量后,根据目标 URL,将请求消息路由到不同的应用对象。
- 允许在一个进程中同时运行多个应用程序或应用框架。
- 负载均衡和远程处理,通过在网络上转发请求和相应消息。
- 进行内容后处理,例如应用
XSLT样式表。
可以说WSGI就是基于Python的以CGI为标准做一些扩展。
异步网关协议接口,一个介于网络协议服务和Python应用之间的标准接口,能够处理多种通用的协议类型,包括HTTP,HTTP2和WebSocket。
然而目前的常用的WSGI主要是针对HTTP风格的请求响应模型做的设计,并且越来越多的不遵循这种模式的协议逐渐成为Web编程的标准之一,例如WebSocket。
ASGI尝试保持在一个简单的应用接口的前提下,提供允许数据能够在任意的时候、被任意应用进程发送和接受的抽象。并且同样描述了一个新的,兼容HTTP请求响应以及WebSocket数据帧的序列格式。允许这些协议能通过网络或本地socket进行传输,以及让不同的协议被分配到不同的进程中。
- WSGI 和 ASGI 的区别在哪
以上,WSGI是基于HTTP协议模式的,不支持WebSocket,而ASGI的诞生则是为了解决Python常用的WSGI不支持当前Web开发中的一些新的协议标准。同时,ASGI对于WSGI原有的模式的支持和WebSocket的扩展,即ASGI是WSGI的扩展。
ref:WSGI&ASGI - 简书 (opens new window)
redis 缓存热点数据,哪些数据属于热点数据
Redis 的过期策略有两种:定期删除和惰性删除。
定期删除: Redis 默认使用的是定期删除策略。它会以一定的频率(默认每秒钟 10 次)随机抽取一部分设置了过期时间的 key,并检查它们是否过期,如果过期则删除。这种策略的优点是简单高效,缺点是可能会造成大量过期 key 未被及时删除,占用过多内存。
惰性删除: 惰性删除是指在获取某个 key 时,Redis 会先检查该 key 是否过期,如果过期则删除。这种策略的优点是能够及时删除过期 key,节省内存空间,缺点是在获取过期 key 时会有一定的性能损耗。
Redis 还提供了一些配置参数来调整过期策略的行为,包括:
maxmemory-policy:指定内存达到上限时的淘汰策略,默认是 noeviction,表示不淘汰数据,直接返回错误。
redis的淘汰策略:默认是 noeviction noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错; allkeys-lru:尝试回收,最近未使用或者使用比较少的键。(范围是:所有的键) volatile-lru:尝试回收,最近未使用或者使用比较少的键。(范围是:设置了过期时间的键) allkeys-random:随机移除某个key。(范围是:所有的键) volatile-random:随机移除某个key。(范围是:设置了过期时间的键) volatile-ttl:回收过期时间较短的key。(范围是:设置了过期时间的键)1
2
3
4
5
6
7maxmemory-samples:指定定期删除策略每次抽取的 key 数量,默认是 5。
lazyfree-lazy-eviction:是否开启惰性删除策略,默认是 no,表示关闭。
根据实际需求,可以根据以上配置参数来调整 Redis 的过期策略。
# 其他
已经有了 GIL 多线程为什么还要加锁?
尽管 GIL(全局解释器锁)可以确保在同一时间只有一个线程在 Python 解释器中执行,但在多线程环境中,由于线程的切换和竞争条件的存在,仍然需要使用锁来保护共享资源的访问。
以下是为什么在使用 GIL 的情况下仍然需要加锁的几个原因:
保护共享资源:在多线程环境中,多个线程可能同时访问和修改共享资源,如全局变量、共享数据结构等。为了避免数据的不一致性和竞争条件,需要使用锁来保护共享资源,确保在任何时刻只能有一个线程访问或修改它。
原子操作:某些操作需要保证原子性,即在多线程环境中不会被中断。例如,对于一个整型变量的自增操作,在多线程环境中可能出现竞争条件,导致结果不准确。通过使用锁可以确保这样的操作在同一时刻只能由一个线程执行,保证结果的正确性。
避免数据竞争:数据竞争指的是多个线程同时访问和修改同一块内存区域,导致不可预测的结果。GIL 只能保证在同一时间只有一个线程在解释器中执行,但不能保证线程之间的执行顺序。使用锁可以控制线程的执行顺序,避免数据竞争的问题。
需要注意的是,GIL 只是针对 Python 解释器级别的多线程,对于涉及到 I/O 操作、调用 C 扩展等情况,GIL 会主动释放,允许其他线程执行。因此,在这些情况下,使用锁仍然是必要的。
float相加精度问题在计算机中,浮点数的精度问题是由于浮点数的二进制表示和十进制表示之间的转换造成的。由于浮点数的二进制表示是有限的,所以在进行浮点数的加法运算时,可能会出现精度丢失的情况。
例如,考虑以下代码:
a = 0.1 b = 0.2 c = a + b print(c)1
2
3
4预期输出应该是 0.3,但实际上输出是 0.30000000000000004。
这是因为 0.1 和 0.2 在二进制表示中是无限循环的,而计算机的浮点数表示只能存储有限的位数,所以在进行加法运算时会出现舍入误差,导致最终的结果不准确。
为了解决这个问题,可以使用 Decimal 模块进行精确的浮点数计算。例如:
from decimal import Decimal a = Decimal('0.1') b = Decimal('0.2') c = a + b print(c)1
2
3
4
5
6这样就可以得到精确的结果 0.3。
另外,还可以使用 round 函数来对浮点数进行四舍五入处理,以减少精度误差。例如:
a = 0.1 b = 0.2 c = round(a + b, 1) print(c)1
2
3
4这样就可以得到结果 0.3。 参阅 聊一聊 0.1+0.2=0.30000000000000004 这件事 (opens new window)
为什么协程比线程快?切换为什么快?
协程比线程快的原因主要有两点:
协程的切换是用户级的,而线程的切换是内核级的。线程的切换需要操作系统的介入,涉及到用户态和内核态之间的切换,需要保存和恢复线程的上下文,开销较大。而协程的切换是在用户代码中完成的,不需要操作系统的介入,切换的开销较小。
协程的切换是协作式的,而线程的切换是抢占式的。线程的切换是由操作系统的调度器决定的,可能在任何时候发生。而协程的切换是由程序员显式地控制的,只会在协程主动让出执行权时发生。这种协作式的切换可以更好地控制资源的使用和调度,避免了线程切换时的竞争和冲突。
总的来说,协程的切换快是因为它的切换开销小且可控。这使得协程在处理大量的轻量级任务时更加高效,并且可以更好地利用计算资源。
futures模块- 多进程里面的单进程和单进程消耗的资源哪个更多还是一样多?
- 设计模式
- redis 缓存使用?io 模型?多路复用解释一下?数据结构内部实现?
Redis 缓存使用:
- 将常用的数据存储在 Redis 中,通过缓存提高读取数据的速度。
- 在查询数据时,先从 Redis 中查询,如果存在则直接返回,如果不存在再从数据库中查询,并将查询结果存储到 Redis 中,方便下次查询。
- 在更新数据时,先更新数据库中的数据,再删除 Redis 中的缓存,确保数据的一致性。
Redis 的 I/O 模型是使用了多路复用来实现非阻塞 I/O。
Redis 可以使用多种 I/O 模型,包括 epoll、select、kqueue 等。在 Linux 系统上,Redis 默认使用 epoll 作为其 I/O 模型。
通过多路复用,Redis 可以同时监听多个文件描述符(sockets),当某个文件描述符有事件发生时,Redis 会将其加入到一个就绪队列中,然后通过事件处理器来处理就绪的文件描述符。
在每个事件循环中,Redis 会通过事件处理器来处理就绪的文件描述符,执行相应的操作。这样可以在不阻塞的情况下处理多个连接,提高了 Redis 的并发性能。
总的来说,Redis 的 I/O 模型使用多路复用来实现非阻塞 I/O,从而提高了并发性能。
多路复用: 多路复用是指通过一种机制,使得一个进程可以同时监听多个文件描述符,一旦某个文件描述符就绪(可读、可写或异常等事件就绪),就能够通知应用程序进行相应的操作。
多路复用的实现方式有多种,常见的有:
- select:通过 select 系统调用来监听多个文件描述符,一旦有就绪的文件描述符,就返回并通知应用程序进行相应操作。
- poll:与 select 类似,通过 poll 系统调用来监听多个文件描述符。
- epoll:是 Linux 特有的多路复用机制,通过 epoll 系统调用来监听多个文件描述符,性能更好。
数据结构内部实现: Redis 内部使用了一些数据结构来存储数据,主要包括字符串、哈希表、列表、集合和有序集合。
- 字符串:Redis 的字符串是动态字符串,通过 SDS(Simple Dynamic String)实现,支持动态扩容和惰性释放内存。
- 哈希表:Redis 的哈希表是字典,使用链地址法解决哈希冲突,支持动态扩容,底层实现为数组+链表/跳表。
- 列表:Redis 的列表是双向链表,支持在表头和表尾进行操作,底层实现为双向链表。
- 集合:Redis 的集合是无序的字符串集合,底层使用哈希表实现。
- 有序集合:Redis 的有序集合是有序的字符串集合,底层使用跳表和哈希表实现,通过跳表实现有序性,通过哈希表实现快速查找。
这些数据结构的内部实现都使用了一些优化技巧,如压缩列表、跳表等,来提高性能和减少内存占用。