 客户端 / 服务器应用程序
客户端 / 服务器应用程序
多连接的客户端和服务端程序版本与最早的原始版本相比肯定有了很大的改善,但是让我们再进一步地解决上面「多连接」版本中的不足,然后完成最终版的实现:客户端 / 服务器应用程序
我们希望有个客户端和服务端在不影响其它连接的情况下做好错误处理,显然,如果没有发生异常,我们的客户端和服务端不能崩溃的一团糟。这也是到现在为止我们还没讨论的东西,我故意没有引入错误处理机制因为这样可以使之前的程序容易理解
现在你对基本的 API,非阻塞 socket、select() 等概念已经有所了解了。我们可以继续添加一些错误处理同时讨论下「房间里面的大象 (opens new window)」的问题,我把一些东西隐藏在了幕后。你应该还记得,我在介绍中讨论到的自定义类
首先,让我们先解决错误:
所有的错误都会触发异常,像无效参数类型和内存不足的常见异常可以被抛出;从 Python 3.3 开始,与 socket 或地址语义相关的错误会引发 OSError 或其子类之一的异常 引用 (opens new window)
我们需要捕获 OSError 异常。另外一个我没提及的的问题是延迟,你将在文档的很多地方看见关于延迟的讨论,延迟会发生而且属于「正常」错误。主机或者路由器重启、交换机端口出错、电缆出问题或者被拔出,你应该在你的代码中处理好各种各样的错误
刚才说的「房间里面的大象」问题是怎么回事呢。就像 socket.SOCK_STREAM 这个参数的字面意思一样,当使用 TCP 连接时,你会从一个连续的字节流读取的数据,好比从磁盘上读取数据,不同的是你是从网络读取字节流
然而,和使用 f.seek() 读文件不同,换句话说,没法定位 socket 的数据流的位置,如果可以像文件一样定位数据流的位置(使用下标),那你就可以随意的读取你想要的数据
当字节流入你的 socket 时,会需要有不同的网络缓冲区,如果想读取他们就必须先保存到其它地方,使用 recv() 方法持续的从 socket 上读取可用的字节流
相当于你从 socket 中读取的是一块一块的数据,你必须使用 recv() 方法不断的从缓冲区中读取数据,直到你的应用确定读取到了足够的数据
什么时候算「足够」这取决于你的定义,就 TCP socket 而言,它只通过网络发送或接收原始字节。它并不了解这些原始字节的含义
这可以让我们定义一个应用层协议,什么是应用层协议?简单来说,你的应用会发送或者接收消息,这些消息其实就是你的应用程序的协议
换句话说,这些消息的长度、格式可以定义应用程序的语义和行为,这和我们之前说的从 socket 中读取字节部分内容相关,当你使用 recv() 来读取字节的时候,你需要知道读的字节数,并且决定什么时候算读取完成
这些都是怎么完成的呢?一个方法是只读取固定长度的消息,如果它们的长度总是一样的话,这样做很容易。当你收到固定长度字节消息的时候,就能确定它是个完整的消息
然而,如果你使用定长模式来发送比较短的消息会比较低效,因为你还得处理填充剩余的部分,此外,你还得处理数据不适合放在一个定长消息里面的情况
在这个教程里面,我们将使用一个通用的方案,很多协议都会用到它,包括 HTTP。我们将在每条消息前面追加一个头信息,头信息中包括消息的长度和其它我们需要的字段。这样做的话我们只需要追踪头信息,当我们读到头信息时,就可以查到消息的长度并且读出所有字节然后消费它
我们将通过使用一个自定义类来实现接收文本 / 二进制数据。你可以在此基础上做出改进或者通过继承这个类来扩展你的应用程序。重要的是你将看到一个例子实现它的过程
我将会提到一些关于 socket 和字节相关的东西,就像之前讨论过的。当你通过 socket 来发送或者接收数据时,其实你发送或者接收到的是原始字节
如果你收到数据并且想让它在一个多字节解释的上下文中使用,比如说 4-byte 的整形,你需要考虑它可能是一种不是你机器 CPU 本机的格式。客户端或者服务器的另外一头可能是另外一种使用了不同的字节序列的 CPU,这样的话,你就得把它们转换成你主机的本地字节序列来使用
上面所说的字节顺序就是 CPU 的 字节序 (opens new window),在引用部分的字节序 一节可以查看更多。我们将会利用 Unicode 字符集的优点来规避这个问题,并使用 UTF-8 的方式编码,由于 UTF-8 使用了 8 字节 编码方式,所以就不会有字节序列的问题
你可以查看 Python 关于编码与 Unicode 的 文档 (opens new window),注意我们只会编码消息的头部。我们将使用严格的类型,发送的消息编码格式会在头信息中定义。这将让我们可以传输我们觉得有用的任意类型 / 格式数据
你可以通过调用 sys.byteorder 来决定你的机器的字节序列,比如在我的英特尔笔记本上,运行下面的代码就可以:
$ python3 -c 'import sys; print(repr(sys.byteorder))'
'little'
2
如果我把这段代码跑在可以模拟大字节序 CPU「PowerPC」的虚拟机上的话,应该是下面的结果:
$ python3 -c 'import sys; print(repr(sys.byteorder))'
'big'
2
在我们的例子程序中,应用层的协议定义了使用 UTF-8 方式编码的 Unicode 字符。对于真正传输消息来说,如果需要的话你还是得手动交换字节序列
这取决于你的应用,是否需要它来处理不同终端间的多字节二进制数据,你可以通过添加额外的头信息来让你的客户端或者服务端支持二进制,像 HTTP 一样,把头信息作为参数传进去
不用担心自己还没搞懂上面的东西,下面一节我们看到是如果实现的
# 应用的协议头
让我们来定义一个完整的协议头:
- 可变长度的文本
- 基于 UTF-8 编码的 Unicode 字符集
- 使用 JSON 序列化的一个 Python 字典
其中必须具有的头应该有以下几个:
| 名称 | 描述 |
|---|---|
| byteorder | 机器的字节序列(uses sys.byteorder),应用程序可能用不上 |
| content-length | 内容的字节长度 |
| content-type | 内容的类型,比如 text/json 或者 binary/my-binary-type |
| content-encoding | 内容的编码类型,比如 utf-8 编码的 Unicode 文本,二进制数据 |
这些头信息告诉接收者消息数据,这样的话你就可以通过提供给接收者足够的信息让他接收到数据的时候正确的解码的方式向它发送任何数据,由于头信息是字典格式,你可以随意向头信息中添加键值对
# 发送应用程序消息
不过还有一个问题,由于我们使用了变长的头信息,虽然方便扩展但是当你使用 recv() 方法读取消息的时候怎么知道头信息的长度呢
我们前面讲到过使用 recv() 接收数据和如何确定是否接收完成,我说过定长的头可能会很低效,的确如此。但是我们将使用一个比较小的 2 字节定长的头信息前缀来表示头信息的长度
你可以认为这是一种混合的发送消息的实现方法,我们通过发送头信息长度来引导接收者,方便他们解析消息体
为了给你更好地解释消息格式,让我们来看看消息的全貌:
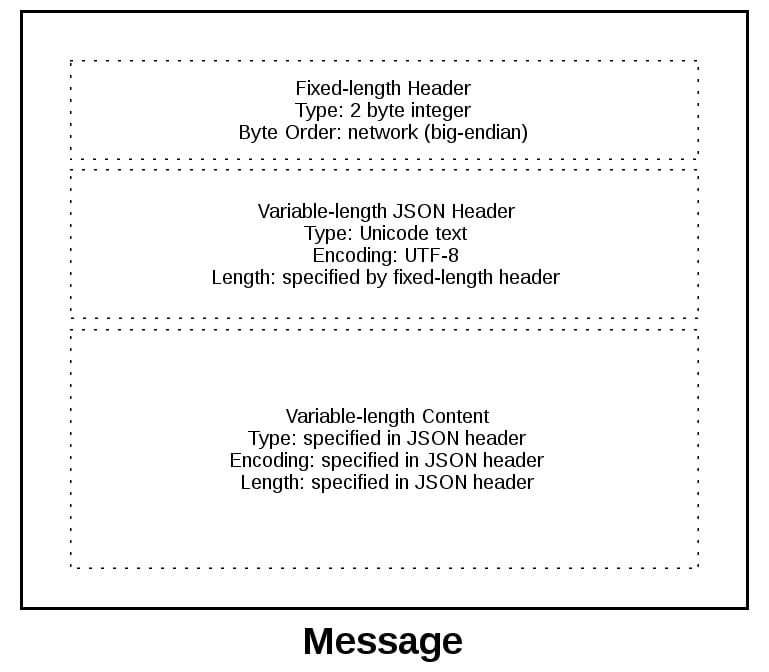
消息以 2 字节的固定长度的头开始,这两个字节是整型的网络字节序列,表示下面的变长 JSON 头信息的长度,当我们从 recv() 方法读取到 2 个字节时就知道它表示的是头信息长度的整形数字,然后在解码 JSON 头之前读取这么多的字节
JSON 头包含了头信息的字典。其中一个就是 content-length,这表示消息内容的数量(不是 JSON 头),当我们使用 recv() 方法读取到了 content-length 个字节的数据时,就表示接收完成并且读取到了完整的消息
# 应用程序消息类
最后让我们来看下成果,我们使用了一个消息类。来看看它是如何在 socket 发生读写事件时与 select() 配合使用的
对于这个示例应用程序而言,我必须想出客户端和服务器将使用什么类型的消息,从这一点来讲这远远超过了最早时候我们写的那个玩具一样的打印程序
为了保证程序简单而且仍然能够演示出它是如何在一个真正的程序中工作的,我创建了一个应用程序协议用来实现基本的搜索功能。客户端发送一个搜索请求,服务器做一次匹配的查找,如果客户端的请求没法被识别成搜索请求,服务器就会假定这个是二进制请求,对应的返回二进制响应
跟着下面一节,运行示例、用代码做实验后你将会知道他是如何工作的,然后你就可以以这个消息类为起点把他修改成适合自己使用的
就像我们之前讨论的,你将在下面看到,处理 socket 时需要保存状态。通过使用类,我们可以将所有的状态、数据和代码打包到一个地方。当连接开始或者接受的时候消息类就会为每个 socket 创建一个实例
类中的很多包装方法、工具方法在客户端和服务端上都是差不多的。它们以下划线开头,就像 Message._json_encode() 一样,这些方法通过类使用起来很简单。这使得它们在其它方法中调用时更短,而且符合 DRY (opens new window) 原则
消息类的服务端程序本质上和客户端一样。不同的是客户端初始化连接并发送请求消息,随后要处理服务端返回的内容。而服务端则是等待连接请求,处理客户端的请求消息,随后发送响应消息
看起来就像这样:
| 步骤 | 端 | 动作 / 消息内容 |
|---|---|---|
| 1 | 客户端 | 发送带有请求内容的消息 |
| 2 | 服务端 | 接收并处理请求消息 |
| 3 | 服务端 | 发送有响应内容的消息 |
| 4 | 客户端 | 接收并处理响应消息 |
下面是代码的结构:
| 应用程序 | 文件 | 代码 |
|---|---|---|
| 服务端 | app-server.py | 服务端主程序 |
| 服务端 | libserver.py | 服务端消息类 |
| 客户端 | app-client.py | 客户端主程序 |
| 客户端 | libclient.py | 客户端消息类 |
# 消息入口点
我想通过首先提到它的设计方面来讨论 Message 类的工作方式,不过这对我来说并不是立马就能解释清楚的,只有在重构它至少五次之后我才能达到它目前的状态。为什么呢?因为要管理状态
当消息对象创建的时候,它就被一个使用 selector.register() 事件监控起来的 socket 关联起来了
message = libserver.Message(sel, conn, addr)
sel.register(conn, selectors.EVENT_READ, data=message)
2
注意,这一节中的一些代码来自服务端主程序与消息类,但是这部分内容的讨论在客户端也是一样的,我将在他们之间存在不同点的时候来解释客户端的版本
当 socket 上的事件就绪的时候,它就会被 selector.select() 方法返回。对过 key 对象的 data 属性获取到 message 的引用,然后在消息用调用一个方法:
while True:
events = sel.select(timeout=None)
for key, mask in events:
# ...
message = key.data
message.process_events(mask)
2
3
4
5
6
观察上面的事件循环,可以看见 sel.select() 位于「司机位置」,它是阻塞的,在循环的上面等待。当 socket 上的读写事件就绪时,它就会为其服务。这表示间接的它也要负责调用 process_events() 方法。这就是我说 process_events() 方法是入口的原因
让我们来看下 process_events() 方法做了什么
def process_events(self, mask):
if mask & selectors.EVENT_READ:
self.read()
if mask & selectors.EVENT_WRITE:
self.write()
2
3
4
5
这样做很好,因为 process_events() 方法很简洁,它只可以做两件事情:调用 read() 和 write() 方法
这又把我们带回了状态管理的问题。在几次重构后,我决定如果别的方法依赖于状态变量里面的某个确定值,那么它们就只应该从 read() 和 write() 方法中调用,这将使处理 socket 事件的逻辑尽量的简单
可能说起来很简单,但是经历了前面几次类的迭代:混合了一些方法,检查当前状态、依赖于其它值、在 read() 或者 write() 方法外面调用处理数据的方法,最后这证明了这样管理起来很复杂
当然,你肯定需要把类按你自己的需求修改使它能够符合你的预期,但是我建议你尽可能把状态检查、依赖状态的调用的逻辑放在 read() 和 write() 方法里面
让我们来看看 read() 方法,这是服务端版本,但是客户端也是一样的。不同之处在于方法名称,一个(客户端)是 process_response() 另一个(服务端)是 process_request()
def read(self):
self._read()
if self._jsonheader_len is None:
self.process_protoheader()
if self._jsonheader_len is not None:
if self.jsonheader is None:
self.process_jsonheader()
if self.jsonheader:
if self.request is None:
self.process_request()
2
3
4
5
6
7
8
9
10
11
12
13
_read() 方法首先被调用,然后调用 socket.recv() 从 socket 读取数据并存入到接收缓冲区
记住,当调用 socket.recv() 方法时,组成消息的所有数据并没有一次性全部到达。socket.recv() 方法可能需要调用很多次,这就是为什么在调用相关方法处理数据前每次都要检查状态
当一个方法开始处理消息时,首先要检查的就是接受缓冲区保存了足够的多读取的数据,如果确定,它们将继续处理各自的数据,然后把数据存到其它流程可能会用到的变量上,并且清空自己的缓冲区。由于一个消息有三个组件,所以会有三个状态检查和处理方法的调用:
| Message Component | Method | Output |
|---|---|---|
| Fixed-length header | process_protoheader() | self._jsonheader_len |
| JSON header | process_jsonheader() | self.jsonheader |
| Content | process_request() | self.request |
接下来,让我们一起看看 write() 方法,这是服务端的版本:
def write(self):
if self.request:
if not self.response_created:
self.create_response()
self._write()
2
3
4
5
6
write() 方法会首先检测是否有请求,如果有而且响应还没被创建的话 create_response() 方法就会被调用,它会设置状态变量 response_created,然后为发送缓冲区写入响应
如果发送缓冲区有数据,write() 方法会调用 socket.send() 方法
记住,当 socket.send() 被调用时,所有发送缓冲区的数据可能还没进入到发送队列,socket 的网络缓冲区可能满了,socket.send() 可能需要重新调用,这就是为什么需要检查状态的原因,create_response() 应该只被调用一次,但是 _write() 方法需要调用多次
客户端的 write() 版大体与服务端一致:
def write(self):
if not self._request_queued:
self.queue_request()
self._write()
if self._request_queued:
if not self._send_buffer:
# Set selector to listen for read events, we're done writing.
self._set_selector_events_mask('r')
2
3
4
5
6
7
8
9
10
因为客户端首先初始化了一个连接请求到服务端,状态变量_request_queued被检查。如果请求还没加入到队列,就调用 queue_request() 方法创建一个请求写入到发送缓冲区中,同时也会使用变量 _request_queued 记录状态值防止多次调用
就像服务端一样,如果发送缓冲区有数据 _write() 方法会调用 socket.send() 方法
需要注意客户端版本的 write() 方法与服务端不同之处在于最后的请求是否加入到队列中的检查,这个我们将在客户端主程序中详细解释,原因是要告诉 selector.select()停止监控 socket 的写入事件而且我们只对读取事件感兴趣,没有办法通知套接字是可写的
我将在这一节中留下一个悬念,这一节的主要目的是解释 selector.select() 方法是如何通过 process_events() 方法调用消息类以及它是如何工作的
这一点很重要,因为 process_events() 方法在连接的生命周期中将被调用很多次,因此,要确保那些只能被调用一次的方法正常工作,这些方法中要么需要检查自己的状态变量,要么需要检查调用者的方法中的状态变量
# 服务端主程序
在服务端主程序 app-server.py 中,主机、端口参数是通过命令行传递给程序的:
$ ./app-server.py
usage: ./app-server.py <host> <port>
2
例如需求监听本地回环地址上面的 65432 端口,需要执行:
$ ./app-server.py 127.0.0.1 65432
listening on ('127.0.0.1', 65432)
2
<host> 参数为空的话就可以监听主机上的所有 IP 地址
创建完 socket 后,一个传入参数 socket.SO_REUSEADDR 的方法 to socket.setsockopt() 将被调用
# Avoid bind() exception: OSError: [Errno 48] Address already in use
lsock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
2
设置这个参数是为了避免 端口被占用 的错误发生,如果当前程序使用的端口和之前的程序使用的一样,你就会发现连接处于 TIME_WAIT 状态
比如说,如果服务器主动关闭连接,服务器会保持为大概两分钟的 TIME_WAIT 状态,具体时长取决于你的操作系统。如果你想在两分钟内再开启一个服务,你将得到一个OSError 表示 端口被战胜,这样做是为了确保一些在途的数据包正确的被处理
事件循环会捕捉所有错误,以保证服务器正常运行:
while True:
events = sel.select(timeout=None)
for key, mask in events:
if key.data is None:
accept_wrapper(key.fileobj)
else:
message = key.data
try:
message.process_events(mask)
except Exception:
print('main: error: exception for',
f'{message.addr}:\n{traceback.format_exc()}')
message.close()
2
3
4
5
6
7
8
9
10
11
12
13
当服务器接受到一个客户端连接时,消息对象就会被创建:
def accept_wrapper(sock):
conn, addr = sock.accept() # Should be ready to read
print('accepted connection from', addr)
conn.setblocking(False)
message = libserver.Message(sel, conn, addr)
sel.register(conn, selectors.EVENT_READ, data=message)
2
3
4
5
6
消息对象会通过 sel.register() 方法关联到 socket 上,而且它初始化就被设置成了只监控读事件。当请求被读取时,我们将通过监听到的写事件修改它
在服务器端采用这种方法的一个优点是,大多数情况下,当 socket 正常并且没有网络问题时,它始终是可写的
如果我们告诉 sel.register() 方法监控 EVENT_WRITE 写入事件,事件循环将会立即唤醒并通知我们这种情况,然而此时 socket 并不用唤醒调用 send() 方法。由于请求还没被处理,所以不需要发回响应。这将消耗并浪费宝贵的 CPU 周期
# 服务端消息类
在消息切入点一节中,当通过 process_events() 知道 socket 事件就绪时我们可以看到消息对象是如何发出动作的。现在让我们来看看当数据在 socket 上被读取是会发生些什么,以及为服务器就绪的消息的组件片段发生了什么
libserver.py 文件中的服务端消息类,可以在 Github 上找到 源代码 (opens new window)
这些方法按照消息处理顺序出现在类中
当服务器读取到至少两个字节时,定长头的逻辑就可以开始了
def process_protoheader(self):
hdrlen = 2
if len(self._recv_buffer) >= hdrlen:
self._jsonheader_len = struct.unpack('>H',
self._recv_buffer[:hdrlen])[0]
self._recv_buffer = self._recv_buffer[hdrlen:]
2
3
4
5
6
网络字节序列中的定长整型两字节包含了 JSON 头的长度,struct.unpack() 方法用来读取并解码,然后保存在 self._jsonheader_len 中,当这部分消息被处理完成后,就要调用 process_protoheader() 方法来删除接收缓冲区中处理过的消息
就像上面的定长头的逻辑一样,当接收缓冲区有足够的 JSON 头数据时,它也需要被处理:
def process_jsonheader(self):
hdrlen = self._jsonheader_len
if len(self._recv_buffer) >= hdrlen:
self.jsonheader = self._json_decode(self._recv_buffer[:hdrlen],
'utf-8')
self._recv_buffer = self._recv_buffer[hdrlen:]
for reqhdr in ('byteorder', 'content-length', 'content-type',
'content-encoding'):
if reqhdr not in self.jsonheader:
raise ValueError(f'Missing required header "{reqhdr}".')
2
3
4
5
6
7
8
9
10
self._json_decode() 方法用来解码并反序列化 JSON 头成一个字典。由于我们定义的 JSON 头是 utf-8 格式的,所以解码方法调用时我们写死了这个参数,结果将被存放在 self.jsonheader 中,process_jsonheader 方法做完他应该做的事情后,同样需要删除接收缓冲区中处理过的消息
接下来就是真正的消息内容,当接收缓冲区有 JSON 头中定义的 content-length 值的数量个字节时,请求就应该被处理了:
def process_request(self):
content_len = self.jsonheader['content-length']
if not len(self._recv_buffer) >= content_len:
return
data = self._recv_buffer[:content_len]
self._recv_buffer = self._recv_buffer[content_len:]
if self.jsonheader['content-type'] == 'text/json':
encoding = self.jsonheader['content-encoding']
self.request = self._json_decode(data, encoding)
print('received request', repr(self.request), 'from', self.addr)
else:
# Binary or unknown content-type
self.request = data
print(f'received {self.jsonheader["content-type"]} request from',
self.addr)
# Set selector to listen for write events, we're done reading.
self._set_selector_events_mask('w')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
把消息保存到 data 变量中后,process_request() 又会删除接收缓冲区中处理过的数据。接着,如果 content type 是 JSON 的话,它将解码并反序列化数据。否则(在我们的例子中)数据将被视 做二进制数据并打印出来
最后 process_request() 方法会修改 selector 为只监控写入事件。在服务端的程序 app-server.py 中,socket 初始化被设置成仅监控读事件。现在请求已经被全部处理完了,我们对读取事件就不感兴趣了
现在就可以创建一个响应写入到 socket 中。当 socket 可写时 create_response() 将被从 write() 方法中调用:
def create_response(self):
if self.jsonheader['content-type'] == 'text/json':
response = self._create_response_json_content()
else:
# Binary or unknown content-type
response = self._create_response_binary_content()
message = self._create_message(**response)
self.response_created = True
self._send_buffer += message
2
3
4
5
6
7
8
9
响应会根据不同的 content type 的不同而调用不同的方法创建。在这个例子中,当 action == 'search' 的时候会执行一个简单的字典查找。你可以在这个地方添加你自己的处理方法并调用
一个不好处理的问题是响应写入完成时如何关闭连接,我会在 _write() 方法中调用 close()
def _write(self):
if self._send_buffer:
print('sending', repr(self._send_buffer), 'to', self.addr)
try:
# Should be ready to write
sent = self.sock.send(self._send_buffer)
except BlockingIOError:
# Resource temporarily unavailable (errno EWOULDBLOCK)
pass
else:
self._send_buffer = self._send_buffer[sent:]
# Close when the buffer is drained. The response has been sent.
if sent and not self._send_buffer:
self.close()
2
3
4
5
6
7
8
9
10
11
12
13
14
虽然close() 方法的调用有点隐蔽,但是我认为这是一种权衡。因为消息类一个连接只处理一条消息。写入响应后,服务器无需执行任何操作。它的任务就完成了
# 客户端主程序
客户端主程序 app-client.py 中,参数从命令行中读取,用来创建请求并连接到服务端
$ ./app-client.py
usage: ./app-client.py <host> <port> <action> <value>
2
来个示例演示一下:
$ ./app-client.py 127.0.0.1 65432 search needle
当从命令行参数创建完一个字典来表示请求后,主机、端口、请求字典一起被传给 start_connection()
def start_connection(host, port, request):
addr = (host, port)
print('starting connection to', addr)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False)
sock.connect_ex(addr)
events = selectors.EVENT_READ | selectors.EVENT_WRITE
message = libclient.Message(sel, sock, addr, request)
sel.register(sock, events, data=message)
2
3
4
5
6
7
8
9
对服务器的 socket 连接被创建,消息对象被传入请求字典并创建
和服务端一样,消息对象在 sel.register() 方法中被关联到 socket 上。然而,客户端不同的是,socket 初始化的时候会监控读写事件,一旦请求被写入,我们将会修改为只监控读取事件
这种实现和服务端一样有好处:不浪费 CPU 生命周期。请求发送完成后,我们就不关注写入事件了,所以不用保持状态等待处理
# 客户端消息类
在 消息入口点 一节中,我们看到过,当 socket 使用准备就绪时,消息对象是如何调用具体动作的。现在让我们来看看 socket 上的数据是如何被读写的,以及消息准备好被加工的时候发生了什么
客户端消息类在 libclient.py 文件中,可以在 Github 上找到 源代码 (opens new window)
这些方法按照消息处理顺序出现在类中
客户端的第一个任务就是让请求入队列:
def queue_request(self):
content = self.request['content']
content_type = self.request['type']
content_encoding = self.request['encoding']
if content_type == 'text/json':
req = {
'content_bytes': self._json_encode(content, content_encoding),
'content_type': content_type,
'content_encoding': content_encoding
}
else:
req = {
'content_bytes': content,
'content_type': content_type,
'content_encoding': content_encoding
}
message = self._create_message(**req)
self._send_buffer += message
self._request_queued = True
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
用来创建请求的字典,取决于客户端程序 app-client.py 中传入的命令行参数,当消息对象创建的时候,请求字典被当做参数传入
请求消息被创建并追加到发送缓冲区中,消息将被 _write() 方法发送,状态参数 self._request_queued 被设置,这使 queue_request() 方法不会被重复调用
请求发送完成后,客户端就等待服务器的响应
客户端读取和处理消息的方法和服务端一致,由于响应数据是从 socket 上读取的,所以处理 header 的方法会被调用:process_protoheader() 和 process_jsonheader()
最终处理方法名字的不同在于处理一个响应,而不是创建:process_response(),_process_response_json_content() 和 _process_response_binary_content()
最后,但肯定不是最不重要的 —— 最终的 process_response() 调用:
def process_response(self):
# ...
# Close when response has been processed
self.close()
2
3
4
# 消息类的包装
我将通过提及一些方法的重要注意点来结束消息类的讨论
主程序中任意的类触发异常都由 except 字句来处理:
try:
message.process_events(mask)
except Exception:
print('main: error: exception for',
f'{message.addr}:\n{traceback.format_exc()}')
message.close()
2
3
4
5
6
注意最后一行的方法 message.close()
这一行很重要的原因有很多,不仅仅是保证 socket 被关闭,而且通过调用 message.close() 方法删除使用 select() 监控的 socket,这是类中的一段非常简洁的代码,它能减小复杂度。如果一个异常发生或者我们自己主动抛出,我们很清楚 close() 方法将处理善后
Message._read() 和 Message._write() 方法都包含一些有趣的东西:
def _read(self):
try:
# Should be ready to read
data = self.sock.recv(4096)
except BlockingIOError:
# Resource temporarily unavailable (errno EWOULDBLOCK)
pass
else:
if data:
self._recv_buffer += data
else:
raise RuntimeError('Peer closed.')
2
3
4
5
6
7
8
9
10
11
12
注意 except 行:except BlockingIOError:
_write() 方法也有,这几行很重要是因为它们捕获临时错误并通过使用 pass 跳过。临时错误是 socket 阻塞的时候发生的,比如等待网络响应或者连接的其它端
通过使用 pass 跳过异常,select() 方法将再次调用,我们将有机会重新读写数据
# 运行客户端 / 服务器应用程序
经过所有这些艰苦的工作后,让我们把程序运行起来并找到一些乐趣!
在这个救命中,我们将传一个空的字符串作为 host 参数的值,用来监听服务器端的所有 IP 地址。这样的话我就可以从其它网络上的虚拟机运行客户端程序,我将模拟一个 PowerPC 的机器
首先,把服务端程序运行进来:
$ ./app-server.py '' 65432
listening on ('', 65432)
2
现在让我们运行客户端,传入搜索内容,看看是否能看他(墨菲斯 - 黑客帝国中的角色):
$ ./app-client.py 10.0.1.1 65432 search morpheus
starting connection to ('10.0.1.1', 65432)
sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 41}{"action": "search", "value": "morpheus"}' to ('10.0.1.1', 65432)
received response {'result': 'Follow the white rabbit. 🐰'} from ('10.0.1.1', 65432)
got result: Follow the white rabbit. 🐰
closing connection to ('10.0.1.1', 65432)
2
3
4
5
6
我的命令行 shell 使用了 utf-8 编码,所以上面的输出可以是 emojis
再试试看能不能搜索到小狗:
$ ./app-client.py 10.0.1.1 65432 search 🐶
starting connection to ('10.0.1.1', 65432)
sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"action": "search", "value": "\xf0\x9f\x90\xb6"}' to ('10.0.1.1', 65432)
received response {'result': '🐾 Playing ball! 🏐'} from ('10.0.1.1', 65432)
got result: 🐾 Playing ball! 🏐
closing connection to ('10.0.1.1', 65432)
2
3
4
5
6
注意请求发送行的 byte string,很容易看出来你发送的小狗 emoji 表情被打印成了十六进制的字符串 \xf0\x9f\x90\xb6,我可以使用 emoji 表情来搜索是因为我的命令行支持 utf-8 格式的编码
这个示例中我们发送给网络原始的 bytes,这些 bytes 需要被接受者正确的解释。这就是为什么之前需要给消息附加头信息并且包含编码类型字段的原因
下面这个是服务器对应上面两个客户端连接的输出:
accepted connection from ('10.0.2.2', 55340)
received request {'action': 'search', 'value': 'morpheus'} from ('10.0.2.2', 55340)
sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 43}{"result": "Follow the white rabbit. \xf0\x9f\x90\xb0"}' to ('10.0.2.2', 55340)
closing connection to ('10.0.2.2', 55340)
accepted connection from ('10.0.2.2', 55338)
received request {'action': 'search', 'value': '🐶'} from ('10.0.2.2', 55338)
sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"result": "\xf0\x9f\x90\xbe Playing ball! \xf0\x9f\x8f\x90"}' to ('10.0.2.2', 55338)
closing connection to ('10.0.2.2', 55338)
2
3
4
5
6
7
8
9
注意发送行中写到客户端的 bytes,这就是服务端的响应消息
如果 action 参数不是搜索,你也可以试试给服务器发送二进制请求
$ ./app-client.py 10.0.1.1 65432 binary 😃
starting connection to ('10.0.1.1', 65432)
sending b'\x00|{"byteorder": "big", "content-type": "binary/custom-client-binary-type", "content-encoding": "binary", "content-length": 10}binary\xf0\x9f\x98\x83' to ('10.0.1.1', 65432)
received binary/custom-server-binary-type response from ('10.0.1.1', 65432)
got response: b'First 10 bytes of request: binary\xf0\x9f\x98\x83'
closing connection to ('10.0.1.1', 65432)
2
3
4
5
6
由于请求的 content-type 不是 text/json,服务器会把内容当成二进制类型并且不会解码 JSON,它只会打印 content-type 和返回的前 10 个 bytes 给客户端
$ ./app-server.py '' 65432
listening on ('', 65432)
accepted connection from ('10.0.2.2', 55320)
received binary/custom-client-binary-type request from ('10.0.2.2', 55320)
sending b'\x00\x7f{"byteorder": "little", "content-type": "binary/custom-server-binary-type", "content-encoding": "binary", "content-length": 37}First 10 bytes of request: binary\xf0\x9f\x98\x83' to ('10.0.2.2', 55320)
closing connection to ('10.0.2.2', 55320)
2
3
4
5
6