 SQLAlchemy 源码阅读
SQLAlchemy 源码阅读
SQLAlchemy 是 Python SQL 工具箱和 ORM 框架,它为应用程序开发人员提供了全面而灵活的 SQL 功能。它提供了一整套企业级持久化方案,旨在高效,高性能地访问数据库,并符合简单的 Pythonic 哲学。项目代码量比较大,接近 200 个文件,7 万行代码, 我们一起来挑战一下。由于篇幅原因,分成上下两篇,上篇包括如下内容:
# SQLAlchemy 项目结构
源码使用的版本是 1.3.0, 对应的 commitID 是 740bb50c2,和参考链接中官方文档 1.3 版本一致。项目目录大概包括:
| 目录 | 描述 |
|---|---|
| connectors | 连接 |
| dialects | 方言 |
| engine | 引擎 |
| event | 事件 |
| ext | 扩展功能 |
| orm | orm |
| pool | 连接池 |
| sql | sql 处理 |
| util | 工具类 |
SQLAlchemy 的架构图如下:

整体分成 3 层,从上到下分别是 ORM,core 和 DBAPI,其中 core,又分成左右两个区域。我们先学习其中的引擎,连接池,dialects(仅 sqlite)和 DBAPI 部分,也就是架构图的右半侧。其中 DBAPI(sqlite 相关)是在 python-core-library 中提供。
# 用 SQLAlchemy 操作 sqlite 数据库
先从使用 DBAPI 操作 sqlite 的 API 开始:
import sqlite3
con = sqlite3.connect('example.db')
cur = con.cursor()
# Create table
cur.execute('''CREATE TABLE stocks
(date text, trans text, symbol text, qty real, price real)''')
# Insert a row of data
cur.execute("INSERT INTO stocks VALUES ('2006-01-05','BUY','RHAT',100,35.14)")
# Save (commit) the changes
con.commit()
# Do this instead
t = ('RHAT',)
cur.execute('SELECT * FROM stocks WHERE symbol=?', t)
print(cur.fetchone())
# We can also close the connection if we are done with it.
# Just be sure any chang
con.close()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
操作 sqlite 数据库主要包括了下面几个步骤:
connect 数据库获得连接 con
从连接中获取操作游标 cur
使用 cur 执行 sql 语句(statement)
向连接 con 提交 commit 事务
使用 cur 的 fetchone/fecthmany/fetchall 方法获取数据
完成数据获取后使用 close 方法关闭连接 con
对比一下使用 sqlalchemy 进行 sqlite 操作:
from sqlalchemy import create_engine
eng = create_engine("sqlite:///:memory:", echo=True)
conn = eng.connect()
conn.execute("create table x (a integer, b integer)")
conn.execute("insert into x (a, b) values (1, 1)")
conn.execute("insert into x (a, b) values (2, 2)")
result = conn.execute("select x.a, x.b from x")
assert result.keys() == ["a", "b"]
result = conn.execute('''
select x.a, x.b from x where a=1
union
select x.a, x.b from x where a=2
''')
assert result.keys() == ["a", "b"]
2
3
4
5
6
7
8
9
10
11
12
13
14
可以看到使用 sqlalchemy 后操作变的简单,把 cursor,commit,fetch 和 close 等操作隐藏到 engine 内部,简化成 3 步:
使用 create_engine 函数创建引擎 eng
使用引擎的 connect 方法创建连接 conn
使用 conn 执行 SQL 语句并获取返回的执行结果
# Engine 代码分析
跟随 create_engine 的 API,可以看到这里使用策略模式去创建不同的 engine 实现:
# engine/__init__.py
from . import strategies
default_strategy = "python" # 默认
def create_engine(*args, **kwargs):
strategy = kwargs.pop("strategy", default_strategy)
strategy = strategies.strategies[strategy]
return strategy.create(*args, **kwargs)
2
3
4
5
6
7
8
9
10
默认的 engine 策略:
# engine/strategies.py
strategies = {}
class EngineStrategy(object):
def __init__(self):
strategies[self.name] = self
class DefaultEngineStrategy(EngineStrategy):
def create(self, name_or_url, **kwargs):
...
class PlainEngineStrategy(DefaultEngineStrategy):
name = "python"
engine_cls = base.Engine # 引擎类
PlainEngineStrategy()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
重点就在策略的 create 方法了, 去掉数据准备和异常处理后核心代码如下:
def create(self, name_or_url, **kwargs):
...
# get dialect class
u = url.make_url(name_or_url)
entrypoint = u._get_entrypoint()
dialect_cls = entrypoint.get_dialect_cls(u)
# create dialect
dialect = dialect_cls(**dialect_args)
# pool
poolclass = dialect_cls.get_pool_class(u)
pool = poolclass(creator, **pool_args)
# engine
engineclass = self.engine_cls
engine = engineclass(pool, dialect, u, **engine_args)
...
return engine
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
create 函数可以理解为 engine 的创建模版,主要是下面 3 个步骤:
根据 url 获取到数据库方言,适配不同数据库 sqlite/mysql/postgresql...
获取不同方言的连接池实现
创建 engine,持有 dialect 和 pool
Engine 的构造函数和 connect 方法如下:
class Engine(Connectable, log.Identified):
_connection_cls = Connection
def __init__(
self,
pool,
dialect,
url,
logging_name=None,
echo=None,
proxy=None,
execution_options=None,
):
self.pool = pool
self.url = url
self.dialect = dialect
self.engine = self
...
def connect(self, **kwargs):
return self._connection_cls(self, **kwargs)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
engine 主要功能就是管理和持有 connection,pool 和 dialect,对外提供 API。
# SQLiteDialect 代码分析
dialect 是根据 url 自动识别,使用 PluginLoader 进行动态加载:
class PluginLoader(object):
def __init__(self, group, auto_fn=None):
self.group = group
self.impls = {}
self.auto_fn = auto_fn
def load(self, name):
# import一次
if name in self.impls:
return self.impls[name]()
if self.auto_fn:
loader = self.auto_fn(name)
if loader:
self.impls[name] = loader
return loader()
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
sqlite-dialect 使用下面的 __import__ 动态加载模块:
def _auto_fn(name):
if "." in name:
dialect, driver = name.split(".")
else:
dialect = name
driver = "base"
if dialect in _translates:
translated = _translates[dialect]
dialect = translated
try:
# 动态加载模块
module = __import__("sqlalchemy.dialects.%s" % (dialect,)).dialects
except ImportError:
return None
module = getattr(module, dialect)
if hasattr(module, driver):
module = getattr(module, driver)
return lambda: module.dialect
else:
return None
registry = util.PluginLoader("sqlalchemy.dialects", auto_fn=_auto_fn)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
不同方言实现需要提供一个 dialect 对象,在 sqlite 中是这样的:
## sqlalchemy/dialects/sqlite/__init__.py
base.dialect = dialect = pysqlite.dialect
## sqlalchemy/dialects/sqlite/pysqlite.py
class SQLiteDialect_pysqlite(SQLiteDialect):
pass
dialect = SQLiteDialect_pysqlite
2
3
4
5
6
7
8
9
10
11
SQLiteDialect 功能相简单,一是决定 POOL_CLASS 的类型: memory 实现使用的是 SingletonThreadPool;db 文件使用 NullPool,下面分析 Pool 时候会用到。
class SQLiteDialect_pysqlite(SQLiteDialect):
@classmethod
def get_pool_class(cls, url):
if url.database and url.database != ":memory:":
return pool.NullPool
else:
return pool.SingletonThreadPool
2
3
4
5
6
7
8
9
二是提供包装 DBAPI 得到的 connect:
class DefaultDialect(interfaces.Dialect):
...
def connect(self, *cargs, **cparams):
return self.dbapi.connect(*cargs, **cparams)
class SQLiteDialect_pysqlite(SQLiteDialect):
...
@classmethod
def dbapi(cls):
try:
from pysqlite2 import dbapi2 as sqlite
except ImportError:
try:
from sqlite3 import dbapi2 as sqlite # try 2.5+ stdlib name.
except ImportError as e:
raise e
return sqlite
def connect(self, *cargs, **cparams):
passphrase = cparams.pop("passphrase", "")
pragmas = dict((key, cparams.pop(key, None)) for key in self.pragmas)
conn = super(SQLiteDialect_pysqlcipher, self).connect(
*cargs, **cparams
)
conn.execute('pragma key="%s"' % passphrase)
for prag, value in pragmas.items():
if value is not None:
conn.execute('pragma %s="%s"' % (prag, value))
return conn
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
connect 在 SQLiteDialect_pysqlite 类和父类 DefaultDialect 之间反复横跳,核心功能就是下面 2 句代码:
from sqlite3 import dbapi2 as sqlite
sqlite.connect(*cargs, **cparams)
2
# Connect 和 Pool 代码分析
Connection 构造函数如下:
class Connection(Connectable):
def __init__(
self,
engine,
connection=None,
close_with_result=False,
_branch_from=None,
_execution_options=None,
_dispatch=None,
_has_events=None,
):
self.engine = engine
self.dialect = engine.dialect
self.__connection = engine.raw_connection()
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
connection 主要使用 engine.raw_connection 创建了一个 DBAPI 连接
class Engine(Connectable, log.Identified):
def raw_connection(self, _connection=None):
return self._wrap_pool_connect(
self.pool.unique_connection, _connection
)
def _wrap_pool_connect(self, fn, connection):
dialect = self.dialect
try:
return fn()
except dialect.dbapi.Error as e:
...
2
3
4
5
6
7
8
9
10
11
12
13
14
pool.unique_connection 负责创建数据库连接,这里的实现过程比较复杂,个人觉得也挺绕的,涉及 Pool,ConnectionFairy 和 ConnectionRecord 三个类。我们一点一点的跟踪:
class SingletonThreadPool(Pool):
def __init__(self, creator, pool_size=5, **kw):
Pool.__init__(self, creator, **kw)
self._conn = threading.local()
self._all_conns = set()
self.size = pool_size
def unique_connection(self):
return _ConnectionFairy._checkout(self)
def _do_get(self):
c = _ConnectionRecord(self)
self._conn.current = weakref.ref(c)
if len(self._all_conns) >= self.size:
self._cleanup()
self._all_conns.add(c)
return c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
SingletonThreadPool 主要在_do_get 的实现,创建一个 ConnectionRecor 对象,然后将其加入到自己管理的集合中后再返回,标准的池操作了。如何通过 unique_connection 方法去触发_do_get 方法并得到实际的 db-connect
class _ConnectionFairy(object):
def __init__(self, dbapi_connection, connection_record, echo):
self.connection = dbapi_connection
self._connection_record = connection_record
@classmethod
def _checkout(cls, pool, threadconns=None, fairy=None):
if not fairy:
fairy = _ConnectionRecord.checkout(pool)
fairy._pool = pool
fairy._counter = 0
return fairy
...
class _ConnectionRecord(object):
def __init__(self, pool, connect=True):
self.__pool = pool
@classmethod
def checkout(cls, pool):
rec = pool._do_get()
try:
dbapi_connection = rec.get_connection()
except Exception as err:
...
fairy = _ConnectionFairy(dbapi_connection, rec, echo)
rec.fairy_ref = weakref.ref(
fairy,
lambda ref: _finalize_fairy
and _finalize_fairy(None, rec, pool, ref, echo),
)
...
return fairy
def get_connection(self):
pool = self.__pool
connection = pool.creator(self)
self.connection = connection
return connection
...
class DefaultEngineStrategy(EngineStrategy):
def create(self, name_or_url, **kwargs):
def connect(connection_record=None):
# dbapai-connection
return dialect.connect(*cargs, **cparams)
creator = pop_kwarg("creator", connect)
pool = poolclass(creator, **pool_args)
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
整个过程大概是这样的:
ConnectionFairy.checkout 调用 ConnectionRecord.checkout 方法
ConnectionRecord 再回调 SingletonThreadPool 的_do_get 方法创建 rec 对象
rec 对象继续调用 SingletonThreadPool 的 creator 方法
creator 方法使用 dialect.connect 获取数据库连接 dbapi_connection
使用 rec 和 dbapi_connection 再创建 fairy 对象
返回 fairy 对象
除了执行过程在来回穿插外,还因为 ConnectionFairy 和 ConnectionRecord 是循环依赖的:
class _ConnectionRecord(object):
fairy_ref = None
...
class _ConnectionFairy(object):
def __init__(self, dbapi_connection, connection_record, echo):
self._connection_record = connection_record
2
3
4
5
6
7
8
循环依赖的安全建立主要使用 weakref,想学习的可以翻看之前的博文
# execute-SQL 语句
知道 connection 如何创建后,继续看 connection 使用 execute 方法执行 sql 语句:
def execute(self, object_, *multiparams, **params):
if isinstance(object_, util.string_types[0]):
return self._execute_text(object_, multiparams, params)
...
def _execute_text(self, statement, multiparams, params):
"""Execute a string SQL statement."""
dialect = self.dialect
parameters = _distill_params(multiparams, params)
ret = self._execute_context(
dialect,
dialect.execution_ctx_cls._init_statement,
statement,
parameters,
statement,
parameters,
)
return ret
def _execute_context(
self, dialect, constructor, statement, parameters, *args
):
conn = self.__connection
...
context = constructor(dialect, self, conn, *args)
...
cursor, statement, parameters = (
context.cursor,
context.statement,
context.parameters,
)
...
self.dialect.do_execute(
cursor, statement, parameters, context
)
...
result = context._setup_crud_result_proxy()
return result
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
execute 还有一些其它分支,可以适用 ORM 等场景,本篇只介绍纯文本的 sql
函数层层穿透后,主要包括下面三段代码:
利用 dialect 创建 context 上下文
使用 dialect 执行 sql 语句(文本)
使用 context 获取执行的结果并返回
dialect 涉及的上下文 context 创建和 sql 执行:
class DefaultDialect(interfaces.Dialect):
def do_execute(self, cursor, statement, parameters, context=None):
cursor.execute(statement, parameters)
DefaultDialect.execution_ctx_cls = DefaultExecutionContext
2
3
4
5
6
可以看到执行语句就是使用 cursor 对象,和前面直接操作 sqlite 一致。每条 sql 执行的上下文 context 是下面方式构建的:
class DefaultExecutionContext(interfaces.ExecutionContext):
@classmethod
def _init_statement(
cls, dialect, connection, dbapi_connection, statement, parameters
):
self = cls.__new__(cls)
self.root_connection = connection
self._dbapi_connection = dbapi_connection
self.dialect = connection.dialect
...
self.parameters = [{}]
...
self.statement = self.unicode_statement = statement
self.cursor = self.create_cursor()
return self
def create_cursor(self):
return self._dbapi_connection.cursor()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Result 分析
sql 执行的结果,在context._setup_crud_result_proxy中返回 ResultProxy 对象。ResultProxy 是一个可以迭代的对象,可以使用 fetchone 获取单条记录:
class ResultProxy(object):
def __iter__(self):
while True:
row = self.fetchone()
if row is None:
return
else:
yield row
def __next__(self):
row = self.fetchone()
if row is None:
raise StopIteration()
else:
return row
def fetchone(self):
try:
row = self._fetchone_impl()
if row is not None:
return self.process_rows([row])[0]
def _fetchone_impl(self):
try:
return self.cursor.fetchone()
except AttributeError:
return self._non_result(None)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
对获取的记录还可以使用 process_rows 进行数据封装,这个以后再介绍。
# 小结
我们完整的追逐了使用 sqlalchemy 执行 sql 语句的过程,可以简单小结如下:
使用 url 语法查找并动态加载数据库方言
创建引擎对象,管理方言,方言的连接池,提供 SQL 的 API
使用引擎对象获取到数据库链接 connect,获取后的链接使用 pool 管理
执行 SQL 语句并获取执行结果
下面的类图介绍的更详细, 完整展示了 engine/pool/connection/dialect 的关系:

# 小技巧
deprecated 是一个废弃 API 装饰器, 主要给一些不再支持/推荐的 API 加上使用警告和更替的方法:
def deprecated(version, message=None, add_deprecation_to_docstring=True):
if add_deprecation_to_docstring:
header = ".. deprecated:: %s %s" % (version, (message or ""))
else:
header = None
if message is None:
message = "Call to deprecated function %(func)s"
def decorate(fn):
return _decorate_with_warning(
fn,
exc.SADeprecationWarning,
message % dict(func=fn.__name__),
header,
)
return decorate
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
比如 Connectable.contextual_connect 的 API 这样使用:
class Connectable(object):
@util.deprecated(
"1.3",
"The :meth:`.Engine.contextual_connect` and "
":meth:`.Connection.contextual_connect` methods are deprecated. This "
"method is an artifact of the threadlocal engine strategy which is "
"also to be deprecated. For explicit connections from an "
":class:`.Engine`, use the :meth:`.Engine.connect` method.",
)
def contextual_connect(self, *arg, **kw):
...
2
3
4
5
6
7
8
9
10
11
12
这对库/框架的开发者非常有用,API 的变动可以这种方式通知使用者,进行平滑的升级替换。
SQLAlchemy 是 Python SQL 工具箱和 ORM 框架,它为应用程序开发人员提供了全面而灵活的 SQL 功能。它提供了一整套企业级持久化方案,旨在高效,高性能地访问数据库,并符合 Pythonic 之禅。项目代码量比较大,接近 200 个文件,7 万行代码, 我们一起来挑战一下。由于篇幅原因,分成上下两篇,上篇我们学习了 core 部分的 engine,dialect,connection 和 pool 等部分,下篇主要学习 core 部分剩余的 sql 表达式和 orm 部分,包括如下内容:
# SQL-schema 使用示例
上篇中,我们使用的 sql 都是手工编写的语句,下面这样:
create table x (a integer, b integer)
insert into x (a, b) values (1, 1)
2
在 sqlalchemy 中可以通过定义 schema 的方式进行数据操作,完整的示例如下:
from sqlalchemy import create_engine
from sqlalchemy import MetaData
from sqlalchemy import Table
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy.sql import select
engine = create_engine('sqlite:///:memory:', echo=True)
metadata = MetaData()
users = Table('users', metadata,
Column('id', Integer, primary_key=True),
Column('name', String),
Column('fullname', String),
)
metadata.create_all(engine)
ins = users.insert().values(name='jack', fullname='Jack Jones')
print(ins)
result = engine.execute(ins)
print(result, result.inserted_primary_key)
s = select([users])
result = conn.execute(s)
for row in result:
print(row)
result = engine.execute("select * from users")
for row in result:
print(row)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
示例程序的执行过程:
创建 engine,用于数据库连接
创建 metadata,用于管理 schema
创建 users 表的 Table,绑定到 metadata;同时包括 id,name 和 fullname 三个 column
将 metadata 提交到 engine(创建表)
使用 users 插入数据
查询 users 的数据
使用普通 sql 的方式验证数据
下面是示例的执行日志,清晰展示了上面过程:
...
2021-04-19 10:02:09,166 INFO sqlalchemy.engine.base.Engine
CREATE TABLE users (
id INTEGER NOT NULL,
name VARCHAR,
fullname VARCHAR,
PRIMARY KEY (id)
)
2021-04-19 10:02:09,166 INFO sqlalchemy.engine.base.Engine ()
2021-04-19 10:02:09,167 INFO sqlalchemy.engine.base.Engine COMMIT
INSERT INTO users (name, fullname) VALUES (:name, :fullname)
2021-04-19 10:02:09,167 INFO sqlalchemy.engine.base.Engine INSERT INTO users (name, fullname) VALUES (?, ?)
2021-04-19 10:02:09,168 INFO sqlalchemy.engine.base.Engine ('jack', 'Jack Jones')
2021-04-19 10:02:09,168 INFO sqlalchemy.engine.base.Engine COMMIT
<sqlalchemy.engine.result.ResultProxy object at 0x7ffca0607070> [1]
2021-04-27 11:38:19,134 INFO sqlalchemy.engine.base.Engine SELECT users.id, users.name, users.fullname
FROM users
2021-04-27 11:38:19,134 INFO sqlalchemy.engine.base.Engine ()
(1, 'jack', 'Jack Jones')
2021-04-19 10:02:09,168 INFO sqlalchemy.engine.base.Engine select * from users
2021-04-19 10:02:09,168 INFO sqlalchemy.engine.base.Engine ()
(1, 'jack', 'Jack Jones')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
在开始之前,我们需要简单了解一下 SQL 语句的分类:
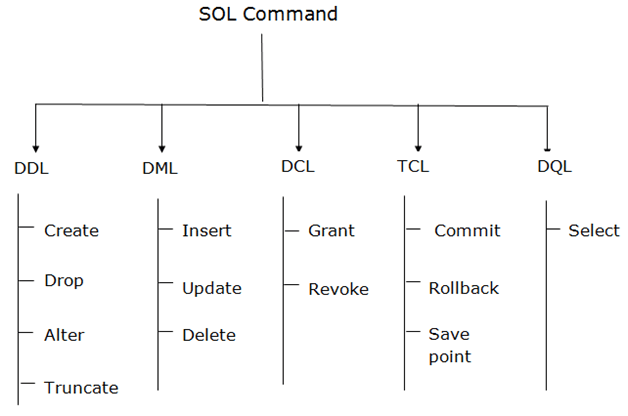
Type of SQL Statements (opens new window)
在我们的 schema 使用示例中,就包括了 DDL,DML 和 DQL 三种类型的语句,下面我们按照这 3 种类型,详细了解一下 sqlalchemy 的 sql 表达式部分。sql 表达式主要在 sql 包中,部分文件的功能如下:
| 模块 | 描述 |
|---|---|
| base.py | 基础类 |
| compiler.py | sql 编译 |
| crud.py | crud 的参数处理 |
| ddl.py | DDL 语句 |
| default_comparator.py | 比较 |
| dml.py | DML 语句 |
| elements.py | 基本类型 |
| operators.py | sql 操作符 |
| schema.py | schema 定义 |
| selectable.py | DQL |
| sqltypes.py&&type_api.py | sql 数据类型 |
| vistitors.py | 递归算法 |
# DDL(Data Definition Language)创建 table
首先了解一下 schema 的基础实现 visitable:
class VisitableType(type):
def __init__(cls, clsname, bases, clsdict):
if clsname != "Visitable" and hasattr(cls, "__visit_name__"):
_generate_dispatch(cls)
super(VisitableType, cls).__init__(clsname, bases, clsdict)
def _generate_dispatch(cls):
if "__visit_name__" in cls.__dict__:
visit_name = cls.__visit_name__
if isinstance(visit_name, str):
getter = operator.attrgetter("visit_%s" % visit_name)
def _compiler_dispatch(self, visitor, **kw):
try:
meth = getter(visitor)
except AttributeError:
raise exc.UnsupportedCompilationError(visitor, cls)
else:
return meth(self, **kw)
cls._compiler_dispatch = _compiler_dispatch
class Visitable(util.with_metaclass(VisitableType, object)):
pass
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Visitable 约定子类必须提供 visit_name 的类属性,用来绑定编译方法。参与 sql 的类都继承自 Visitable:
class SchemaItem(SchemaEventTarget, visitors.Visitable):
__visit_name__ = "schema_item"
class MetaData(SchemaItem):
__visit_name__ = "metadata"
class Table(DialectKWArgs, SchemaItem, TableClause):
__visit_name__ = "table"
class Column(DialectKWArgs, SchemaItem, ColumnClause):
__visit_name__ = "column"
class TypeEngine(Visitable):
...
class Integer(_LookupExpressionAdapter, TypeEngine):
__visit_name__ = "integer"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
MetaData 是 schema 的集合,记录了所有的 Table 定义, 通过 _add_table 函数用来添加表:
class MetaData(SchemaItem):
def __init__(
self,
bind=None,
reflect=False,
schema=None,
quote_schema=None,
naming_convention=None,
info=None,
):
# table集合
self.tables = util.immutabledict()
self.schema = quoted_name(schema, quote_schema)
self._schemas = set()
def _add_table(self, name, schema, table):
key = _get_table_key(name, schema)
dict.__setitem__(self.tables, key, table)
if schema:
self._schemas.add(schema)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Table 是 column 的集合,在创建 table 对象的时候,把自己添加到 metadata 中:
class Table(DialectKWArgs, SchemaItem, TableClause):
def __new__(cls, *args, **kw):
name, metadata, args = args[0], args[1], args[2:]
schema = metadata.schema
table = object.__new__(cls)
# 添加到metadata
metadata._add_table(name, schema, table)
table._init(name, metadata, *args, **kw)
return table
def _init(self, name, metadata, *args, **kwargs):
super(Table, self).__init__(
quoted_name(name, kwargs.pop("quote", None))
)
self.metadata = metadata
self.schema = metadata.schema
# column集合
self._columns = ColumnCollection()
self._init_items(*args)
def _init_items(self, *args):
# column
for item in args:
if item is not None:
item._set_parent_with_dispatch(self)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Column 是通过下面的方法将 column 添加到 table 的 colummns 中:
class Column(DialectKWArgs, SchemaItem, ColumnClause):
def __init__(self, *args, **kwargs):
pass
def _set_parent(self, table):
table._columns.replace(self)
class ColumnCollection(util.OrderedProperties):
def replace(self, column):
...
self._data[column.key] = column
...
2
3
4
5
6
7
8
9
10
11
12
13
现阶段,我们大概厘清了 metadata,table 和 column 的数据结构:metadata 持有 table 集合,table 持有 column 集合。接下来我们看看这个数据结构如何转换成 sql 语句,API 是通过 MetaData.create_all 函数实现:
class MetaData(SchemaItem):
def create_all(self, bind=None, tables=None, checkfirst=True):
bind._run_visitor(
ddl.SchemaGenerator, self, checkfirst=checkfirst, tables=tables
)
class Engine(Connectable, log.Identified):
def _run_visitor(
self, visitorcallable, element, connection=None, **kwargs
):
with self._optional_conn_ctx_manager(connection) as conn:
conn._run_visitor(visitorcallable, element, **kwargs)
class Connection(Connectable):
def _run_visitor(self, visitorcallable, element, **kwargs):
visitorcallable(self.dialect, self, **kwargs).traverse_single(element)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
create-table 的 sql 编译主要由 ddl 中的 SchemaGenerator 实现, 下面是 SchemaGenerator 的继承关系和核心的 traverse_single 函数:
class ClauseVisitor(object):
def traverse_single(self, obj, **kw):
# 遍历所有的visit实现
for v in self.visitor_iterator:
meth = getattr(v, "visit_%s" % obj.__visit_name__, None)
if meth:
return meth(obj, **kw)
@property
def visitor_iterator(self):
v = self
while v:
yield v
v = getattr(v, "_next", None)
class SchemaVisitor(ClauseVisitor):
...
class DDLBase(SchemaVisitor):
...
class SchemaGenerator(DDLBase):
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
创建 meta,table 和 columun 的过程:
class SchemaGenerator(DDLBase):
def visit_metadata(self, metadata):
tables = list(metadata.tables.values())
collection = sort_tables_and_constraints(
[t for t in tables if self._can_create_table(t)]
)
for table, fkcs in collection:
if table is not None:
# 创建表
self.traverse_single(
table,
create_ok=True,
include_foreign_key_constraints=fkcs,
_is_metadata_operation=True,
)
def visit_table(
self,
table,
create_ok=False,
include_foreign_key_constraints=None,
_is_metadata_operation=False,
):
for column in table.columns:
if column.default is not None:
# 创建column-DDLElement
self.traverse_single(column.default)
self.connection.execute(
# fmt: off
# 创建create-table-DDLElement
CreateTable(
table,
include_foreign_key_constraints= # noqa
include_foreign_key_constraints,
)
# fmt: on
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
CreateTableDDLElement 和 CreateColumnDDLElement 的继承关系:
class _DDLCompiles(ClauseElement):
def _compiler(self, dialect, **kw):
return dialect.ddl_compiler(dialect, self, **kw)
class DDLElement(Executable, _DDLCompiles):
...
class _CreateDropBase(DDLElement):
...
class CreateTable(_CreateDropBase):
__visit_name__ = "create_table"
def __init__(
self, element, on=None, bind=None, include_foreign_key_constraints=None
):
super(CreateTable, self).__init__(element, on=on, bind=bind)
self.columns = [CreateColumn(column) for column in element.columns]
class CreateColumn(_DDLCompiles):
__visit_name__ = "create_column"
def __init__(self, element):
self.element = element
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
最终这些 DDLElement 在 compiler 中被 DDLCompiler 编译成 sql 语句, CREATE TABLE是这样被编译的:
def visit_create_table(self, create):
table = create.element
preparer = self.preparer
text = "nCREATE "
if table._prefixes:
text += " ".join(table._prefixes) + " "
text += "TABLE " + preparer.format_table(table) + " "
create_table_suffix = self.create_table_suffix(table)
if create_table_suffix:
text += create_table_suffix + " "
text += "("
separator = "n"
# if only one primary key, specify it along with the column
first_pk = False
for create_column in create.columns:
column = create_column.element
try:
processed = self.process(
create_column, first_pk=column.primary_key and not first_pk
)
if processed is not None:
text += separator
separator = ", n"
text += "t" + processed
if column.primary_key:
first_pk = True
except exc.CompileError as ce:
...
const = self.create_table_constraints(
table,
_include_foreign_key_constraints=create.include_foreign_key_constraints, # noqa
)
if const:
text += separator + "t" + const
text += "n)%snn" % self.post_create_table(table)
return text
def visit_create_column(self, create, first_pk=False):
column = create.element
text = self.get_column_specification(column, first_pk=first_pk)
const = " ".join(
self.process(constraint) for constraint in column.constraints
)
if const:
text += " " + const
return text
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
在前面 column 介绍中,我们略过了数据类型。大家都知道 sql 的数据类型和 python 数据类型有差异, 下面是一些常见的 SQL 数据类型:
class TypeEngine(Visitable):
...
class Integer(_LookupExpressionAdapter, TypeEngine):
__visit_name__ = "integer"
...
class String(Concatenable, TypeEngine):
__visit_name__ = "string"
...
class CHAR(String):
__visit_name__ = "CHAR"
...
class VARCHAR(String):
__visit_name__ = "VARCHAR"
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
数据类型由 GenericTypeCompiler 进行编译:
class TypeCompiler(util.with_metaclass(util.EnsureKWArgType, object)):
def process(self, type_, **kw):
return type_._compiler_dispatch(self, **kw)
class GenericTypeCompiler(TypeCompiler):
def visit_INTEGER(self, type_, **kw):
return "INTEGER"
def visit_string(self, type_, **kw):
return self.visit_VARCHAR(type_, **kw)
def visit_VARCHAR(self, type_, **kw):
return self._render_string_type(type_, "VARCHAR")
def _render_string_type(self, type_, name):
text = name
if type_.length:
text += "(%d)" % type_.length
if type_.collation:
text += ' COLLATE "%s"' % type_.collation
return text
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# DML(Data Manipulation Language)使用 insert 插入数据
数据插入的 API 由 TableClause 提供的 insert 函数:
class TableClause(Immutable, FromClause):
@util.dependencies("sqlalchemy.sql.dml")
def insert(self, dml, values=None, inline=False, **kwargs):
return dml.Insert(self, values=values, inline=inline, **kwargs)
2
3
4
5
dml 中提供了 Insert 类的实现:
class UpdateBase(
HasCTE, DialectKWArgs, HasPrefixes, Executable, ClauseElement
):
...
class ValuesBase(UpdateBase):
...
class Insert(ValuesBase):
__visit_name__ = "insert"
...
2
3
4
5
6
7
8
9
10
11
按照 ddl 的经验,我们查找 insert 语句的编译方法,在 SQLCompiler 中:
class SQLCompiler(Compiled):
def visit_insert(self, insert_stmt, asfrom=False, **kw):
crud_params = crud._setup_crud_params(
self, insert_stmt, crud.ISINSERT, **kw
)
if insert_stmt._has_multi_parameters:
crud_params_single = crud_params[0]
else:
crud_params_single = crud_params
preparer = self.preparer
supports_default_values = self.dialect.supports_default_values
text = "INSERT "
text += "INTO "
table_text = preparer.format_table(insert_stmt.table)
if crud_params_single or not supports_default_values:
text += " (%s)" % ", ".join(
[preparer.format_column(c[0]) for c in crud_params_single]
)
...
if insert_stmt.select is not None:
select_text = self.process(self._insert_from_select, **kw)
if self.ctes and toplevel and self.dialect.cte_follows_insert:
text += " %s%s" % (self._render_cte_clause(), select_text)
else:
text += " %s" % select_text
elif not crud_params and supports_default_values:
text += " DEFAULT VALUES"
elif insert_stmt._has_multi_parameters:
text += " VALUES %s" % (
", ".join(
"(%s)" % (", ".join(c[1] for c in crud_param_set))
for crud_param_set in crud_params
)
)
else:
text += " VALUES (%s)" % ", ".join([c[1] for c in crud_params])
return text
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
可以看到 insert 语句就是对 Insert 对象,通过字符串模版拼接而来。
# DQL(Data Query Language)使用 select 查询数据
数据查询 select 语句也都有特定的数据结构 Select,继承关系如下:
class SelectBase(HasCTE, Executable, FromClause):
...
class GenerativeSelect(SelectBase):
...
class Select(HasPrefixes, HasSuffixes, GenerativeSelect):
__visit_name__ = "select"
def __init__(
self,
columns=None,
whereclause=None,
from_obj=None,
distinct=False,
having=None,
correlate=True,
prefixes=None,
suffixes=None,
**kwargs
):
GenerativeSelect.__init__(self, **kwargs)
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
select 的编译语句也在 SQLCompiler 中:
class SQLCompiler(Compiled):
def visit_select(
self,
select,
asfrom=False,
parens=True,
fromhints=None,
compound_index=0,
nested_join_translation=False,
select_wraps_for=None,
lateral=False,
**kwargs
):
...
froms = self._setup_select_stack(select, entry, asfrom, lateral)
column_clause_args = kwargs.copy()
column_clause_args.update(
{"within_label_clause": False, "within_columns_clause": False}
)
text = "SELECT " # we're off to a good start !
text += self.get_select_precolumns(select, **kwargs)
# the actual list of columns to print in the SELECT column list.
inner_columns = [
c
for c in [
self._label_select_column(
select,
column,
populate_result_map,
asfrom,
column_clause_args,
name=name,
)
for name, column in select._columns_plus_names
]
if c is not None
]
...
text = self._compose_select_body(
text, select, inner_columns, froms, byfrom, kwargs
)
if select._statement_hints:
per_dialect = [
ht
for (dialect_name, ht) in select._statement_hints
if dialect_name in ("*", self.dialect.name)
]
if per_dialect:
text += " " + self.get_statement_hint_text(per_dialect)
if self.ctes and toplevel:
text = self._render_cte_clause() + text
if select._suffixes:
text += " " + self._generate_prefixes(
select, select._suffixes, **kwargs
)
self.stack.pop(-1)
if (asfrom or lateral) and parens:
return "(" + text + ")"
else:
return text
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
select 语句一样是采用字符串拼接得到。
# ORM 示例
orm 的使用和 schema 使用方式略有不同, 下面是 orm 的示例:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
engine = create_engine('sqlite:///:memory:', echo=True)
Model = declarative_base()
class User(Model):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
nickname = Column(String)
def __repr__(self):
return "<User(name='%s', fullname='%s', nickname='%s')>" % (
self.name, self.fullname, self.nickname)
Model.metadata.create_all(engine)
print("="*10)
Session = sessionmaker(bind=engine)
session = Session()
ed_user = User(name='ed', fullname='Ed Jones', nickname='edsnickname')
session.add(ed_user)
session.commit()
print(ed_user.id)
result = engine.execute("select * from users")
for row in result:
print(row)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
对比 schema 和 orm 的差异,可以得到下表:
schema 方式|orm 方式 创建 engine,用于数据库连接|- 创建 metadata,用于管理 schema|创建 Model 创建 users 表的 Table|创建 User 模型 将 metadata 提交到 engine(创建表)|- -|创建 session 使用 users 插入数据|使用 session 插入数据
总结一下主要就 2 点差异:
orm 时候不用显示的创建表的 schema
orm 的数据处理都使用 session 来操作,而不是使用 connection
# model 核心功能
Model 类使用 declarative_base 动态创建:
class DeclarativeMeta(type):
def __init__(cls, classname, bases, dict_):
if "_decl_class_registry" not in cls.__dict__:
_as_declarative(cls, classname, cls.__dict__)
type.__init__(cls, classname, bases, dict_)
def __setattr__(cls, key, value):
_add_attribute(cls, key, value)
def __delattr__(cls, key):
_del_attribute(cls, key)
def declarative_base(
bind=None,
metadata=None,
mapper=None,
cls=object,
name="Base",
constructor=_declarative_constructor,
class_registry=None,
metaclass=DeclarativeMeta,
):
# 创建metadata
lcl_metadata = metadata or MetaData()
if class_registry is None:
class_registry = weakref.WeakValueDictionary()
bases = not isinstance(cls, tuple) and (cls,) or cls
class_dict = dict(
_decl_class_registry=class_registry, metadata=lcl_metadata
)
# 构造函数
if constructor:
class_dict["__init__"] = constructor
if mapper:
class_dict["__mapper_cls__"] = mapper
# class-meta
return metaclass(name, bases, class_dict)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
关于如何动态创建类,在小技巧中进行介绍。declarative_base 主要定义了 Model 类的几个特性:
Model 类的构造函数
__init__使用_declarative_constructorModel 类的子类在构造的时候会调用_as_declarative
model 对象会使用_add_attribute 进行赋值
先从构造函数_declarative_constructor 开始:
def _declarative_constructor(self, **kwargs):
cls_ = type(self)
for k in kwargs:
if not hasattr(cls_, k):
raise TypeError(
"%r is an invalid keyword argument for %s" % (k, cls_.__name__)
)
setattr(self, k, kwargs[k])
_declarative_constructor.__name__ = "__init__"
2
3
4
5
6
7
8
9
10
11
看起来非常简单,但是这里做了一个类和对象实例之间的校验转换。我们先看一段演示代码:
class DummyModel(object):
name = ["dummy_model"] # 引用类型
a = DummyModel()
b = DummyModel()
assert id(a.name) == id(b.name) == id(DummyModel.name)
a.name.append("a")
assert id(a.name) == id(b.name) == id(DummyModel.name)
2
3
4
5
6
7
8
DummyModel 的类属性 name 和 a 对象的 name 属性都是同一个引用。如果使用 Model 类:
Model = declarative_base()
class UserModel(Model):
__tablename__ = 'user' # 必须字段
id = Column(Integer, primary_key=True) # 必须字段
name = Column(String)
c = UserModel()
c.name = "c"
d = UserModel()
d.name = "d"
# 注意并不是Column
assert isinstance(UserModel.name, InstrumentedAttribute)
assert isinstance(c.name, str)
assert d.name == "d"
assert id(c.name) != id(d.name) != id(UserModel.name)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
可以发现 UserModel 的类属性 name 和 d 对象的 name 属性完全不一样,类定义的是 Cloumn(InstrumentedAttribute),对象变成了 str。这个就是 orm 模型的特性之一,Model 是定义格式模版,对象实例化后转化为普通数据。
Model 的另外一个功能是隐式创建 Table 对象,在_as_declarative 函数中通过_MapperConfig 实现
class _MapperConfig(object):
def setup_mapping(cls, cls_, classname, dict_):
cfg_cls = _MapperConfig
cfg_cls(cls_, classname, dict_)
def __init__(self, cls_, classname, dict_):
...
self._setup_table()
...
def _setup_table(self):
...
table_cls = Table
args, table_kw = (), {}
if table_args:
if isinstance(table_args, dict):
table_kw = table_args
elif isinstance(table_args, tuple):
if isinstance(table_args[-1], dict):
args, table_kw = table_args[0:-1], table_args[-1]
else:
args = table_args
autoload = dict_.get("__autoload__")
if autoload:
table_kw["autoload"] = True
cls.__table__ = table = table_cls(
tablename,
cls.metadata,
*(tuple(declared_columns) + tuple(args)),
**table_kw
)
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
而 Column 是通过下面的函数实现:
def _add_attribute(cls, key, value):
if "__mapper__" in cls.__dict__:
if isinstance(value, Column):
_undefer_column_name(key, value)
cls.__table__.append_column(value)
cls.__mapper__.add_property(key, value)
...
else:
type.__setattr__(cls, key, value)
2
3
4
5
6
7
8
9
10
Model 通过上面的方式,隐式创建了 Schema(Table),实际使用过程中只需要使用 Model 类,不用关注 Schema 的定义。
session 的源码由于篇幅和时间有限,留待以后再行分析
# 小结
sqlalchemy 可以在低层次上提供了 sql 语句的方式使用;在次层次上提供定义 schema 方式使用;在高层次上提供 orm 的实现,让应用可以根据项目的特点自主选择不同层级的 API。
使用 schema 时候,主要使用 Metadata,Table 和 Column 等定义 Schema 数据结构,使用编译器自动将 schema 转换成合法的 sql 语句。
使用 orm 的时候,则是创建特定的数据模型,模型对象会隐式创建 schema,通过 session 方式进行数据访问。
最后再回顾一下 sqlalchemy 的架构图:
# 小技巧
sqlalchemy 中提供了一个动态创建类的方式,主要在 declarative_base 和 DeclarativeMeta 中实现。我参考这个实现方式做了一个类工厂:
class DeclarativeMeta(type):
def __init__(cls, klass_name, bases, dict_):
print("class_init", klass_name, bases, dict_)
type.__init__(cls, klass_name, bases, dict_)
def get_attr(self, key):
print("getattr", self, key)
return self.__dict__[key]
def constructor(self, *args, **kwargs):
print("constructor", self, args, kwargs)
for k, v in kwargs.items():
setattr(self, k, v)
def dynamic_class(name):
class_dict = {
"__init__": constructor,
"__getattr__": get_attr
}
return DeclarativeMeta(name, (object,), class_dict)
DummyModel = dynamic_class("Dummy")
dummy = DummyModel(1, name="hello", age=18)
print(dummy, type(dummy), dummy.name, dummy.age)
# class_init Dummy (<class 'object'>,) {'__init__': <function test_dynamic_class.<locals>.constructor at 0x7f898827ef70>, '__getattr__': <function test_dynamic_class.<locals>.get_attr at 0x7f89882105e0>}
# constructor <sample.Dummy object at 0x7f89882a5820> (1,) {'name': 'hello', 'age': 18}
# <sample.Dummy object at 0x7f89882a5820> <class 'sample.Dummy'> hello 18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
示例中我动态创建了一个 DummyModel 类,type(dummy)可以看到,这个类名是 Dummy。这个类可以的构造函数可以接受 name 和 age 两个属性。这种创建方式和 collections.namedtuple 有点类似。
# 一点感悟
sqlalchemy 的源码非常复杂,前前后后一共准备了一个月,形成的 2 篇文档仅仅涉及核心流程和用法,细节部分缺失较多,以后有机会还需要继续阅读。在这一个月中,克服了工作较忙,没有时间写稿的烦躁;克服了阅读进入困境,一度想放弃的心理障碍;克服了 deadline 临近,文稿还只是一个雏形,使用存稿顶替的羞愧;克服了笔记软件故障,写完的文稿丢失,完全重写的懊恼。战胜这些困难,最终还是得以完成,心理上有大满足。当然最大的收获还是对 ORM 中间件有了初步的了解,也希望梳理的 ORM 流程对大家有一定的帮助,如果获得大家的支持会更加满意♥️。
# 参考链接
https://docs.sqlalchemy.org/en/13/index.html
http://aosabook.org/en/sqlalchemy.html
https://nettee.github.io/posts/2016/SQLAlchemy-Architecture-Note/