Python 中 OOM(内存泄漏)问题的定位与分析
Python 中 OOM(内存泄漏)问题的定位与分析
在 Python 后端项目中,出现内存溢出(Out of Memory, OOM) 时,通常是由于内存泄漏或资源未正确释放导致。以下是系统化的原因分析与定位方法:
# 理论基础
# 一、初步确认内存问题
观察现象:
- 进程占用内存持续增长,直至被系统杀死(如
Killed日志)。 - 出现
MemoryError异常或服务性能严重下降。
- 进程占用内存持续增长,直至被系统杀死(如
监控工具:
- 系统级监控:
top、htop、ps(查看进程内存占用RES或%MEM)。 - Python 内置模块:
tracemalloc(跟踪内存分配)、resource(监控资源限制)。
tracemalloc示例如下:import tracemalloc tracemalloc.start() # ...运行代码... snapshot = tracemalloc.take_snapshot() top_stats = snapshot.statistics('lineno') for stat in top_stats[:10]: print(stat)1
2
3
4
5
6
7使用
sys.settrace函数设置一个跟踪函数,以便在程序运行期间跟踪内存使用情况。示例如下:
import sys def trace_memory(frame, event, arg): # 在这里记录内存使用情况 print(event, sys.getsizeof(arg)) sys.settrace(trace_memory) # 运行你的代码1
2
3
4
5
6
7
8
9- 系统级监控:
# 二、定位内存泄漏的核心步骤
# 1. 使用内存分析工具
工具选择:
objgraph:可视化对象引用关系,检测循环引用。memory_profiler:逐行分析内存增长。pympler:统计对象内存占用。guppy3(或heapy):分析堆内存对象。
示例(
memory_profiler):# 安装:pip install memory_profiler from memory_profiler import profile @profile def my_func(): a = [1] * 100000 b = [2] * 200000 return a + b if __name__ == "__main__": my_func()1
2
3
4
5
6
7
8
9
10
11输出结果:
Line # Mem usage Increment Occurrences Line Contents =========================================================== 4 38.5 MiB 38.5 MiB 1 @profile 5 def my_func(): 6 39.3 MiB 0.8 MiB 1 a = [1] * 100000 7 40.9 MiB 1.6 MiB 1 b = [2] * 200000 8 43.3 MiB 2.4 MiB 1 return a + b1
2
3
4
5
6
7guppy库中的hpy模块示例如下:from guppy import hpy h = hpy() # 在需要检查内存使用情况的地方调用h.heap()方法 print(h.heap())1
2
3
4
5
6使用
resource模块来设置进程的资源限制,例如设置虚拟内存限制、堆栈大小等。示例如下:import resource # 设置虚拟内存限制为1GB resource.setrlimit(resource.RLIMIT_AS, (1e9, -1))1
2
3
4在运行程序时使用
pympler.muppy和pympler.summary来获取内存快照和对象摘要信息。示例如下:from pympler import muppy, summary all_objects = muppy.get_objects() sum1 = summary.summarize(all_objects) summary.print_(sum1)1
2
3
4
5以上方法可以帮助你找到 Python 程序内存不足的问题所在,并进行相应的调试和优化。
# 2. 检测循环引用
Python 的垃圾回收(GC)能处理大部分循环引用,但某些情况(如含__del__方法的对象)仍需手动干预。
使用
objgraph查找循环引用:import objgraph # 生成引用关系图(需安装graphviz) objgraph.show_backrefs(objgraph.by_type('MyClass'), filename='refs.png') # 统计前N个最多实例的类型 objgraph.show_most_common_types(limit=10) # 可视化对象引用关系,找出内存占用大户 objgraph.show_growth() # 查看增长最快的对象类型1
2
3
4
5
6
7
8
9
10
# 3. 分析大对象或缓存
检查全局变量或缓存:
- 全局字典、列表可能意外持有大对象。尝试减少程序所需的内存使用量,例如使用生成器而不是列表来迭代大量数据、使用适当的数据结构等。
- 分块处理:对大文件或数据集进行分批处理,例如:
with open('large_file.txt') as f: for chunk in iter(lambda: f.read(1024), ''): process(chunk)1
2
3 - 缓存未设置过期策略(如使用
functools.lru_cache未限制maxsize)。
# 错误的缓存使用:未限制大小 @lru_cache(maxsize=None) def heavy_calculation(x): return x ** x1
2
3
4
# 4. 检查第三方库或 C 扩展
- C 扩展模块:如
numpy、pandas处理大数据时未释放内存。- 显式调用
.close()或del释放资源。
- 显式调用
- 数据库连接池未回收:如 SQLAlchemy 连接未正确关闭。
# 三、常见内存泄漏场景
# 1. 未释放文件/网络资源
# 错误:未关闭文件句柄
def read_large_file():
f = open('huge.log', 'r')
return f.read()
# 正确:使用上下文管理器
def read_large_file():
with open('huge.log', 'r') as f:
return f.read()
2
3
4
5
6
7
8
9
# 2. 循环引用 + 无法被 GC 回收
class Node:
def __init__(self):
self.parent = None
# 创建循环引用
a = Node()
b = Node()
a.parent = b
b.parent = a
# 即使del后,若对象有__del__方法,GC可能无法回收
del a, b
2
3
4
5
6
7
8
9
10
11
12
# 3. 线程或异步任务未终止
- 后台线程或协程持续运行,持有对象引用。
# 四、高级诊断方法
# 1. 使用gc模块调试
import gc
# 手动触发垃圾回收
gc.collect()
# 查看无法回收的对象
gc.garbage # 列表显示无法回收的对象
2
3
4
5
6
7
# 2. 生成内存快照对比
通过多次快照对比,找出内存增长点:
import tracemalloc
tracemalloc.start()
snapshot1 = tracemalloc.take_snapshot()
# 执行怀疑有泄漏的代码
run_suspected_code()
snapshot2 = tracemalloc.take_snapshot()
top_stats = snapshot2.compare_to(snapshot1, 'lineno')
for stat in top_stats[:10]:
print(stat)
2
3
4
5
6
7
8
9
10
11
12
13
# 3. 使用 Valgrind(Linux)
针对 Python 的 C 扩展内存泄漏:
valgrind --tool=memcheck --suppressions=python.supp python3 my_script.py
# 五、修复与预防
- 修复代码:
- 使用上下文管理器(
with语句)管理资源。 - 避免全局变量长期持有大对象。
- 对缓存设置大小限制和过期时间。
- 使用上下文管理器(
- 优化数据结构:
- 使用生成器(
yield)替代列表处理大数据。 - 使用
numpy/pandas时及时释放内存。
- 使用生成器(
- 监控与报警:
集成 Prometheus + Grafana 监控进程内存。
使用
psutil定时上报内存使用:import psutil process = psutil.Process() print(process.memory_info().rss) # 获取物理内存占用1
2
3
# 六、工具链总结
| 工具 | 用途 |
|---|---|
tracemalloc | 定位内存分配位置 |
memory_profiler | 逐行分析内存增长 |
objgraph | 可视化对象引用关系 |
gc | 手动触发垃圾回收并检查不可回收对象 |
pympler | 统计对象内存占用 |
# 七、案例实战
场景:一个 FastAPI 服务处理大文件上传后内存不释放。
分析步骤:
使用
memory_profiler发现上传接口内存激增。发现代码中将文件内容存入全局列表:
uploaded_files = [] @app.post("/upload") async def upload(file: UploadFile): content = await file.read() uploaded_files.append(content) # 内存泄漏!1
2
3
4
5
6
修复方案:
- 移除全局列表,改为处理完立即释放。
- 使用临时文件或流式处理。
# 总结
- 核心思路:监控 → 定位 → 分析 → 修复 → 预防。
- 关键点:优先检查全局变量、缓存、资源释放,结合工具快速缩小范围。
- Python 特性:虽然自动内存管理,但开发者仍需注意对象生命周期和外部资源管理。
# 更多实战案例
# 监测新旧版本内存变化差异
目前python常用的内存检测工具有pympler、objgraph、tracemalloc 等。
首先,通过objgraph工具,对新旧服务中的 TOP50 变量类型进行了观察统计
objraph常用命令如下:
# 全局类型数量
objgraph.show_most_common_types(limit=50)
# 增量变化
objgraph.show_growth(limit=30)
2
3
4
5
这里为了更好的观测变化曲线,我简单做了个封装,使数据直接输出到了 csv 文件以便观察。
stats = objgraph.most_common_types(limit=50)
stats_path = "./types_stats.csv"
tmp_dict = dict(stats)
req_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
tmp_dict['req_time'] = req_time
df = pd.DataFrame.from_dict(tmp_dict, orient='index').T
if os.path.exists(stats_path):
df.to_csv(stats_path, mode='a', header=True, index=False)
else:
df.to_csv(stats_path, index=False)
2
3
4
5
6
7
8
9
10
11
如下图所示,用一批图片在新旧两个版本上跑了 1 个小时,一切稳如老狗,各类型的数量没有一丝波澜。
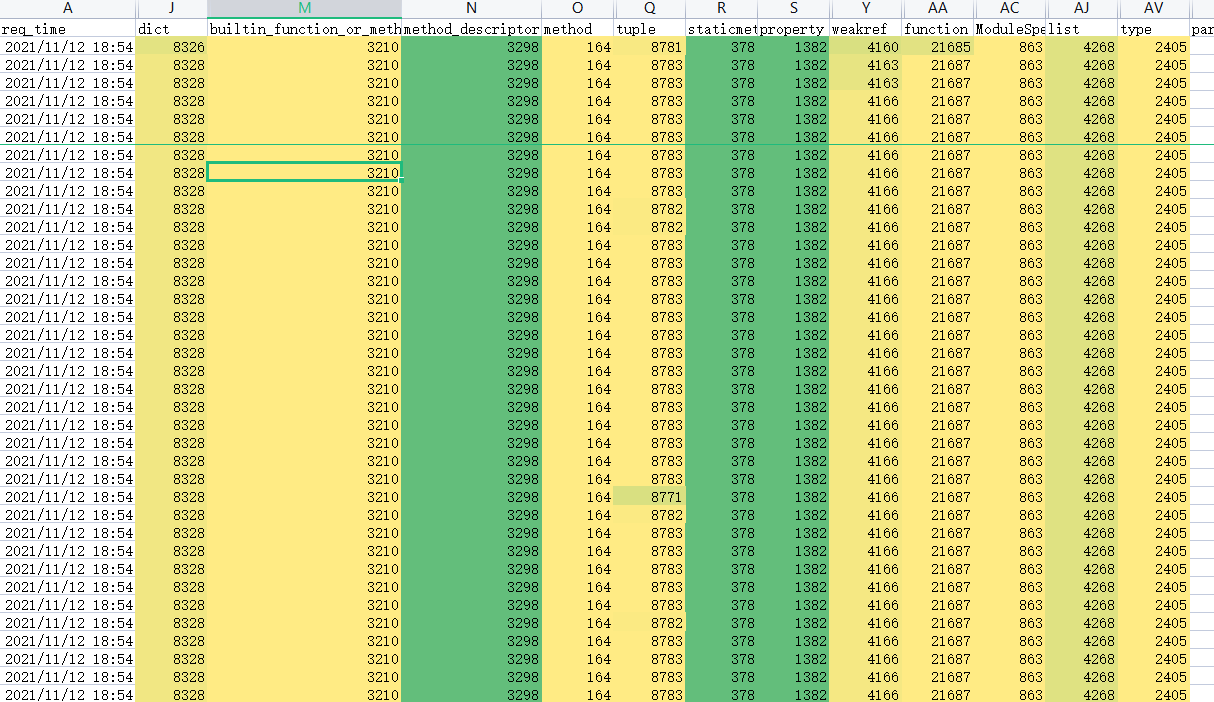
此时,想到自己一般在转测或上线前都会将一批异常格式的图片拿来做个边界验证。
虽然这些异常,测试同学上线前肯定都已经验证过了,但死马当成活马医就顺手拿来测了一下。
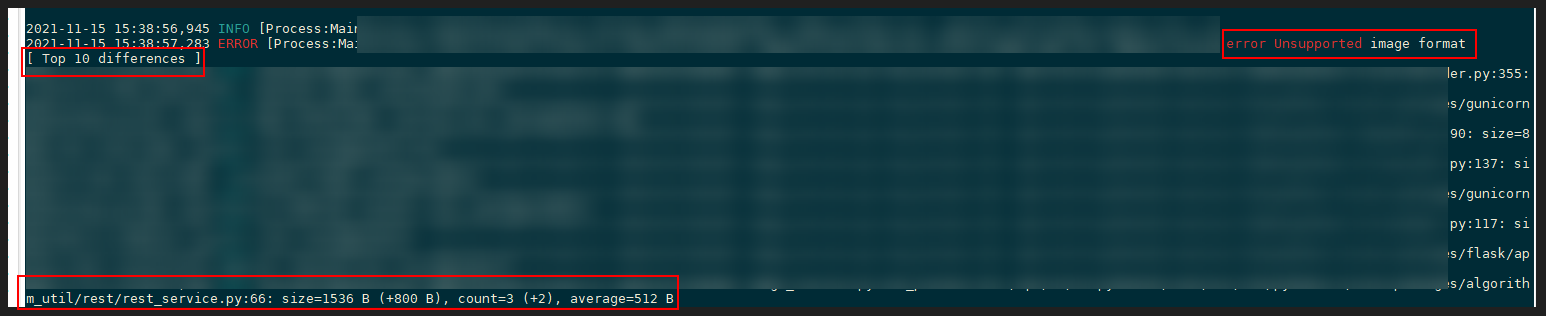
平静数据就此被打破了,如下图红框所示:dict、function、method、tuple、traceback 等重要类型的数量开始不断攀升。

而此时镜像内存亦不断增加且毫无收敛迹象。
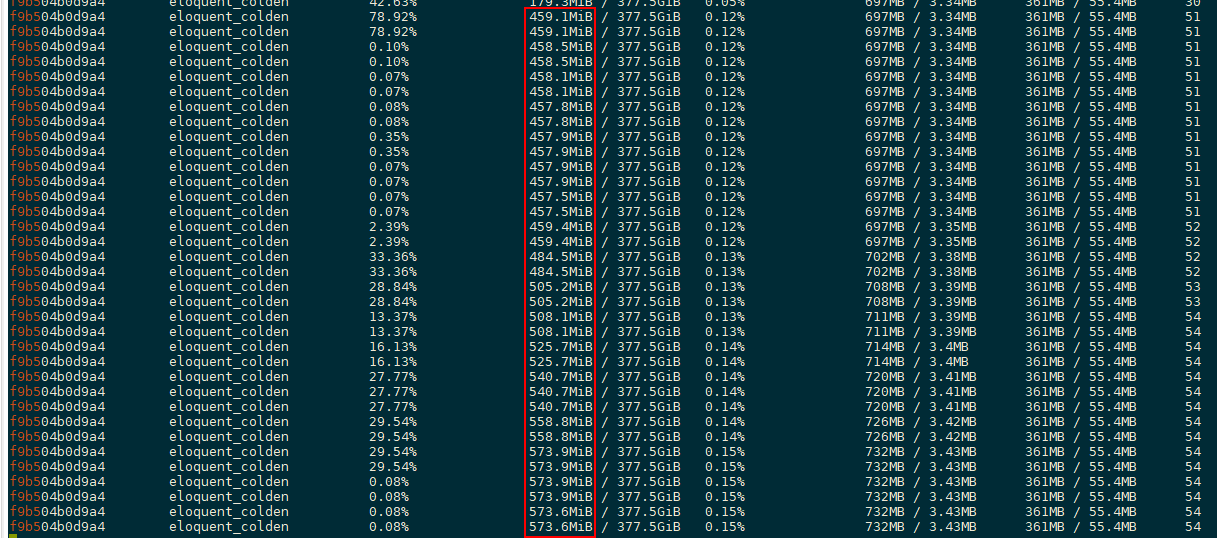
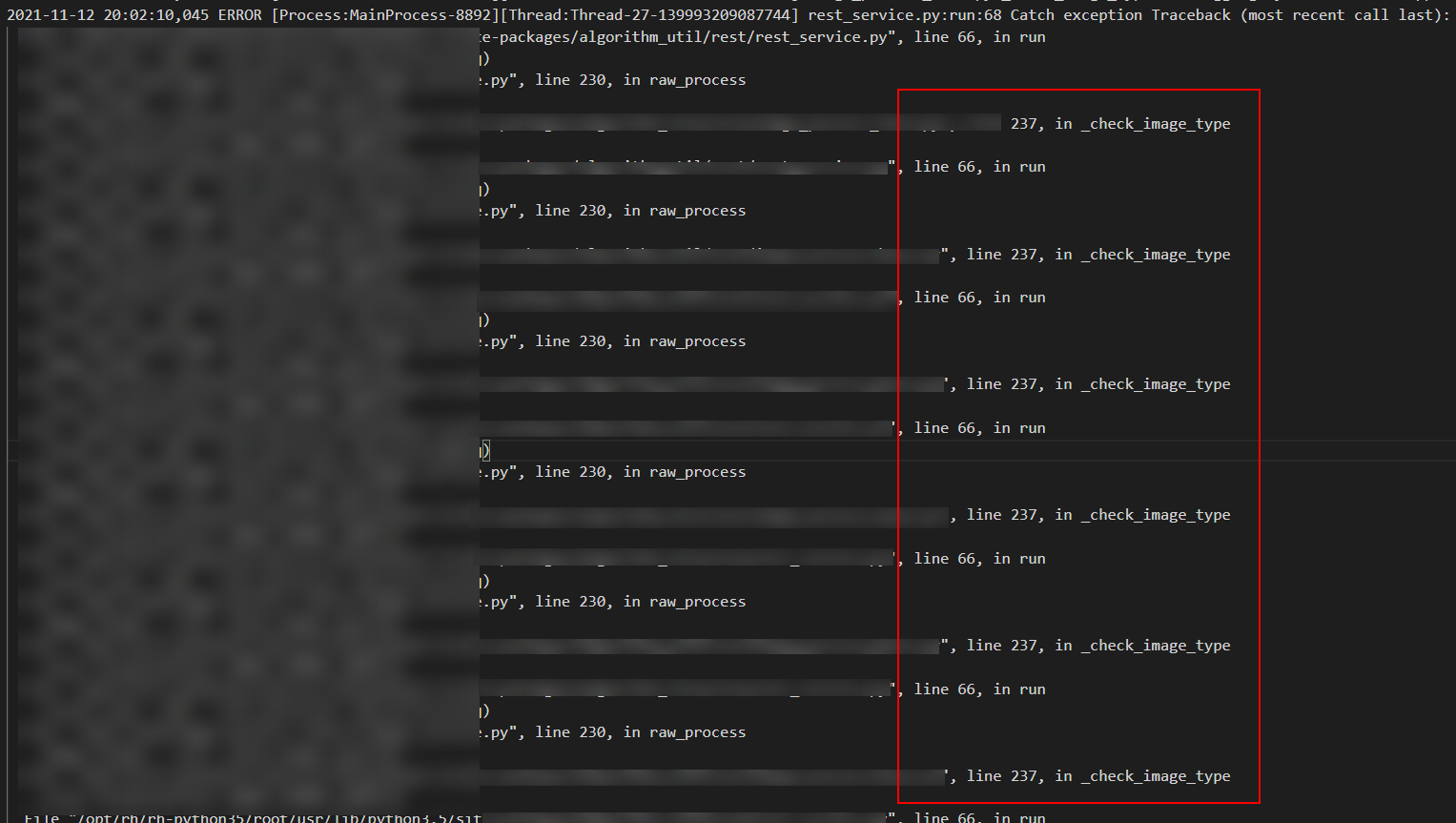
由此,虽无法确认是否为线上问题,但至少定位出了一个 bug。而此时回头检查日志,发现了一个奇怪的现象:
正常情况下特殊图片导致的异常,日志应该输出如下信息,即 check_image_type 方法在异常栈中只会打印一次。

但现状是 check_image_type 方法循环重复打印了多次,且重复次数随着测试次数在一起变多。
重新研究了这块儿的异常处理代码。
异常声明如下:

抛异常代码如下:

# 问题所在
思考后大概想清楚了问题根源:
这里每个异常实例相当于被定义成了一个全局变量,而在抛异常的时候,抛出的也正是这个全局变量。当此全局变量被压入异常栈处理完成之后,也并不会被回收。
因此随着错误格式图片调用的不断增多,异常栈中的信息也会不断增多。而且由于异常中还包含着请求图片信息,因此内存会呈 MB 级别的增加。
但这部分代码上线已久,线上如果真的也是这里导致的问题,为何之前没有任何问题,而且为何在 A 芯片上也没有出现任何问题?
带着以上两个疑问,我们做了两个验证:
首先,确认了之前的版本以及 A 芯片上同样会出现此问题。
其次,我们查看了线上的调用记录,发现最近刚好新接入了一个客户,而且出现了大量使用类似问题的图片调用某局点(该局点大部分为 B 芯片)服务的现象。我们找了些线上实例,从日志中也观测到了同样的现象。
由此,以上疑问基本得到了解释,修复此 bug 后,内存溢出问题不再出现。
# 进阶思路
讲道理,问题解决到这个地步似乎可以收工了。但我问了自己一个问题,如果当初没有打印这一行日志,或者开发人员偷懒没有把异常栈全部打出来,那应该如何去定位?
带着这样的问题我继续研究了下 objgraph、pympler 工具。
前文已经定位到了在异常图片情况下会出现内存泄漏,因此重点来看下此时有哪些异样情况:
通过如下命令,我们可以看到每次异常出现时,内存中都增加了哪些变量以及增加的内存情况。
使用
objgraph工具objgraph.show_growth(limit=20)1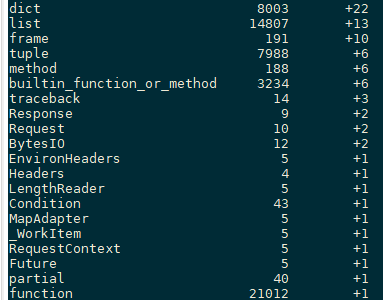
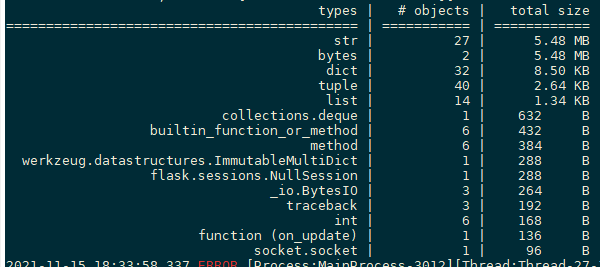
使用
pympler工具
from pympler import tracker
tr = tracker.SummaryTracker()tr.print_diff()
2
通过如下代码,可以打印出这些新增变量来自哪些引用,以便进一步分析。
gth = objgraph.growth(limit=20)
for gt in gth:
logger.info("growth type:%s, count:%s, growth:%s" % (gt[0], gt[1], gt[2]))
if gt[2] > 100 or gt[1] > 300:
continue
objgraph.show_backrefs(objgraph.by_type(gt[0])[0], max_depth=10, too_many=5,
filename="./dots/%s_backrefs.dot" % gt[0])
objgraph.show_refs(objgraph.by_type(gt[0])[0], max_depth=10, too_many=5,
filename="./dots/%s_refs.dot" % gt[0])
objgraph.show_chain(
objgraph.find_backref_chain(objgraph.by_type(gt[0])[0], objgraph.is_proper_module),
filename="./dots/%s_chain.dot" % gt[0]
)
2
3
4
5
6
7
8
9
10
11
12
13
通过graphviz的 dot 工具,对上面生产的 graph 格式数据转换成如下图片:
dot -Tpng xxx.dot -o xxx.png
这里,由于dict、list、frame、tuple、method等基本类型数量太多,观测较难,因此这里先做了过滤。
内存新增的ImageReqWrapper的调用链
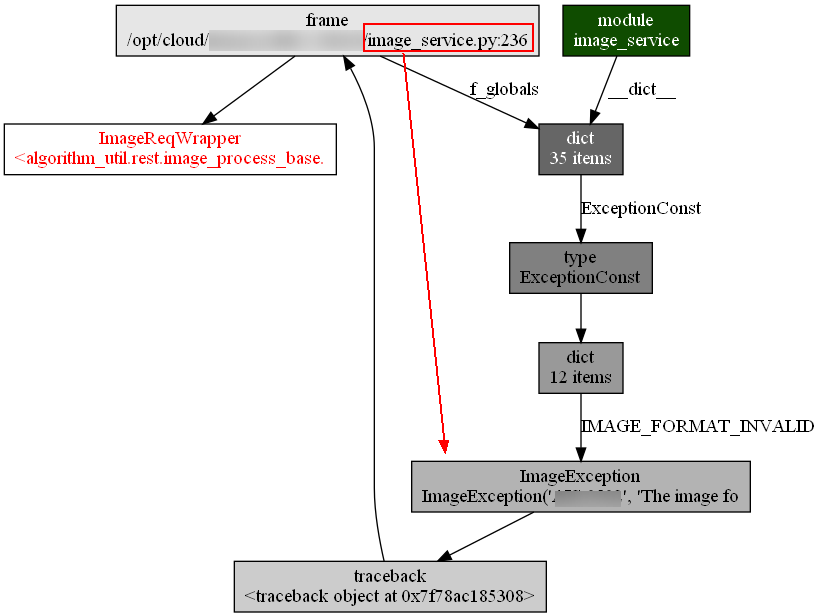
内存新增的 traceback 的调用链:
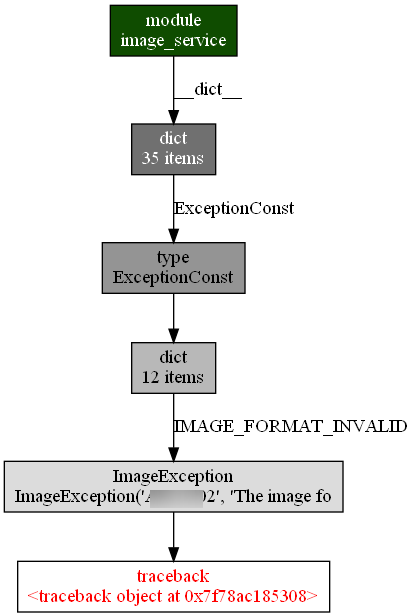
虽然带着前面的先验知识,使我们很自然的就关注到了traceback和其对应的IMAGE_FORMAT_EXCEPTION异常。
但通过思考为何上面这些本应在服务调用结束后就被回收的变量却没有被回收,尤其是所有的traceback变量在被IMAGE_FORMAT_EXCEPTION异常调用后就无法回收等这些现象;同时再做一些小实验,相信很快就能定位到问题根源。
另,关于 python3中 缓存Exception导致的内存泄漏问题,知乎有一篇讲的相对更清楚一点:https://zhuanlan.zhihu.com/p/38600861 (opens new window)
至此,我们可以得出结论如下:
由于抛出的异常无法回收,导致对应的异常栈、请求体等变量都无法被回收,而请求体中由于包含图片信息因此每次这类请求都会导致 MB 级别的内存泄漏。
另外,研究过程中还发现python3自带了一个内存分析工具tracemalloc,通过如下代码就可以观察代码行与内存之间的关系,虽然可能未必精确,但也能大概提供一些线索。
import tracemalloc
tracemalloc.start(25)
snapshot = tracemalloc.take_snapshot()
global snapshot
gc.collect()
snapshot1 = tracemalloc.take_snapshot()
top_stats = snapshot1.compare_to(snapshot, 'lineno')
logger.warning("[ Top 20 differences ]")
for stat in top_stats[:20]:
if stat.size_diff < 0:
continue
logger.warning(stat)
snapshot = tracemalloc.take_snapshot()
2
3
4
5
6
7
8
9
10
11
12
13
14