 途游面试
途游面试
python 生成器,迭代器,装饰器
strip/lstrip/rstrip 用法
strip: 用来去除头尾字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格) lstrip:用来去除开头字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格) rstrip:用来去除结尾字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格)
当字符为空时
>>> str = ' ab cd ' >>> str ' ab cd ' >>> str.strip() #删除头尾空格 'ab cd' >>> str.lstrip() #删除开头空格 'ab cd ' >>> str.rstrip() #删除结尾空格 ' ab cd'1
2
3
4
5
6
7
8
9当切割字符不为空
>>> str2 = '1a2b12c21' >>> str2.strip('12') #删除头尾的1和2 'a2b12c' >>> str2.lstrip('12') #删除开头的1和2 'a2b12c21' >>> str2.rstrip('12') #删除结尾的1和2 '1a2b12c'1
2
3
4
5
6
7
map/reduce/filter 用法
解释并实现单例模式
查看 linux 版本如何查看,几种方法
cat /etc/redhat-release /proc/version uname -r1
2
3如何查看 linux 系统的配置?什么时候生效的?
# cpu cat /proc/cpuinfo # memory cat /proc/meminfo # disk lsblk1
2
3
4
5
6说下 python 中的生成器如何实现的?
生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。它不需要再像类一样写
__iter__()和__next__()方法了,只需要一个yiled关键字。 生成器一定是迭代器(反之不成立),因此任何生成器也是以一种懒加载的模式生成值。 列表生成式,range,yield Python 面试 | 别院牧志知识库yield 如何实现的,是什么?
Python yield 关键字在 C 层面是如何实现的 (opens new window)
我们先看一个 python 生成器函数的例子:
from dis import dis def func(): i = 4 yield i print i dis(func) a =func() a.next() a.next()1
2
3
4
5
6
7
8
9
10
11
12使用 python 的库 dis 可以直接查看 python 虚拟机运行的字节码。
dis(func)的打印如下:6 0 LOAD_CONST 1 (4) 3 STORE_FAST 0 (i) 7 6 LOAD_FAST 0 (i) 9 YIELD_VALUE 10 POP_TOP 8 11 LOAD_FAST 0 (i) 14 PRINT_ITEM 15 PRINT_NEWLINE 16 LOAD_CONST 0 (None) 19 RETURN_VALUE1
2
3
4
5
6
7
8
9
10
11
12
13我们猜测其中第二列(代表字节码偏移量)为 9 的指令
YIELD_VALUE就是 yield 关键字的执行代码,进入 Python2.7.12 源码目录,在解释器执行字节码的主函数PyEval_EvalFrameEx中找到了下面一段:TARGET_NOARG(YIELD_VALUE) { retval = POP(); f->f_stacktop = stack_pointer; why = WHY_YIELD; // 跳转到fast_yield处。fast_yield里处理了一下状态位然后返回结果 goto fast_yield; }1
2
3
4
5
6
7
8
9其中
TARGET_NOARG为封装了case语句的宏,这句话的意思是,如果字节码是YIELD_VALUE,就把栈顶元素赋值给retval,然后跳转到fast_yield处,fast_yield处代码进行了一些状态判断后直接返回了retval。生成器是如何记录代码返回位置的
显然,如果这时候调用代码
a.next()就会直接返回 yield 后边的表达式结果。这对应了上面 C 代码的fast_yield部分,那生成器怎么记录上次执行的位置并在下一次调用a.next()的时候从上次的位置继续执行的呢?Python 在解释代码时,是将代码块加载为一个叫 PyFrameObject 的对象,这个对象代表了当前运行的栈帧。PyFrameObject 里有个
f_lasti变量用于保存代码当前执行到了字节码的哪个位置。在第二次执行a.next()时,生成器对象把之前携带了f_lasti的 PyFrameObject 当参数传给PyEval_EvalFrameEx,在PyEval_EvalFrameEx里的执行一个 JUMPTO 就直接跳转到了上一次结束生成器时的字节码位置:PyObject * PyEval_EvalFrameEx(PyFrameObject *f, int throwflag) { ... #define FAST_DISPATCH() \ { \ if (!lltrace && !_Py_TracingPossible) { \ f->f_lasti = INSTR_OFFSET(); \ goto *opcode_targets[*next_instr++]; \ } \ // 跳转到fast_next_opcode处 goto fast_next_opcode; \ } ... fast_next_opcode: f->f_lasti = INSTR_OFFSET(); /* line-by-line tracing support */ if (_Py_TracingPossible && tstate->c_tracefunc != NULL && !tstate->tracing) { ... /* Reload possibly changed frame fields */ // 按照f->f_lasti中的偏移量跳转字节码 JUMPTO(f->f_lasti); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26其中
INSTR_OFFSET宏正是字节码的偏移量。#define INSTR_OFFSET() ((int)(next_instr - first_instr)) // co->co_code里保存的是字节码 first_instr = (unsigned char*) PyString_AS_STRING(co->co_code); next_instr = first_instr + f->f_lasti + 1;1
2
3
4
5所以生成器对象每次执行结束都把字节码的偏移量记录下来,并把运行状态保存在 PyFrameObject 里,下一次运行时生成器时,python 解释器直接按照偏移量寻找下一个字节码指令。
说下你如何存放用户头像的,数据库中如何存放的,字段是什么?
数据库对图片文件以 SHA512 作为 primary key,数据库里只存储 SHA512,然后在线存储的时候文件名使用 SHA512。
之所以选这么个方案原因如下:
1. 我们用 AWS S3 存储。(key-value 存储)
2. 假设是对于用户头像这类文件,文件名不重要,扩展名也不重要,因为显示在页面上唯一依赖的就是 URL 和 S3 服务器返回的 content-type header,而后者在上传的时候已经建立。
3. 要维持一致性,变量越少越好。比如说如果你要维持 1.jpg 和 `https://s3.bucket.com/1.jpg` 就没有维持 1.jpg 容易。对于 S3 来说,URL 大部分都是确定的,因此真正会变化的部分只是文件名(key 名)。
4. 因为扩展名不重要,所以维持 1.jpg 不如维持 1。
5. 因为文件名不重要,所以维持 1 不如维持文件指纹,也就是 MD5/SHA512 之类的。
6. 使用 SHA512 直接作为数据库主键、S3 Key 可以最小化需要一致性的变量。
7. 使用 SHA512 的更大的好处是免除了维持一致性的必要,因为 SHA512 的特性几乎可以认为一个特别的 SHA512 对应了一个特别的文件,因此算法天然保证了在任何地方对应同一个文件都有一致性,无论是 S3 Key,数据库还是别的地方。
事实上我们的系统使用这个方案存储所有文件,不只是用户头像。因为 SHA512 几乎与文件一一对应的特性从而天然维持了一致性,实在是太方便了。比如用这种存储如果两个用户上传了同一个图片做头像,那你就直接避免了重复存储的问题(它们会有相同的键值)。_代价是对于删除处理你需要采用别的策略判断依赖性,比如只有在一个文件不被任何地方引用的时候才能删除。_
参见:[数据库字段应该如何储存用户头像 URL? - 知乎](https://www.zhihu.com/question/333821544)
你的 uwsgi 怎么用的多线程实现的
手写个代码 :迷宫问题
关联查询 join 什么时候用?
JOIN 在内连接时,可以不使用,其它类型连接必须使用。如:
SELECT * FROM TABLEA INNER JOIN TABLEB ON A.ID=B.ID1可以这样写:
SELECT * FROM TABLEA,TABLEB WHERE A.ID=B.ID1JOIN 有以下几种类型:
- INNER(内连接)
指定返回每对匹配的行。废弃两个表中不匹配的行。如果未指定联接类型,则这是默认设置。
- FULL(全连接)
指定在结果集中包含左表或右表中不满足联接条件的行,并将对应于另一个表的输出列设为 NULL。这是对通常由 INNERJOIN 返回的所有行的补充。
- LEFT(左连接)
指定在结果集中包含左表中所有不满足联接条件的行,且在由内联接返回所有的行之外,将另外一个表的输出列设为 NULL。
- RIGHT(右连接)
指定在结果集中包含右表中所有不满足联接条件的行,且在由内联接返回的所有行之外,将与另外一个表对应的输出列设为 NULL。
- CROSS JOIN(交叉连接)
得到连接表符合 WHERE 子句的条件的记录数的乘积,即第一个表的每一个记录都与别一个表的所有记录连接出一个新的记录。
交叉连接不带 ON 子句,其它连接必须有 ON 子句。
存储过程是怎么实现的?
procedure 英[prəˈsiːdʒə(r)] 美[prəˈsiːdʒər]1我们常用的操作数据库语言 SQL 语句在执行的时候需要要先编译,然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的 SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。
一个存储过程是一个可编程的函数,它在数据库中创建并保存。它可以有 SQL 语句和一些特殊的控制结构组成。当希望在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看做是对编程中面向对象方法的模拟。它允许控制数据的访问方式。
存储过程通常有以下优点:
- 存储过程增强了 SQL 语言的功能和灵活性。存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
- 存储过程允许标准组件是编程。存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的 SQL 语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
- 存储过程能实现较快的执行速度。如果某一操作包含大量的 Transaction-SQL 代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的 Transaction-SQL 语句在每次运行时都要进行编译和优化,速度相对要慢一些。
- 存储过程能过减少网络流量。针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的 Transaction-SQL 语句被组织程存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大增加了网络流量并降低了网络负载。
- 存储过程可被作为一种安全机制来充分利用。系统管理员通过执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
- 语法
CREATE [DEFINER = { user | CURRENT_USER }] PROCEDURE sp_name ([proc_parameter[,...]]) [characteristic ...] routine_body proc_parameter: [ IN | OUT | INOUT ] param_name type characteristic: COMMENT 'string' | LANGUAGE SQL | [NOT] DETERMINISTIC | { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } | SQL SECURITY { DEFINER | INVOKER } routine_body: Valid SQL routine statement [begin_label:] BEGIN [statement_list] …… END [end_label]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22索引如何实现的?什么时候用索引,什么时候不用索引?
简单做下自我介绍,
说一下你开发过的项目,挑一个说下你都做了什么模块与功能
你了解过我们公司吗? 我们公司开发的游戏,你玩过吗?
如果你需要学习一种新技术,你会怎么做?
分析问题,确定要学习的内容(最重要的部分)
重复练习
与已知知识找相关联性
文档、书籍、论坛……
实践、分享
你之前的公司几点上班? 有加班吗?
你会前端吗? 你公司前后端分离吗?
你常用的数据库有哪些?
你开发的这个项目上线了吗? 每天的访问量是多少? 数据库中有多少用户?
python 的数据类型? str,Number(数字)Python3 支持 int、float、bool、complex(复数),list,set,tuple,dict Python3 基本数据类型 | 菜鸟教程 (opens new window)
你之前的项目是在什么开发环境上进行开发的? 怎么进行部署的?
说一下你的某个项目中,数据库中有哪些表? 举例说明表与表是怎么进行关联的?
你有什么问题想要问我的吗?
- 网络的七层协议、HTTP、TCP、IP 各在哪一层?
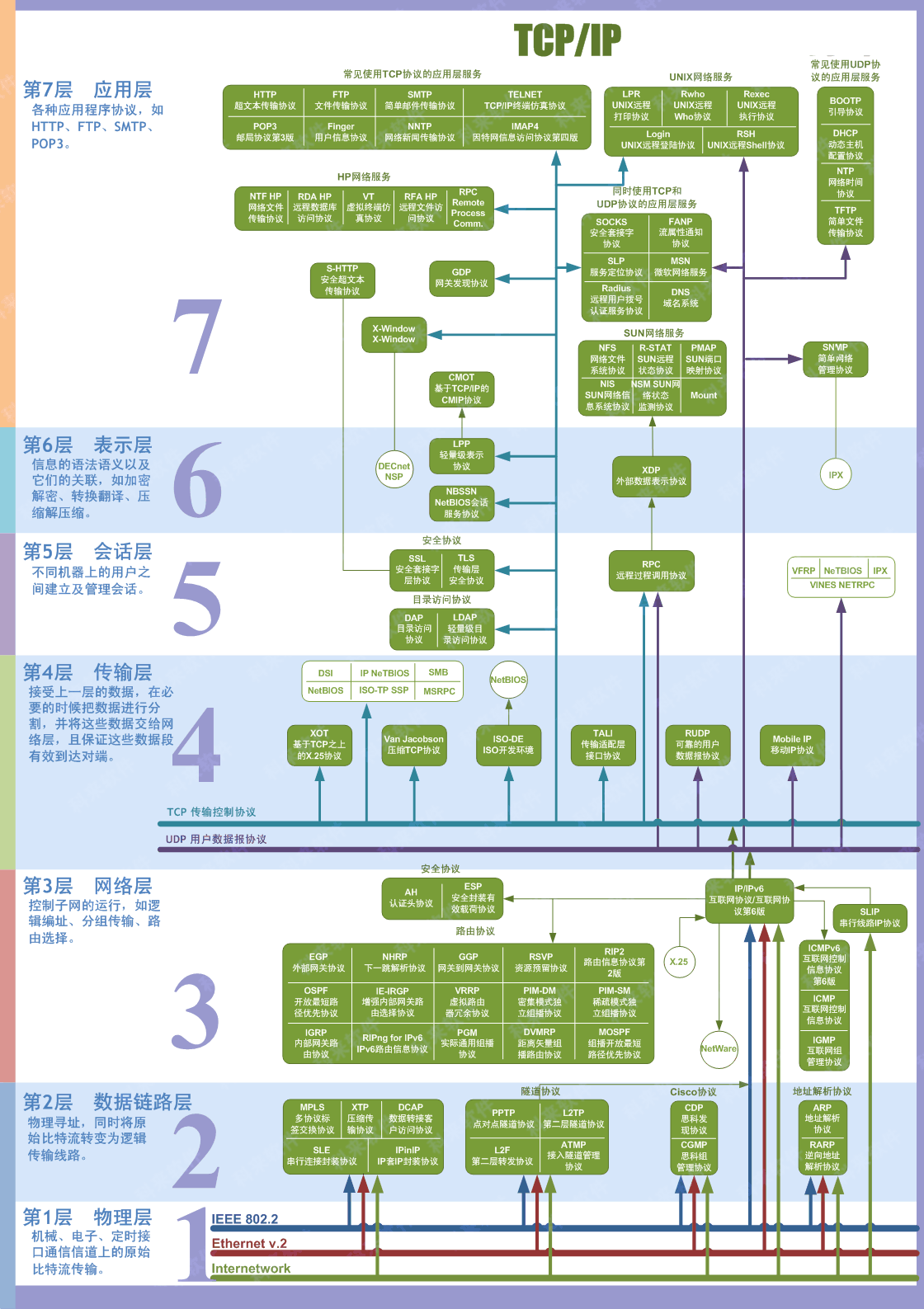
来源:科来网络通讯协议图免费下载 (opens new window)
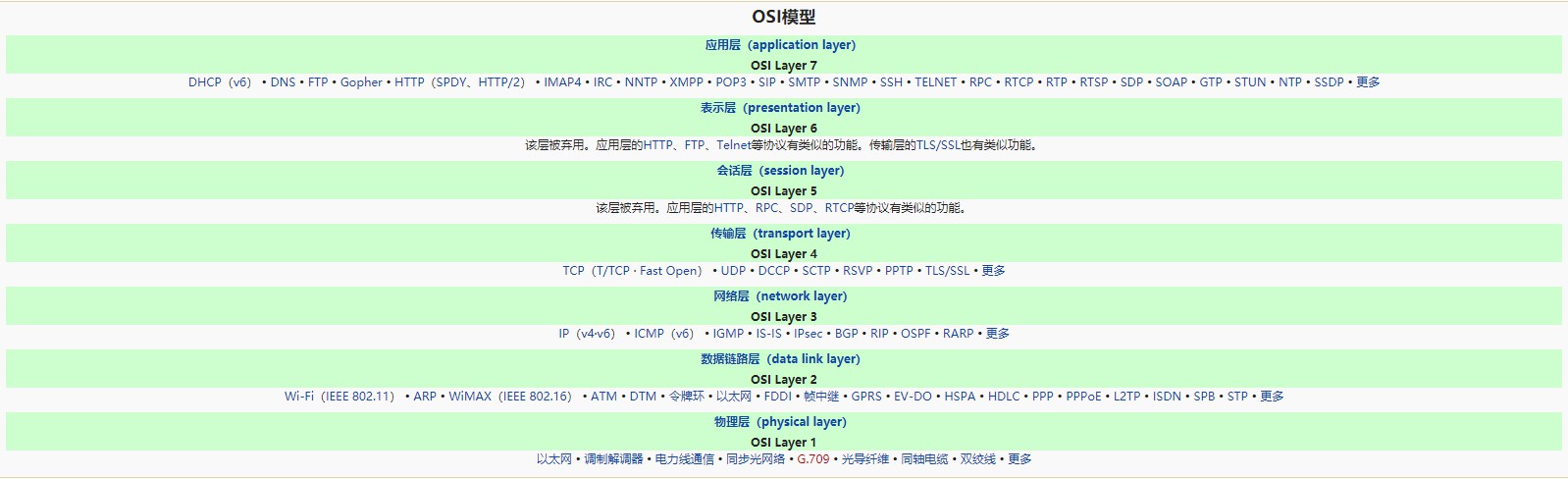
IP 协议位于网络层,TCP/UDP 协议位于传输层,HTTP 位于应用层。
- HTTP 与 TCP 的区别? TPC/IP 协议是传输层协议,主要解决数据如何在网络中传输;而 HTTP 是应用层协议,主要解决如何包装数据。
- restful 风格 Representational State Transfer:(资源)表现层状态转移
- 假如你的数据库版本是 1.0 的,一张表的字段个数为 10 个。那么现在用的版本是 1.1 的,想要在表中进行增删改查,有哪些方式? (我当时懵了,直接说了句我修改了数据库脚本,然后人家就问我除了这种方式,还有呢?)
- redis 中有哪些数据类型? hash 类型怎么设置值? Redis | 别院牧志 (opens new window)
- 非关系型数据库,例如 Mongodb,怎么去关联两张表?
- 什么是解释器? 什么是编译器?
- 你用过 Python 的哪些版本?说一下 2.x 与 3.x 的不同 Python 2 和 Python 3 有哪些主要区别? - 知乎 (opens new window) Python2.x 与 3.x 版本区别 | 菜鸟教程 (opens new window)
- C++了解吗?
- 你怎样理解 Python 面向对象? 举例说明什么是多态? 说一下你是怎么实现 python 的封装的?
- 你在设计接口的时候,需要考虑哪些问题? 接口设计需要考虑哪些方面_weixin_34414196 的博客-CSDN 博客 (opens new window)
- 你做过类似优化的工作吗? (我当时顺口说了句数据库的优化),那么您是怎么进行数据库的优化的? 多线程
- 在多个用户同时发起对同一个商品的下单请求时,先查询商品库存,再修改商品库存,会出现资源竞争问题,导致库存的最终结果出现异常。 例如:id 为 16 的商品的库存为 10,两人同时购买,每人买 5 件,如果产生并发问题,两人下单都成功,但是库存变成了 5。怎么解决这个问题?
- GET 与 POST 的区别? POST 方法可以获取到数据吗? body 与 form 表单、data 的区别?
- 你用过的常见的算法有哪些?
- 什么是装饰器? 利用装饰器的好处? 手写一个装饰器
- 手写一个单例模式
- 你打印过 HTTP 吗?
- 你是怎么处理高并发问题的?
- 你的项目是怎么部署的?说一下一个项目部署的步骤 (根据简历的实际情况,我的是,Django+Nginx+Uwsgi) a. 说一下 Nginx 的特点 b. 一个请求进来的时候,你是怎么保证你的服务器是开启的? c.如果你的服务器是开启的,但是执行 sql 语句的代码发生了问题,会怎么样? 会发生什么?
- 对比一下 Django 和 Flask 有什么优缺点?
# 本人面试题目
基础知识
- tuple 和 list 区别并举例
- 深拷贝和浅拷贝的区别并举例 Python 全栈之路系列之深浅拷贝
- 列表推导式 内字典列表将字典的 value 组成新列表
a = [{'a':1,'b':2},{'a':1,'b':2},{'a':1,'b':2}] b = [ value for item in a for _,value in item.items() ] print(b) #[1, 2, 1, 2, 1, 2]1
2
3- Python2 与 Python3 的区别
shell
- 查找含有指定字符的文件名
find . -name 'foo'1- 查找含有指定字符内容的文件
# 查找当前目录下含有指定字符串的文件 find . -type f -print |xargs grep "python" ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/tests/test_utils_md4.py:# test pure-python MD4 implementation ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/tests/test_utils.py: # confirmed for: cpython 2.7.9, cpython 3.4, pypy, pypy3, pyston ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/tests/test_totp.py:# XXX: python 3 changed what error base64.b16decode() throws, from TypeError to base64.Error(). ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/tests/test_totp.py: # Workaround for python 3.6.0 issue -- ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/tests/test_totp.py: # (Appears to be bug http://bugs.python.org/issue29100) ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/tests/test_handlers.py: # https://github.com/bdd/fshp-is-not-secure-anymore/blob/master/python/test.py ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/tests/backports.py: # python 2.7 and python 3.2 both have unittest2 features (at least, the ones we use) ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/tests/test_crypto_builtin_md4.py:# test pure-python MD4 implementation ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/tests/test_crypto_builtin_md4.py: # not supported - ssl probably missing (e.g. ironpython) ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/tests/test_crypto_builtin_md4.py: # Temporarily make lookup_hash() use builtin pure-python implementation, ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/tests/test_crypto_scrypt.py: # (46s under pypy, ~5m under cpython) ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/passlib/_data/wordsets/eff_prefixed.txt:python # 查找指定文件中含有特定字符串的行 find . | grep config.xml | xargs grep "specified field" ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/flask/json/tag.py: def to_python(self, value): ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/flask/json/tag.py: def to_python(self, value): ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/flask/json/tag.py: def to_python(self, value): ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/flask/json/tag.py: def to_python(self, value): ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/flask/json/tag.py: return self.tags[key].to_python(value[key]) Binary file ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/flask/json/__pycache__/tag.cpython-37.pyc matches Binary file ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/flask/__pycache__/app.cpython-37.pyc matches Binary file ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/flask/__pycache__/cli.cpython-37.pyc matches Binary file ./.virtualenvs/iyblog-_wyXyExX/lib/python3.7/site-packages/flask/__pycache__/helpers.cpython-37.pyc matches # 查找当前目录中包含指定字段的所有文件(返回带颜色标识) grep -RnI "specified field" . --color ./.virtualenvs/iyblog/lib/python3.7/encodings/cp950.py:2:# cp950.py: Python Unicode Codec for CP950 ./.virtualenvs/iyblog/lib/python3.7/encodings/euc_jis_2004.py:2:# euc_jis_2004.py: Python Unicode Codec for EUC_JIS_2004 ./.virtualenvs/iyblog/lib/python3.7/encodings/euc_jisx0213.py:2:# euc_jisx0213.py: Python Unicode Codec for EUC_JISX0213 ./.virtualenvs/iyblog/lib/python3.7/encodings/euc_jp.py:2:# euc_jp.py: Python Unicode Codec for EUC_JP ./.virtualenvs/iyblog/lib/python3.7/encodings/euc_kr.py:2:# euc_kr.py: Python Unicode Codec for EUC_KR ./.virtualenvs/iyblog/lib/python3.7/encodings/gb18030.py:2:# gb18030.py: Python Unicode Codec for GB18030 ./.virtualenvs/iyblog/lib/python3.7/encodings/gb2312.py:2:# gb2312.py: Python Unicode Codec for GB2312 ./.virtualenvs/iyblog/lib/python3.7/encodings/gbk.py:2:# gbk.py: Python Unicode Codec for GBK ./.virtualenvs/iyblog/lib/python3.7/encodings/hex_codec.py:1:"""Python 'hex_codec' Codec - 2-digit hex content transfer encoding. ./.virtualenvs/iyblog/lib/python3.7/encodings/hp_roman8.py:1:""" Python Character Mapping Codec generated from 'hp_roman8.txt' with gencodec.py.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43编程 6.内字典列表中字典的指定 key 按照顺序排列(使用 lambda)
a_list.sort(key=lambda x:x.get('name'))1- 装饰器及其两种调用方式
数据库和 sql
redis 的存储类型及应用举例
用户充值表 pay_tb(uid,payment,time) 查询 2018 年充值金额总额小于 1 万元的用户的 uid 及其充值总额前 10 的数据
查询数据库电话号码并且将中间四位用**代替
CREATE TABLE users ( id varchar(300), name varchar(300), phone varchar(255) ); INSERT INTO users ( id , name , phone ) VALUES ('1', 'tom', '001-901-128-0479'), ('2', 'peter', '590-367-4360'), ('3', 'sam', '6716586922'), ('4', 'hans', '+1-319-510-3818-4500'); mysql> select * from users; +------+-------+----------------------+ | id | name | phone | +------+-------+----------------------+ | 1 | tom | 001-901-128-0479 | | 2 | peter | 590-367-4360 | | 3 | sam | 6716586922 | | 4 | hans | +1-319-510-3818-4500 | +------+-------+----------------------+ 4 rows in set (0.00 sec) # REPLACE + SUBSTR 方式 mysql> select id,name,REPLACE(phone,SUBSTR(phone,4,4),'****') as tel from users; +------+-------+----------------------+ | id | name | tel | +------+-------+----------------------+ | 1 | tom | 001****-128-0479 | | 2 | peter | 590****-4360 | | 3 | sam | 671****922 | | 4 | hans | +1-****510-3818-4500 | +------+-------+----------------------+ 4 rows in set (0.00 sec) # INSERT 方式 mysql> select id,name,INSERT(phone,4,4,'****') as tel from users; +------+-------+----------------------+ | id | name | tel | +------+-------+----------------------+ | 1 | tom | 001****-128-0479 | | 2 | peter | 590****-4360 | | 3 | sam | 671****922 | | 4 | hans | +1-****510-3818-4500 | +------+-------+----------------------+ 4 rows in set (0.01 sec)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49表达式解释:select+字段名+insert(手机号字段名,从第几位开始,替换几位,替换字符) as phoneNum from +表名;
参见:mysql sql 语句隐藏手机号码中间四位的方法_Mysql_脚本之家 (opens new window)
- 索引原则及 MySQL 除了 innoDB 之外的引擎并对比