 Redis 中的底层数据结构(5)——压缩链表(ziplist)
Redis 中的底层数据结构(5)——压缩链表(ziplist)
本文将详细说明 Redis 中压缩链表的实现。
在 Redis 源码(这里使用 3.2.11 版本)中,整数集合的实现在ziplist.h和ziplist.c中。
# 压缩链表概述
ziplist 是 Redis 列表键和哈希键的底层实现之一。当一个列表的每个列表项都是较小的整数或较短的字符串时,Redis 会使用 ziplist 作为底层实现。当一个哈希键只包含少量 key-value pair,且每个 key-value pair 的 key 和 value 为较小的整数或较短的字符串时,Redis 会使用 ziplist 作为底层实现。
在ziplist.c的注释中,我们可以知道 ziplist 的大致结构:
<zlbytes><zltail><zllen><entry><entry><zlend>
这几个部分的含义如下:
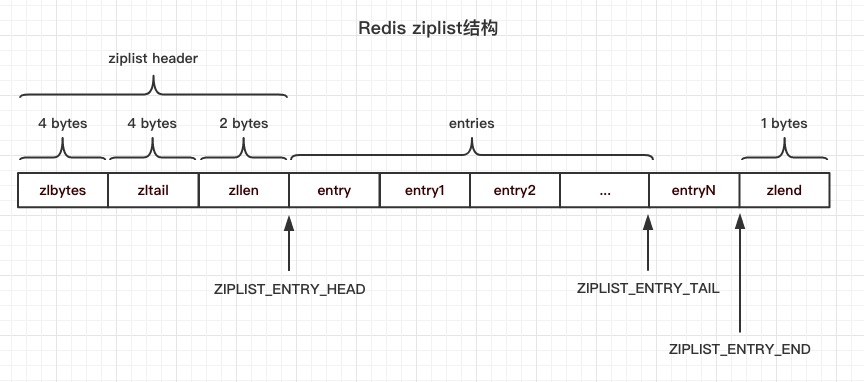
<zlbytes>:一个无符号整数,表示 ziplist 所占用的字节数。这个值让我们在调整 ziplist 的大小时无须先遍历它获得其大小。
<zltail>:链表中最后一个元素的偏移量。保存这个值可以让我们从链表尾弹出元素而无须遍历整个链表找到最后一个元素的位置。
<zllen>:链表中的元素个数。当这个值大于 2**16-2 时,我们需要遍历真个链表计算出链表中的元素数量。
<entry>:链表中的节点。稍后会详细说明节点的数据结构。
<zlend>:一个拥有特殊值255的字节,它标识链表结束。
同样,在ziplist.c的注释中,我们还可以发现下面几个宏,在注释中我们知道 ziplist 的结构细节:
// 获取ziplist占用的总字节数,ziplist在zip header的第0~3个字节保存了ZIP_BYTES
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
// 获取ziplist的尾节点偏移量,ziplist在zip header的第4~7个字节保存了ZIP_TAIL
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
// 获取ziplist的节点数量,ziplist在zip header的第8~9个字节保存了ZIP_LENGTH
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
// 获取ziplist的header大小,zip header中保存了ZIP_BYTES(uint32_t)、ZIP_TAIL(uint32_t)和ZIP_LENGTH(uint16_t),一共10字节
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// 获取ziplist的ZIP_END大小,是一个uint8_t类型,1字节
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
// 获取ziplist ZIP_ENTRY头节点地址,ZIP_ENTRY头指针 = ziplist首地址 + head大小
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
// 获取ziplist ZIP_ENTRY尾节点地址,ZIP_ENTRY尾指针 = ziplist首地址 + 尾节点偏移量
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
// 获取ziplist尾指针(ZIP_END),ziplist尾指针 = ziplist首地址 + ziplist占用的总字节数 - 1
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
上述代码告诉我们,<zlbytes>占用 4 字节,<zltail>占用 4 字节,<zllen>占用 2 字节,<zlend>\占用 1 字节,另外,<zlbytes> + <zltail> + <zllen>合起来称为 ziplist header,固定占用 10 字节,ZIPLIST_ENTRY_HEAD为头节点地址,ZIPLIST_ENTRY_TAIL为尾节点地址,ZIPLIST_ENTRY_END为尾指针,指向 ziplist 的<zlend>。我们根据这些细节可以画出 ziplist 更详细的结构图:
Redis ziplist 的数据结构示意图:
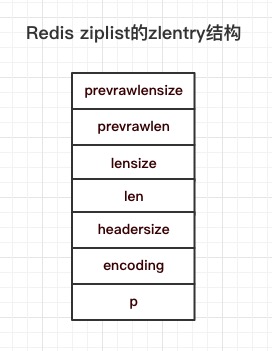
再来看看 ziplist 节点zlentry的定义:
// 压缩链表节点结构
typedef struct zlentry {
// prevrawlensize: 上一个节点的长度所占的字节数
// prevrawlen: 上一个节点的长度
unsigned int prevrawlensize, prevrawlen;
// lensize: 编码当前节点长度len所需要的字节数
// len: 当前节点长度
unsigned int lensize, len;
// 当前节点的header大小,headersize = lensize + prevrawlensize
unsigned int headersize;
// 当前节点的编码格式
unsigned char encoding;
// 当前节点指针
unsigned char *p;
} zlentry;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
可以得到zlentry的数据结构示意图:
关于 ziplist 的 zlentry,ziplist.c中提到:
ziplist 中每个节点都有一个 header 作为前缀,其中包含了两个字段。首先是前一个节点的长度,这个信息可以允许我们从后向前遍历 ziplist。第二个字段是节点的编码和节点存储的字符串长度。
前一个节点的长度使用如下方式来编码:
如果前一个节点的长度小于 254 字节,保存前一个节点的长度只需消耗 1 字节,长度值就是它的值。如果前一个节点长度大于或等于 254,编码它将占用 5 字节。其中第一个字节的值是 254,用来标识后面有一个更大的值,其余 4 个字节的值就表示前一个节点的长度。
header 中另一个字段的值依赖于节点的值。当节点的值是一个字符串,前两个 bit 将保存用于存储字符串长度的编码类型,后面是字符串的实际长度。当节点的值是一个整数时,前两个 bit 都为 1。之后的两个 bit 用来指出节点 header 后保存的整数的类型。下面是不同类型和编码的一个概括:
|00pppppp| - 1 byte 长度小于或等于 63 字节(2^6-1 字节)的字符串,保存其长度需要 6 bits。
|01pppppp|qqqqqqqq| - 2 bytes 长度小于或等于 16383 字节(2^14-1 字节)的字符串,保存其长度需要 14 bits。
|10______|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes 长度大于或等于 16384 字节的字符串,第一个 byte 的第 3~8 个 bit 的值没有含义,第一个 byte 后的 2~5 个 bytes 保存了其长度。
|11000000| - 1 byte
使用int16_t编码的整数,这个整数占用 2 字节。
|11010000| - 1 byte
使用int32_t编码的整数,这个整数占用 4 字节。
|11100000| - 1 byte
使用int64_t编码的整数,这个整数占用 8 字节。
|11110000| - 1 byte 使用 24 bits 编码的整数,这个整数占用 3 字节。
|11111110| - 1 byte 使用 8 bits 编码的整数,这个整数占用 1 字节。
|1111xxxx| - (其中 xxxx 的取值在 0000~1101 之间) 表示一个 4 bit 整数立即编码,表示的无符号整数范围为 0~12。但实际能编码的值为 1(0001)~13(1101),因为 0000 和 1111 不能使用。
|11111111| - ziplist 的结束符
注意:所有整数都已小端字节序表示。
zlentry 实际结构:
# 压缩链表数据结构
下面是ziplist.h中的函数原型:
unsigned char *ziplistNew(void); // 创建一个压缩链表
unsigned char *ziplistMerge(unsigned char **first, unsigned char **second); // 合并两个压缩链表
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where); // 向表头/表尾添加一个节点
unsigned char *ziplistIndex(unsigned char *zl, int index); // 获取索引值为index的节点
unsigned char *ziplistNext(unsigned char *zl, unsigned char *p); // 获取指定节点的下一个节点
unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p); // 获取指定节点的上一个节点
unsigned int ziplistGet(unsigned char *p, unsigned char **sval, unsigned int *slen, long long *lval); // 获取指定节点的信息
unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen); // 在指定节点后插入节点
unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p); // 删除指定节点
unsigned char *ziplistDeleteRange(unsigned char *zl, int index, unsigned int num); // 从指定的下标开始,删除num个节点
unsigned int ziplistCompare(unsigned char *p, unsigned char *s, unsigned int slen); // 比较两个节点的值
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip); // 查找指定节点
unsigned int ziplistLen(unsigned char *zl); // 获取链表长度
size_t ziplistBlobLen(unsigned char *zl); // 获取链表占用的总字节数
2
3
4
5
6
7
8
9
10
11
12
13
14
# 压缩链表实现
// ziplist结束标识
#define ZIP_END 255
#define ZIP_BIGLEN 254
/* 不同的编码/长度 */
// 字符串掩码 11000000
#define ZIP_STR_MASK 0xc0
// 整数掩码 00110000
#define ZIP_INT_MASK 0x30
// 字符串编码,后6位做为长度,字符串长度len<2^6 00XXXXXX,占用1字节
#define ZIP_STR_06B (0 << 6)
// 字符串编码,后14位做为长度,字符串长度len<2^14 01XXXXXX XXXXXXXX,占用2字节
#define ZIP_STR_14B (1 << 6)
// 字符串编码,后32位做为长度,字符串长度len<2^32 10000000 XXXXXXXX XXXXXXXX XXXXXXXX XXXXXXXX,占用5字节
#define ZIP_STR_32B (2 << 6)
// 16位整数编码,占用2字节,存储结构:11000000,范围-2^16~2^16-1
#define ZIP_INT_16B (0xc0 | 0<<4)
// 32位整数编码,占用4字节,存储结构:11010000,范围-2^32~2^32-1
#define ZIP_INT_32B (0xc0 | 1<<4)
// 64位整数编码,占用8字节,存储结构:11100000,范围-2^64~2^64-1
#define ZIP_INT_64B (0xc0 | 2<<4)
// 24位整数编码,占用3字节,存储结构:11110000,范围-2^24~2^24-1
#define ZIP_INT_24B (0xc0 | 3<<4)
// 8位整数编码,占用1字节,存储结构:11111110,范围-2^8~2^8-1
#define ZIP_INT_8B 0xfe
/* 4bit整数立即编码 */
// 4bit编码整数立即编码掩码 00001111
#define ZIP_INT_IMM_MASK 0x0f
// 4bit编码整数立即编码最小值 00001111
#define ZIP_INT_IMM_MIN 0xf1 /* 11110001 */
#define ZIP_INT_IMM_MAX 0xfd /* 11111101 */
// 获取4bit编码整数的值
#define ZIP_INT_IMM_VAL(v) (v & ZIP_INT_IMM_MASK)
// 24位整数最大值
#define INT24_MAX 0x7fffff
// 24位整数最小值
#define INT24_MIN (-INT24_MAX - 1)
// 决定字符串类型的宏
#define ZIP_IS_STR(enc) (((enc) & ZIP_STR_MASK) < ZIP_STR_MASK)
/* 工具宏 */
// 获取ziplist占用的总字节数,ziplist在zip header的第0~3个字节保存了ZIP_BYTES
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
// 获取ziplist的尾节点偏移量,ziplist在zip header的第4~7个字节保存了ZIP_TAIL
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
// 获取ziplist的节点数量,ziplist在zip header的第8~9个字节保存了ZIP_LENGTH
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
// 获取ziplist的header大小,zip header中保存了ZIP_BYTES(uint32_t)、ZIP_TAIL(uint32_t)和ZIP_LENGTH(uint16_t),一共10字节
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// 获取ziplist的ZIP_END大小,是一个uint8_t类型,1字节
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
// 获取ziplist ZIP_ENTRY头节点地址,ZIP_ENTRY头指针 = ziplist首地址 + head大小
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
// 获取ziplist ZIP_ENTRY尾节点地址,ZIP_ENTRY尾指针 = ziplist首地址 + 尾节点偏移量
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
// 获取ziplist尾指针(ZIP_END),ziplist尾指针 = ziplist首地址 + ziplist占用的总字节数 - 1
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
/* ziplist节点数量的正增量只能是1(删除节点时,负增量有可能小于-1),因为每次只能添加一个元素到ziplist中。 */
#define ZIPLIST_INCR_LENGTH(zl,incr) { \
if (ZIPLIST_LENGTH(zl) < UINT16_MAX) \
ZIPLIST_LENGTH(zl) = intrev16ifbe(intrev16ifbe(ZIPLIST_LENGTH(zl))+incr); \
}
// 压缩链表节点结构
typedef struct zlentry {
// prevrawlensize: 上一个节点的长度所占的字节数
// prevrawlen: 上一个节点的长度
unsigned int prevrawlensize, prevrawlen;
// lensize: 编码当前节点长度len所需要的字节数
// len: 当前节点长度
unsigned int lensize, len;
// 当前节点的header大小,headersize = lensize + prevrawlensize
unsigned int headersize;
// 当前节点的编码格式
unsigned char encoding;
// 当前节点指针
unsigned char *p;
} zlentry;
// 重置压缩链表节点
#define ZIPLIST_ENTRY_ZERO(zle) { \
(zle)->prevrawlensize = (zle)->prevrawlen = 0; \
(zle)->lensize = (zle)->len = (zle)->headersize = 0; \
(zle)->encoding = 0; \
(zle)->p = NULL; \
}
/* 提取ptr指向的字节的编码并把其编码设置为encoding指定的值 */
#define ZIP_ENTRY_ENCODING(ptr, encoding) do { \
(encoding) = (ptr[0]); \
if ((encoding) < ZIP_STR_MASK) (encoding) &= ZIP_STR_MASK; \
} while(0)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
zipIntSize函数返回存储一个以 encoding 为编码的整型需要的字节数。
unsigned int zipIntSize(unsigned char encoding) {
switch(encoding) {
case ZIP_INT_8B: return 1;
case ZIP_INT_16B: return 2;
case ZIP_INT_24B: return 3;
case ZIP_INT_32B: return 4;
case ZIP_INT_64B: return 8;
default: return 0; /* 4 bit immediate */
}
assert(NULL); // 不应该到达这里
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
zipEncodeLength函数计算新节点的长度和编码所占用的字节数,并存储在'p'中。如果 p 为 NULL 就返回编码这样的长度所需要的字节数量。
unsigned int zipEncodeLength(unsigned char *p, unsigned char encoding, unsigned int rawlen) {
// len: 需要的字节数量
// buf: 字符串长度存储结构
unsigned char len = 1, buf[5];
if (ZIP_IS_STR(encoding)) {
/* 虽然给定了编码,但,所以我们这里使用原始长度来判断编码类型 */
if (rawlen <= 0x3f) { // 长度小于2^6,使用1个字节保存
if (!p) return len; // p为NULL则直接返回1(字节)
buf[0] = ZIP_STR_06B | rawlen;
} else if (rawlen <= 0x3fff) { // 长度小于2^14,使用2个字节保存
len += 1;
if (!p) return len;
buf[0] = ZIP_STR_14B | ((rawlen >> 8) & 0x3f);
buf[1] = rawlen & 0xff;
} else { // 其他情况,使用4个字节保存
len += 4;
if (!p) return len;
buf[0] = ZIP_STR_32B;
buf[1] = (rawlen >> 24) & 0xff;
buf[2] = (rawlen >> 16) & 0xff;
buf[3] = (rawlen >> 8) & 0xff;
buf[4] = rawlen & 0xff;
}
} else {
/* 整数编码,存储结构长度总是1 */
if (!p) return len;
buf[0] = encoding;
}
/* p存储字符串长度存储结构 */
memcpy(p,buf,len);
return len; // 返回存储数据的长度需要的字节数量
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
ZIP_DECODE_LENGTH宏解码 ptr 中被编码的长度。encoding 变量保存了节点的编码,lensize 变量保存了编码节点长度所需要的字节数,len 变量保存节点长度。
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do { \
ZIP_ENTRY_ENCODING((ptr), (encoding)); \
if ((encoding) < ZIP_STR_MASK) { \
if ((encoding) == ZIP_STR_06B) { \
(lensize) = 1; \
(len) = (ptr)[0] & 0x3f; \
} else if ((encoding) == ZIP_STR_14B) { \
(lensize) = 2; \
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1]; \
} else if (encoding == ZIP_STR_32B) { \
(lensize) = 5; \
(len) = ((ptr)[1] << 24) | \
((ptr)[2] << 16) | \
((ptr)[3] << 8) | \
((ptr)[4]); \
} else { \
assert(NULL); \
} \
} else { \
/* 整数编码,存储结构长度总是1 */ \
(lensize) = 1; \
(len) = zipIntSize(encoding); \
} \
} while(0);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
zipPrevEncodeLength函数将 p 指向的节点的 header 以 len 长度进行重新编码,更新 prevrawlensize 和 prevrawlen,len 为前一个节点的长度。如果 p 为 NULL 就返回存储 len 长度需要的字节数。
unsigned int zipPrevEncodeLength(unsigned char *p, unsigned int len) {
if (p == NULL) {
return (len < ZIP_BIGLEN) ? 1 : sizeof(len)+1;
} else {
if (len < ZIP_BIGLEN) {
p[0] = len;
return 1;
} else {
p[0] = ZIP_BIGLEN;
memcpy(p+1,&len,sizeof(len));
memrev32ifbe(p+1);
return 1+sizeof(len);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
zipPrevEncodeLengthForceLarge函数如果 p 非空,记录编码前一个节点的长度需要的字节数到 p 中。这个函数只在比较大的 encoding 时使用(__ziplistCascadeUpdate 函数中用到了该函数)。
void zipPrevEncodeLengthForceLarge(unsigned char *p, unsigned int len) {
if (p == NULL) return;
p[0] = ZIP_BIGLEN;
memcpy(p+1,&len,sizeof(len));
memrev32ifbe(p+1);
}
2
3
4
5
6
ZIP_DECODE_PREVLENSIZE宏计算 ptr 指向的节点中存储的上一个节点长度需要的字节数,设置在 prevlensize 中。
#define ZIP_DECODE_PREVLENSIZE(ptr, prevlensize) do { \
if ((ptr)[0] < ZIP_BIGLEN) { \
(prevlensize) = 1; \
} else { \
(prevlensize) = 5; \
} \
} while(0);
2
3
4
5
6
7
ZIP_DECODE_PREVLEN宏计算 ptr 指向的节点的上一个节点的长度(存储在 prevlen 中)和存储的上一个节点长度需要的字节数(存储在 prevlensize 中)。
#define ZIP_DECODE_PREVLEN(ptr, prevlensize, prevlen) do { \
ZIP_DECODE_PREVLENSIZE(ptr, prevlensize); \
if ((prevlensize) == 1) { \
(prevlen) = (ptr)[0]; \
} else if ((prevlensize) == 5) { \
assert(sizeof((prevlensize)) == 4); \
memcpy(&(prevlen), ((char*)(ptr)) + 1, 4); \
memrev32ifbe(&prevlen); \
} \
} while(0);
2
3
4
5
6
7
8
9
10
zipPrevLenByteDiff函数返回存储长度为 len 所需的字节数和存储 p 指向的节点的上一个节点的长度所需的字节数之差(字节)。
int zipPrevLenByteDiff(unsigned char *p, unsigned int len) {
unsigned int prevlensize;
ZIP_DECODE_PREVLENSIZE(p, prevlensize); // 计算保存p指向节点的上一个节点的长度所需的字节数
return zipPrevEncodeLength(NULL, len) - prevlensize;
}
2
3
4
5
zipRawEntryLength函数返回 p 指向的节点所占用的字节数。
unsigned int zipRawEntryLength(unsigned char *p) {
//
unsigned int prevlensize, encoding, lensize, len;
ZIP_DECODE_PREVLENSIZE(p, prevlensize);
ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len);
return prevlensize + lensize + len;
}
2
3
4
5
6
7
zipTryEncoding函数检查 entry 指向的字符串能否被编码成一个整型,能返回 1,不能返回 0。并保存这个整数在 v 中,保存这个整数的编码在 encoding 中。
int zipTryEncoding(unsigned char *entry, unsigned int entrylen, long long *v, unsigned char *encoding) {
long long value;
if (entrylen >= 32 || entrylen == 0) return 0; // entry长度大于32位或者为0都不能被编码为一个整型
if (string2ll((char*)entry,entrylen,&value)) {
/* 这个字符串可以被编码。判断能够编码它的最小编码类型。 */
if (value >= 0 && value <= 12) {
*encoding = ZIP_INT_IMM_MIN+value;
} else if (value >= INT8_MIN && value <= INT8_MAX) {
*encoding = ZIP_INT_8B;
} else if (value >= INT16_MIN && value <= INT16_MAX) {
*encoding = ZIP_INT_16B;
} else if (value >= INT24_MIN && value <= INT24_MAX) {
*encoding = ZIP_INT_24B;
} else if (value >= INT32_MIN && value <= INT32_MAX) {
*encoding = ZIP_INT_32B;
} else {
*encoding = ZIP_INT_64B;
}
*v = value;
return 1;
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
zipSaveInteger函数把 value 的值保存在 p 指向的节点中,其中编码类型为 encoding。
void zipSaveInteger(unsigned char *p, int64_t value, unsigned char encoding) {
int16_t i16;
int32_t i32;
int64_t i64;
if (encoding == ZIP_INT_8B) {
((int8_t*)p)[0] = (int8_t)value;
} else if (encoding == ZIP_INT_16B) {
i16 = value;
memcpy(p,&i16,sizeof(i16));
memrev16ifbe(p);
} else if (encoding == ZIP_INT_24B) {
i32 = value<<8;
memrev32ifbe(&i32);
memcpy(p,((uint8_t*)&i32)+1,sizeof(i32)-sizeof(uint8_t));
} else if (encoding == ZIP_INT_32B) {
i32 = value;
memcpy(p,&i32,sizeof(i32));
memrev32ifbe(p);
} else if (encoding == ZIP_INT_64B) {
i64 = value;
memcpy(p,&i64,sizeof(i64));
memrev64ifbe(p);
} else if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX) {
/* 值直接保存在编码本身中,什么也不做。 */
} else {
assert(NULL);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
zipLoadInteger函数返回 p 指向的节点中以 encoding 为编码的整型数。
int64_t zipLoadInteger(unsigned char *p, unsigned char encoding) {
int16_t i16;
int32_t i32;
int64_t i64, ret = 0;
if (encoding == ZIP_INT_8B) {
ret = ((int8_t*)p)[0];
} else if (encoding == ZIP_INT_16B) {
memcpy(&i16,p,sizeof(i16));
memrev16ifbe(&i16);
ret = i16;
} else if (encoding == ZIP_INT_32B) {
memcpy(&i32,p,sizeof(i32));
memrev32ifbe(&i32);
ret = i32;
} else if (encoding == ZIP_INT_24B) {
i32 = 0;
memcpy(((uint8_t*)&i32)+1,p,sizeof(i32)-sizeof(uint8_t));
memrev32ifbe(&i32);
ret = i32>>8;
} else if (encoding == ZIP_INT_64B) {
memcpy(&i64,p,sizeof(i64));
memrev64ifbe(&i64);
ret = i64;
} else if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX) {
ret = (encoding & ZIP_INT_IMM_MASK)-1;
} else {
assert(NULL);
}
return ret;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
zipEntry函数将 p 指向的节点的所有信息存储在压缩链表节点 e 中。
void zipEntry(unsigned char *p, zlentry *e) {
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen);
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len);
e->headersize = e->prevrawlensize + e->lensize;
e->p = p;
}
2
3
4
5
6
7
ziplistNew函数创建一个空的压缩链表。
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+1; // 空压缩链表占用的总字节数 = 压缩链表头部大小 + ZIP_END大小(等于1)
unsigned char *zl = zmalloc(bytes); // 为压缩链表分配空间
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); // 填充压缩链表占用的总字节数数据域
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE); // // 填充压缩链表最后一个节点的偏移量数据域
ZIPLIST_LENGTH(zl) = 0; // 填充压缩链表节点数量数据域
zl[bytes-1] = ZIP_END; // 填充压缩链表ZIP_END数据域(ZIP_END在压缩链表的最后一个字节)
return zl;
}
2
3
4
5
6
7
8
9
ziplistResize函数调整指定的压缩链表大小。
unsigned char *ziplistResize(unsigned char *zl, unsigned int len) {
zl = zrealloc(zl,len); // realloc空间
ZIPLIST_BYTES(zl) = intrev32ifbe(len); // 填充压缩链表占用的总字节数数据域
zl[len-1] = ZIP_END; // 填充压缩链表ZIP_END数据域(ZIP_END在压缩链表的最后一个字节)
return zl;
}
2
3
4
5
6
__ziplistCascadeUpdate函数执行压缩链表级联更新。
unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) {
// curlen: 当前压缩链表占用的字节数,rawlen: 节点长度,rawlensize: 保存节点长度需要的字节数
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize;
size_t offset, noffset, extra;
unsigned char *np;
zlentry cur, next;
while (p[0] != ZIP_END) { // p指向当前节点的首地址
zipEntry(p, &cur); // 将p指向的节点信息初始化到cur指向的zipEntry中
rawlen = cur.headersize + cur.len; // 节点总长度 = 节点头长度 + 当前节点长度
rawlensize = zipPrevEncodeLength(NULL,rawlen); // 计算存储当前节点的长度需要的字节数
/* 如果是最后一个节点,则跳出while循环。 */
if (p[rawlen] == ZIP_END) break;
zipEntry(p+rawlen, &next); // p+rawlen为下一个节点的首地址,初始化next为下一个节点
/* 对next节点来说,如果上一个节点(就是cur)的长度没有改变,就不做任何操作。 */
if (next.prevrawlen == rawlen) break;
if (next.prevrawlensize < rawlensize) {
/* next节点的上一个节点的长度所占的字节数next.prevrawlensize
* 小于存储当前节点的长度需要的字节数时,需要扩容 */
offset = p-zl; // 当前节点相对于压缩链表首地址的偏移量
extra = rawlensize-next.prevrawlensize; // 额外需要的字节数 = 存储当前节点的长度需要的字节数(刚计算得出)- next中存储上一个节点的长度所占的字节数
zl = ziplistResize(zl,curlen+extra); // 调整压缩链表长度
p = zl+offset; // 当前节点指针
np = p+rawlen; // next节点新地址
noffset = np-zl; // next节点的偏移量
/* 更新ziplist最后一个节点偏移量,如果next节点是尾部节点就不做更新。 */
if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra);
}
/* 移动next节点到新地址,为当前节点cur空出空间。
* */
memmove(np+rawlensize,
np+next.prevrawlensize,
curlen-noffset-next.prevrawlensize-1);
// 将next节点的header以rawlen长度进行重新编码,更新prevrawlensize和prevrawlen
zipPrevEncodeLength(np,rawlen);
/* 更新当前节点指针 */
p += rawlen; // 指向下一个节点
curlen += extra; // 更新压缩链表占用的总字节数
} else {
if (next.prevrawlensize > rawlensize) {
/* next节点的上一个节点的长度所占的字节数next.prevrawlensize,
* 小于存储当前节点的长度需要的字节数时,这意味着next节点编码前置节点的
* header空间有5字节,而编码rawlen只需要1字节,需要缩容。但应该尽量避免这么做。
* 所以我们用5字节的空间将1字节的编码重新编码 */
zipPrevEncodeLengthForceLarge(p+rawlen,rawlen);
} else {
// 说明next.prevrawlensize = rawlensize,只需要更新next节点的header
zipPrevEncodeLength(p+rawlen,rawlen);
}
/* Stop here, as the raw length of "next" has not changed. */
break;
}
}
return zl;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
__ziplistDelete函数从 p 指向的节点开始,删除 num 个节点。返回 ziplist 的指针。
unsigned char *__ziplistDelete(unsigned char *zl, unsigned char *p, unsigned int num) {
unsigned int i, totlen, deleted = 0;
size_t offset;
int nextdiff = 0;
zlentry first, tail;
zipEntry(p, &first); // p指向第一个要删除的节点
for (i = 0; p[0] != ZIP_END && i < num; i++) { // 从p开始遍历num个节点(如果有这么多),统计要删除的节点数量
p += zipRawEntryLength(p); // zipRawEntryLength(p)返回p指向的节点所占用的字节数
deleted++;
}
totlen = p-first.p; // 总的删除长度
if (totlen > 0) {
if (p[0] != ZIP_END) {
/* 如果被删除的最后一个节点不是压缩链表的最后一个节点,说明它后面还有节点A。
* A节点的header部分的大小可能无法容纳新的前置节点B(被删除的第一个节点的前置节点)
* 所以这里需要计算这里面的差值。 */
// first.prevrawlen为被删除的第一个节点的前置节点的长度
// p指向被删除的最后一个节点的后置节点
nextdiff = zipPrevLenByteDiff(p,first.prevrawlen); // 差值
p -= nextdiff; // 更新p的指针
zipPrevEncodeLength(p,first.prevrawlen); // 更新被删除的最后一个节点的后置节点的prevrawlensize和prevrawlen
/* 更新表尾偏移量,新的表尾偏移量 = 当前表尾偏移量 - 删除的长度 */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))-totlen);
zipEntry(p, &tail); // tail为最后一个删除节点的后置节点
// 当被删除的最后一个节点后面有多于一个的节点,需要更新ziplist表尾偏移量,加上修正值
if (p[tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
/* 把tail节点之后的数据移动到被删除的第一个节点的位置 */
memmove(first.p,p,
intrev32ifbe(ZIPLIST_BYTES(zl))-(p-zl)-1);
} else {
/* 把p指向的节点和其后面的所有节点都删除了,无须移动数据,只需要更新ziplist表尾偏移量 */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe((first.p-zl)-first.prevrawlen);
}
offset = first.p-zl; // 节点结合处偏移量
zl = ziplistResize(zl, intrev32ifbe(ZIPLIST_BYTES(zl))-totlen+nextdiff); // 调整ziplist大小
ZIPLIST_INCR_LENGTH(zl,-deleted); // 调整ziplist节点数量
p = zl+offset; // 节点结合处指针
/* 当nextdiff != 0时,结合处的节点将发生变化(前置节点长度prevrawlen会改变),
* 这里我们需要级联更新ziplist。 */
if (nextdiff != 0)
zl = __ziplistCascadeUpdate(zl,p);
}
return zl;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
__ziplistInsert函数在 p 指向的地方插入元素,元素值为 s,值长度为 slen。
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
// curlen: 压缩链表占用的字节长度
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
// prevlensize: 保存插入位置处节点的前置节点len所需的字节数,prevlen: 插入位置处节点的前置节点长度
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
/* 找出插入位置的前置节点的长度 */
if (p[0] != ZIP_END) {
// 获取插入位置处节点的前置节点长度len所需的字节数和前置节点的长度
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
// 插入位置为链表尾
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl); // ptail为尾节点指针
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLength(ptail); // 计算尾节点的前置节点的长度
}
}
/* 检查节点是否可以被编码,并判断编码类型 */
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* zipIntSize(encoding)返回编码指定类型整数需要的空间大小 */
reqlen = zipIntSize(encoding);
} else {
/* 无法用一个整数编码,使用字符串编码,编码长度为入参slen。 */
reqlen = slen;
}
/* 计算保存前置节点长度需要的空间和保存值需要的空间大小。 */
reqlen += zipPrevEncodeLength(NULL,prevlen);
reqlen += zipEncodeLength(NULL,encoding,slen);
/* 当不是在链表尾插入时,我们需要保证插入位置的后置节点的空间能够保存这个
* 被插入节点的长度。 */
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0; // 计算空间差值
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
/* 保存插入位置的偏移量,因为realloc调用有可能会改变ziplist的地址。 */
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff); // ziplist调整大小
p = zl+offset; // 更新插入位置指针
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END) { // 不是在链表尾插入
/* 新节点长度为reqlen,将新节点后面的节点都移动到新的位置。 */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* 在新节点的后置节点中更新前置节点的信息。 */
if (forcelarge)
zipPrevEncodeLengthForceLarge(p+reqlen,reqlen);
else
zipPrevEncodeLength(p+reqlen,reqlen);
/* 更新尾节点偏移量,直接在原来的基础加上新节点长度即可 */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
zipEntry(p+reqlen, &tail); // tail为新节点的后置节点
// 当新节点的后面有多于一个的节点,需要更新ziplist表尾偏移量,加上修正值
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
// 在链表尾插入,新节点成为新的尾节点,更新尾节点偏移量。
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* 当nextdiff != 0时,结合处的节点将发生变化(前置节点长度prevrawlen会改变),
* 这里我们需要级联更新ziplist。 */
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* 真正插入节点 */
p += zipPrevEncodeLength(p,prevlen); // 新节点存储前置节点长度需要的字节数
p += zipEncodeLength(p,encoding,slen); // 新节点编码长度为slen的数据所需要的字节数量
if (ZIP_IS_STR(encoding)) { // 字符串型数据
memcpy(p,s,slen); // 拷贝数据s到指定位置
} else {
zipSaveInteger(p,value,encoding); // 保存整数
}
ZIPLIST_INCR_LENGTH(zl,1); // 更新链表节点数量
return zl;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
ziplistMerge函数合并两个 ziplist,把第一个 ziplist 和第二个 ziplist 首尾相连。
unsigned char *ziplistMerge(unsigned char **first, unsigned char **second) {
/* 如果所有参数都是NULL,无须合并,直接返回NULL。 */
if (first == NULL || *first == NULL || second == NULL || *second == NULL)
return NULL;
/* 如果两个ziplist是同一个,也无法合并。 */
if (*first == *second)
return NULL;
// 第1个ziplist占用的空间大小和节点数量
size_t first_bytes = intrev32ifbe(ZIPLIST_BYTES(*first));
size_t first_len = intrev16ifbe(ZIPLIST_LENGTH(*first));
// 第2个ziplist占用的空间大小和节点数量
size_t second_bytes = intrev32ifbe(ZIPLIST_BYTES(*second));
size_t second_len = intrev16ifbe(ZIPLIST_LENGTH(*second));
int append;
unsigned char *source, *target;
size_t target_bytes, source_bytes;
/* 选择比较大的那个ziplist,这样直接就地扩容比较容易。
* */
if (first_len >= second_len) {
/* 以第一个ziplist为target,把第二个ziplist追加到它后面。 */
target = *first;
target_bytes = first_bytes;
source = *second;
source_bytes = second_bytes;
append = 1; // 后向追加
} else {
/* 以第二个ziplist为target,把第一个ziplist前向追加到它上面。 */
target = *second;
target_bytes = second_bytes;
source = *first;
source_bytes = first_bytes;
append = 0; // 前向追加
}
/* 计算合并后的ziplist占用的空间大小,需要扣除其中一个ziplist的元数据(zip_header和zip_end)的大小 */
size_t zlbytes = first_bytes + second_bytes -
ZIPLIST_HEADER_SIZE - ZIPLIST_END_SIZE;
size_t zllength = first_len + second_len; // 合并后的ziplist节点数量
/* 合并后的ziplist节点数量必须限制在UINT16_MAX之内 */
zllength = zllength < UINT16_MAX ? zllength : UINT16_MAX;
/* 在操作内存之前先保存两个ziplist的尾节点偏移量。 */
size_t first_offset = intrev32ifbe(ZIPLIST_TAIL_OFFSET(*first));
size_t second_offset = intrev32ifbe(ZIPLIST_TAIL_OFFSET(*second));
/* realloc目标ziplist的空间。 */
target = zrealloc(target, zlbytes);
if (append) {
/* append == appending to target */
/* Copy source after target (copying over original [END]):
* [TARGET - END, SOURCE - HEADER] */
/* target = ziplist_1 <- ziplist_2 */
memcpy(target + target_bytes - ZIPLIST_END_SIZE,
source + ZIPLIST_HEADER_SIZE,
source_bytes - ZIPLIST_HEADER_SIZE);
} else {
/* !append == prepending to target */
/* Move target *contents* exactly size of (source - [END]),
* then copy source into vacataed space (source - [END]):
* [SOURCE - END, TARGET - HEADER] */
/* target = ziplist_1 -> ziplist_2 */
memmove(target + source_bytes - ZIPLIST_END_SIZE,
target + ZIPLIST_HEADER_SIZE,
target_bytes - ZIPLIST_HEADER_SIZE);
memcpy(target, source, source_bytes - ZIPLIST_END_SIZE);
}
/* 更新目标ziplist header元数据 */
ZIPLIST_BYTES(target) = intrev32ifbe(zlbytes); // 更新目标ziplist占用的字节数
ZIPLIST_LENGTH(target) = intrev16ifbe(zllength); // 更新目标ziplist节点数量
/* 新的尾节点偏移量计算方式:
* + N 字节:第一个ziplist的总字节数
* - 1 字节:第一个ziplist的ZIP_END
* + M 字节:第二个ziplist原来的尾节点偏移量
* - J 字节:第二个ziplist的header的字节数 */
ZIPLIST_TAIL_OFFSET(target) = intrev32ifbe(
(first_bytes - ZIPLIST_END_SIZE) +
(second_offset - ZIPLIST_HEADER_SIZE));
/* 在接合处级联更新目标ziplist */
target = __ziplistCascadeUpdate(target, target+first_offset);
/* Now free and NULL out what we didn't realloc */
if (append) {
// target = ziplist_1 <- ziplist_2,释放第二个ziplist的空间,并更新ziplist指针
zfree(*second);
*second = NULL;
*first = target;
} else {
// target = ziplist_1 -> ziplist_2,释放第一个ziplist的空间,并更新ziplist指针
zfree(*first);
*first = NULL;
*second = target;
}
return target;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
ziplistPush函数向 ziplist 中插入元素,只能在首尾添加。
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) {
unsigned char *p;
p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl); // 获取插入位置指针
return __ziplistInsert(zl,p,s,slen);
}
2
3
4
5
ziplistIndex函数根据给定的索引值返回一个节点的指针。当给定的索引值为负时,从后向前遍历。当链表在给定的索引值上没有节点时返回 NULL。
unsigned char *ziplistIndex(unsigned char *zl, int index) {
unsigned char *p;
unsigned int prevlensize, prevlen = 0;
if (index < 0) {
// 从后向前遍历链表
index = (-index)-1;
p = ZIPLIST_ENTRY_TAIL(zl); // 尾节点指针
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
while (prevlen > 0 && index--) {
p -= prevlen;
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
}
}
} else {
// 从前向后遍历链表
p = ZIPLIST_ENTRY_HEAD(zl); // 头节点指针
while (p[0] != ZIP_END && index--) {
p += zipRawEntryLength(p);
}
}
return (p[0] == ZIP_END || index > 0) ? NULL : p; // 没有找到相应的节点,返回NULL,否则返回这个节点的指针
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
ziplistNext函数返回 ziplist 中当前节点的后置节点指针,如果当前节点是尾节点则返回 NULL。
/* 返回ziplist中当前节点的后置节点指针,如果当前节点是尾节点则返回NULL。 */
unsigned char *ziplistNext(unsigned char *zl, unsigned char *p) {
((void) zl);
/* 由于调用ziplistDelete函数,p有可能等于ZIP_END,
* 这时应该返回NULL。否则,当后置节点为ZIP_END时返回NULL。 */
if (p[0] == ZIP_END) {
return NULL;
}
p += zipRawEntryLength(p); // p加上当前节点长度为它的后置节点的地址
if (p[0] == ZIP_END) {
return NULL;
}
return p;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
ziplistPrev函数返回 ziplist 当前节点的前置节点指针。
unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p) {
unsigned int prevlensize, prevlen = 0;
/* 从ZIP_END开始向前迭代会返回尾节点。当p指向链表头节点时,返回NULL。 */
if (p[0] == ZIP_END) {
// p指向ZIP_END时,返回链表尾节点
p = ZIPLIST_ENTRY_TAIL(zl);
return (p[0] == ZIP_END) ? NULL : p;
} else if (p == ZIPLIST_ENTRY_HEAD(zl)) {
// p指向链表头节点时,返回NULL
return NULL;
} else {
// 获得p指向节点的前置节点长度,p减该长度即为当前节点前置节点
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
assert(prevlen > 0);
return p-prevlen;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
ziplistGet函数获取 p 指向的节点的数据,根据其编码决定数据保存在*sstr(字符串)还是 sval(整数)中。*sstr 刚开始总是被设置为 NULL。当 p 指向 ziplist 的尾部(ZIP_END)时返回 0,否则返回 1。
unsigned int ziplistGet(unsigned char *p, unsigned char **sstr, unsigned int *slen, long long *sval) {
zlentry entry;
if (p == NULL || p[0] == ZIP_END) return 0;
if (sstr) *sstr = NULL;
zipEntry(p, &entry); // 初始化entry为当前节点
if (ZIP_IS_STR(entry.encoding)) { // 当前节点为字符串,数据保存在*sstr
if (sstr) {
*slen = entry.len;
*sstr = p+entry.headersize;
}
} else { // 当前节点为整数,数据保存在*sval
if (sval) {
*sval = zipLoadInteger(p+entry.headersize,entry.encoding);
}
}
return 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
ziplistInsert函数向 ziplist 中 p 指向的节点处插入一个节点。
unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
return __ziplistInsert(zl,p,s,slen);
}
2
3
ziplistDelete函数从 ziplist 中删除 p 指向的节点。还就地更新了*p,以使得在删除节点的时候还能迭代 ziplist。
unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p) {
size_t offset = *p-zl; // 当前节点的偏移量
zl = __ziplistDelete(zl,*p,1); // 从ziplist中删除当前节点,由于ziplistDelete会调用realloc,zl有可能会发生变化
/* 事先在p中保存当前元素的指针,因为ziplistDelete会调用realloc,有可能会导致zl指针发生变化。 */
*p = zl+offset; // 更新了*p,此时*p指向的是被删除节点的后置节点,可以继续使用这个指针进行迭代。
return zl;
}
2
3
4
5
6
7
8
ziplistDeleteRange函数删除 ziplist 中一个范围内的节点。
unsigned char *ziplistDeleteRange(unsigned char *zl, int index, unsigned int num) {
unsigned char *p = ziplistIndex(zl,index);
return (p == NULL) ? zl : __ziplistDelete(zl,p,num);
}
2
3
4
ziplistCompare函数比较 p 指向节点的值和 sstr 指向的长度为 slen 的数据,当相等时返回 1,否则返回 0。
unsigned int ziplistCompare(unsigned char *p, unsigned char *sstr, unsigned int slen) {
zlentry entry;
unsigned char sencoding;
long long zval, sval;
if (p[0] == ZIP_END) return 0;
zipEntry(p, &entry); // entry为p指向的节点
if (ZIP_IS_STR(entry.encoding)) {
/* entry的值是字符串 */
if (entry.len == slen) {
return memcmp(p+entry.headersize,sstr,slen) == 0;
} else {
return 0;
}
} else {
/* entry的值是整数,此时不比较编码类型,因为不同编码类型的位数不同,只比较值是否相等。 */
if (zipTryEncoding(sstr,slen,&sval,&sencoding)) {
zval = zipLoadInteger(p+entry.headersize,entry.encoding);
return zval == sval;
}
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
ziplistFind函数在 ziplist 中查找与指定节点相等的节点。每次比较后跳过 skip 个节点。没有找到相应节点时返回 NULL。
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip) {
int skipcnt = 0; // 已经跳过的节点数
unsigned char vencoding = 0;
long long vll = 0;
while (p[0] != ZIP_END) {
unsigned int prevlensize, encoding, lensize, len;
unsigned char *q;
ZIP_DECODE_PREVLENSIZE(p, prevlensize); // 保存当前节点的前置节点长度所需的字节数
ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len); // 获取当前节点的encoding、lensize和len
q = p + prevlensize + lensize; // 当前节点value域指针
if (skipcnt == 0) {
/* 比较当前节点和给定节点的值 */
if (ZIP_IS_STR(encoding)) {
// 当前节点的值为字符串
if (len == vlen && memcmp(q, vstr, vlen) == 0) {
return p;
}
} else {
/* 判断vstr指向的数据能否被编码成整数,这个操作只做一次,
* 一旦判定为可以被编码成整数,vencoding被设置为非0值且vll被设置成一对应的整数。
* 如果不能,vencoding被设置为UCHAR_MAX。 */
if (vencoding == 0) {
if (!zipTryEncoding(vstr, vlen, &vll, &vencoding)) {
/* If the entry can't be encoded we set it to
* UCHAR_MAX so that we don't retry again the next
* time. */
vencoding = UCHAR_MAX;
}
/* Must be non-zero by now */
assert(vencoding);
}
/* 只有当vencoding != UCHAR_MAX时才能以整数比较当前节点和给定节点的值。 */
if (vencoding != UCHAR_MAX) { // vstr指向的值可以被以整数编码
long long ll = zipLoadInteger(q, encoding);
if (ll == vll) {
return p;
}
}
}
/* Reset skip count */
skipcnt = skip;
} else {
/* Skip entry */
skipcnt--;
}
/* 移动到下个节点 */
p = q + len;
}
return NULL;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
ziplistLen函数返回 ziplist 的节点数量。
unsigned int ziplistLen(unsigned char *zl) {
unsigned int len = 0;
if (intrev16ifbe(ZIPLIST_LENGTH(zl)) < UINT16_MAX) {
// 如果ziplist的节点数量小于UINT16_MAX,直接取ziplist header中存放的节点数量
len = intrev16ifbe(ZIPLIST_LENGTH(zl));
} else {
unsigned char *p = zl+ZIPLIST_HEADER_SIZE; // ziplist头节点指针
while (*p != ZIP_END) { // 遍历ziplist计算节点数量
p += zipRawEntryLength(p);
len++;
}
/* 如果实际计算出来的长度小于UINT16_MAX,更新ziplist header中的节点数量 */
if (len < UINT16_MAX) ZIPLIST_LENGTH(zl) = intrev16ifbe(len);
}
return len;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
ziplistBlobLen函数获取链表占用的总字节数。
size_t ziplistBlobLen(unsigned char *zl) {
return intrev32ifbe(ZIPLIST_BYTES(zl));
}
2
3