 Redis 知识总结
Redis 知识总结
# 概述
Redis 是速度非常快的非关系型(NoSQL)内存键值数据库,可以存储键和五种不同类型的值之间的映射。
键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表(hash)、有序集合。
Redis 支持很多特性,例如将内存中的数据持久化到硬盘中,使用复制来扩展读性能,使用分片来扩展写性能。
# 特点
速度快,因为数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是 O(1)
支持丰富数据类型,支持 string,list,set,sorted set,hash
支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
丰富的特性:可用于缓存,消息,按 key 设置过期时间,过期后将会自动删除
# 数据类型
| 数据类型 | 可以存储的值 | 操作 |
|---|---|---|
| STRING | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作 对整数和浮点数执行自增或者自减操作 |
| LIST | 列表 | 从两端压入或者弹出元素 对单个或者多个元素进行修剪, 只保留一个范围内的元素 |
| SET | 无序集合 | 添加、获取、移除单个元素 检查一个元素是否存在于集合中 计算交集、并集、差集 从集合里面随机获取元素 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对 获取所有键值对 检查某个键是否存在 |
| ZSET | 有序集合 | 添加、获取、删除元素 根据分值范围或者成员来获取元素 计算一个键的排名 |
如果你是 Redis 中高级用户,还需要加上下面几种数据结构 HyperLogLog、Geo、Pub/Sub。
如果你说还玩过 Redis Module,像 BloomFilter,RedisSearch,Redis-ML,面试官得眼睛就开始发亮了。
# STRING
SET、GET、INCR、DECR、APPEND 
> set hello world
OK
> get hello
"world"
> del hello
(integer) 1
> get hello
(nil)
2
3
4
5
6
7
8
# LIST
LPUSH、RPUSH、LPOP、RPOP、LRANGE 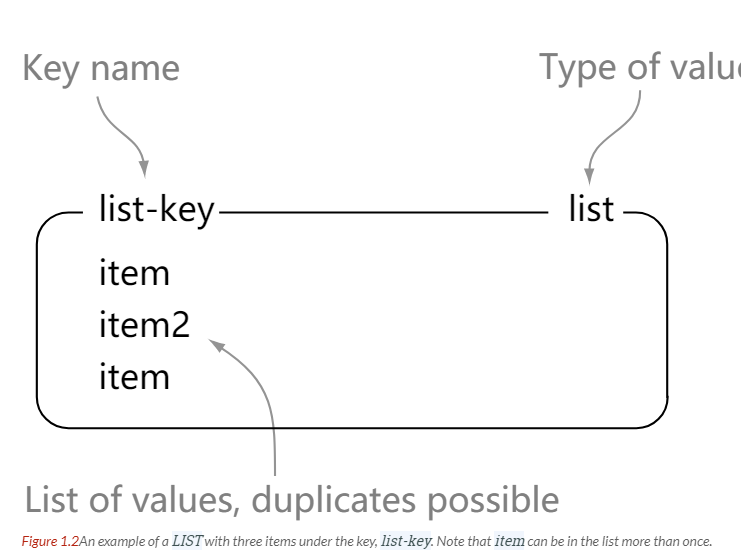
> rpush list-key item
(integer) 1
> rpush list-key item2
(integer) 2
> rpush list-key item
(integer) 3
> lrange list-key 0 -1
1) "item"
2) "item2"
3) "item"
> lindex list-key 1
"item2"
> lpop list-key
"item"
> lrange list-key 0 -1
1) "item2"
2) "item"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# SET
SADD、SMEMBERS、SREM、SINTER(交集)、SUNION(并集) 
> sadd set-key item
(integer) 1
> sadd set-key item2
(integer) 1
> sadd set-key item3
(integer) 1
> sadd set-key item
(integer) 0
> smembers set-key
1) "item"
2) "item2"
3) "item3"
> sismember set-key item4
(integer) 0
> sismember set-key item
(integer) 1
> srem set-key item2
(integer) 1
> srem set-key item2
(integer) 0
> smembers set-key
1) "item"
2) "item3"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# HASH
HSET、HGET、HMSET、HMGET、HDEL
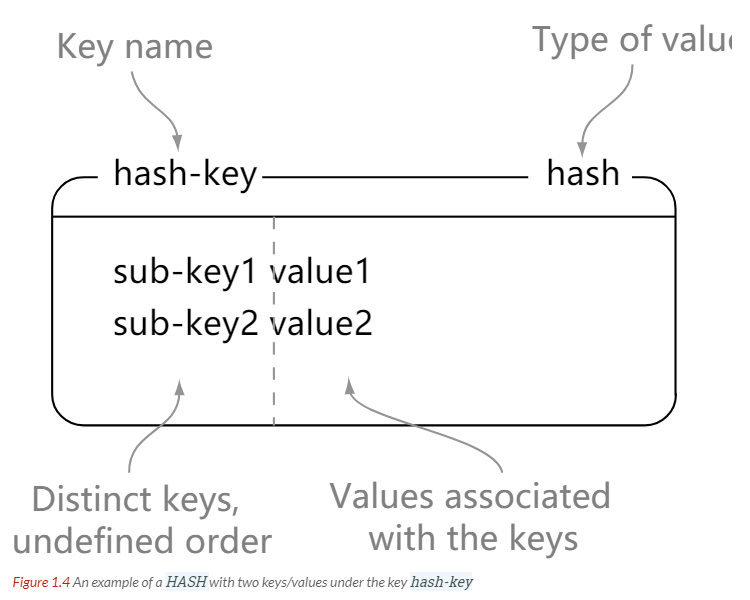
> hset hash-key sub-key1 value1
(integer) 1
> hset hash-key sub-key2 value2
(integer) 1
> hset hash-key sub-key1 value1
(integer) 0
> hgetall hash-key
1) "sub-key1"
2) "value1"
3) "sub-key2"
4) "value2"
> hdel hash-key sub-key2
(integer) 1
> hdel hash-key sub-key2
(integer) 0
> hget hash-key sub-key1
"value1"
> hgetall hash-key
1) "sub-key1"
2) "value1"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# ZSET
ZADD、ZRANGE、ZREM、ZINCRBY、ZINTERSTORE(交集) 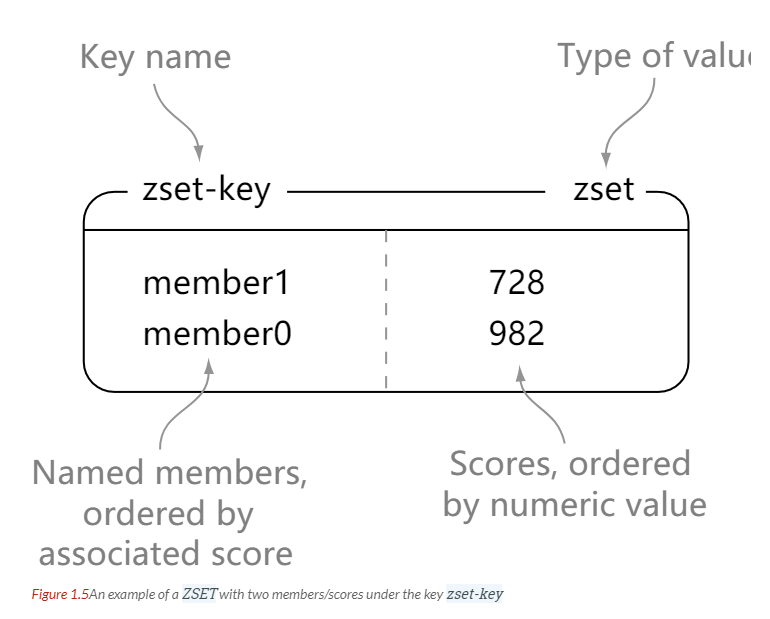
> zadd zset-key 728 member1
(integer) 1
> zadd zset-key 982 member0
(integer) 1
> zadd zset-key 982 member0
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member1"
2) "728"
3) "member0"
4) "982"
> zrangebyscore zset-key 0 800 withscores
1) "member1"
2) "728"
> zrem zset-key member1
(integer) 1
> zrem zset-key member1
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member0"
2) "982"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
通用:DEL、EXPIRE、TTL、KEYS(谨慎使用,生产环境可能阻塞)、SCAN(迭代键)等
# 数据结构
# 字典
dictht 是一个散列表结构,使用拉链法解决哈希冲突。
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
2
3
4
5
6
7
8
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
2
3
4
5
6
7
8
9
10
Redis 的字典 dict 中包含两个哈希表 dictht,这是为了方便进行 rehash 操作。在扩容时,将其中一个 dictht 上的键值对 rehash 到另一个 dictht 上面,完成之后释放空间并交换两个 dictht 的角色。
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
2
3
4
5
6
7
rehash 操作不是一次性完成,而是采用渐进方式,这是为了避免一次性执行过多的 rehash 操作给服务器带来过大的负担。
渐进式 rehash 通过记录 dict 的 rehashidx 完成,它从 0 开始,然后每执行一次 rehash 都会递增。例如在一次 rehash 中,要把 dict[0] rehash 到 dict[1],这一次会把 dict[0] 上 table[rehashidx] 的键值对 rehash 到 dict[1] 上,dict[0] 的 table[rehashidx] 指向 null,并令 rehashidx++。
在 rehash 期间,每次对字典执行添加、删除、查找或者更新操作时,都会执行一次渐进式 rehash。
采用渐进式 rehash 会导致字典中的数据分散在两个 dictht 上,因此对字典的查找操作也需要到对应的 dictht 去执行。
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n * 10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while (n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long) d->rehashidx);
while (d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while (de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 跳跃表
是有序集合的底层实现之一。
跳跃表是基于多指针有序链表实现的,可以看成多个有序链表。

在查找时,从上层指针开始查找,找到对应的区间之后再到下一层去查找。下图演示了查找 22 的过程。
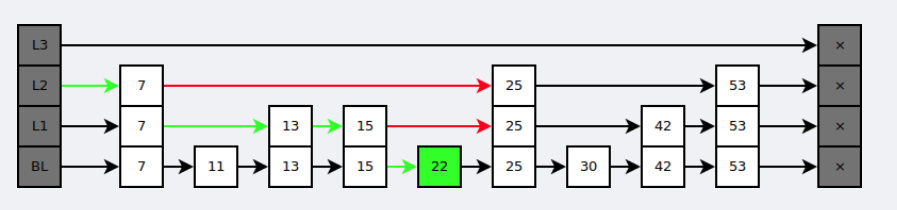
与红黑树等平衡树相比,跳跃表具有以下优点:
- 插入速度非常快速,因为不需要进行旋转等操作来维护平衡性;
- 更容易实现;
- 支持无锁操作。
# 使用场景
Redis 最适合所有数据 in-momory 的场景,虽然 Redis 也提供持久化功能,但实际更多的是一个 disk-backed 的功能,跟传统意义上的持久化有比较大的差别。
(1)会话缓存(Session Cache) 最常用的一种使用 Redis 的情景是会话缓存(session cache)。用 Redis 缓存会话比其他存储(如 Memcached)的优势在于:Redis 提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗? 幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用 Redis 来缓存会话的文档。甚至广为人知的商业平台 Magento 也提供 Redis 的插件。
(2)全页缓存(FPC) 除基本的会话 token 之外,Redis 还提供很简便的 FPC 平台。回到一致性问题,即使重启了 Redis 实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似 PHP 本地 FPC。 再次以 Magento 为例,Magento 提供一个插件来使用 Redis 作为全页缓存后端。 此外,对 WordPress 的用户来说,Pantheon 有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
(3)队列 Reids 在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得 Redis 能作为一个很好的消息队列平台来使用。Redis 作为队列使用的操作,就类似于本地程序语言(如 Python)对 list 的 push/pop 操作。 如果你快速的在 Google 中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用 Redis 创建非常好的后端工具,以满足各种队列需求。例如,Celery 有一个后台就是使用 Redis 作为 broker,你可以从这里去查看。
(4)排行榜/计数器 Redis 在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis 只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的 10 个用户–我们称之为“user_scores”,我们只需要像下面一样执行即可: 当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行: ZRANGE user_scores 0 10 WITHSCORES Agora Games 就是一个很好的例子,用 Ruby 实现的,它的排行榜就是使用 Redis 来存储数据的,你可以在这里看到。
(5)发布/订阅 最后(但肯定不是最不重要的)是 Redis 的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用 Redis 的发布/订阅功能来建立聊天系统!(不,这是真的,你可以去核实)。
Redis 提供的所有特性中,我感觉这个是喜欢的人最少的一个,虽然它为用户提供如果此多功能。
# 计数器
可以对 String 进行自增自减运算,INCR/DECR 实现点赞数、访问量统计,从而实现计数器功能。
redis> SET mykey "10"
"OK"
redis> INCR mykey
(integer) 11
redis> GET mykey
"11"
2
3
4
5
6
Redis 这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量。
# 缓存
将热点数据放到内存中,设置内存的最大使用量以及淘汰策略来保证缓存的命中率。(如商品信息、用户会话)
# 查找表
例如 DNS 记录就很适合使用 Redis 进行存储。
查找表和缓存类似,也是利用了 Redis 快速的查找特性。但是查找表的内容不能失效,而缓存的内容可以失效,因为缓存不作为可靠的数据来源。
# 消息队列
List 是一个双向链表,可以通过 lpush 和 rpop 写入和读取消息
不过最好使用 Kafka、RabbitMQ 等消息中间件。
# 常用的业务场景
- 电商:商品缓存、库存计数、订单状态缓存、秒杀(Redis 原子操作 + 限流)。
- 社交:用户在线状态、好友关系(Set)、动态时间线(Sorted Set)。
- 游戏:排行榜(Sorted Set)、玩家数据缓存、实时统计(如在线人数、得分)。
- 金融:交易缓存、风控数据存储(如 IP 黑名单,Set 存储)、实时汇率缓存。
- 日志:日志聚合(HyperLogLog 统计 UV)、操作记录(List 存储)。
# 会话缓存
可以使用 Redis 来统一存储多台应用服务器的会话信息。
当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性。
# 分布式锁实现
Redis 分布式锁是一种基于 Redis 实现的分布式锁机制。在分布式系统中,多个节点同时访问共享资源时,为了保证数据的一致性和避免冲突,需要使用分布式锁来控制并发访问。
Redis 分布式锁的实现原理通常是通过在 Redis 中设置一个特定的键值对来实现。当一个节点需要获取锁时,它尝试在 Redis 中设置一个指定的键值对,如果设置成功,则表示获取到了锁;如果设置失败,则表示锁已被其他节点占用。
为了避免死锁和解决锁的争抢问题,Redis 分布式锁通常会设置一个过期时间,节点在获取到锁后需要在一定时间内完成操作,并在操作完成后释放锁。同时,为了保证锁的可靠性,还需要考虑锁的可重入性、防止误删锁等问题。
使用 Redis 分布式锁可以有效地解决分布式系统中的并发访问问题,保证数据的一致性和避免冲突。但需要注意的是,Redis 分布式锁并不能解决所有的并发访问问题,如网络延迟、节点宕机等情况仍然需要额外的处理机制。
- 如果在 setnx 之后执行 expire 之前进程意外 crash 或者要重启维护了,那会怎么样?
如果在执行SETNX(尝试获取锁)之后、执行EXPIRE(设置锁的过期时间)之前进程意外崩溃或需要重启维护,可能会导致以下情况之一:
锁无法过期:如果进程崩溃或重启维护之前没有设置锁的过期时间,那么锁可能会一直存在于 Redis 中,导致其他节点无法获取到该锁。
锁过早释放:如果进程崩溃或重启维护之前已经执行了
SETNX成功,并且在EXPIRE之前崩溃,那么锁可能会在进程重启后自动释放,导致其他节点错误地获取到了该锁。
为了解决这些问题,可以采取以下措施:
使用官方推荐的原子操作:
SET key value NX EX timeout来替代SETNX和EXPIRE组合操作。这种原子操作能够一次性完成锁的获取和过期时间的设置,从而避免了中间状态的出现。这样即使进程崩溃或重启维护,锁也会在一定时间后自动过期,避免长时间占用锁资源。使用续约机制:为了避免在进程意外崩溃或重启维护时导致锁永远得不到释放,可以考虑使用锁的续租(Renewal)机制。续租机制可以在锁的过期时间即将到达时,通过重置锁的过期时间来延长锁的有效期。
具体的实现方式如下:
- 在执行
SETNX成功后,立即执行EXPIRE设置锁的过期时间。 - 启动一个后台的定时任务,定期检查锁的剩余过期时间。
- 当检测到锁的剩余过期时间接近设定的阈值时,重新设置锁的过期时间,延长锁的有效期。
这样,即使进程意外崩溃或重启维护,定时任务会在锁的过期时间接近时继续延长锁的有效期,确保锁不会无法释放。
需要注意的是,续租机制并不能完全解决所有情况下的锁释放问题,例如节点宕机等极端情况。在分布式系统中,通常需要综合考虑多种因素,如心跳检测、选举机制等来保证锁的可靠性和一致性。
- 在执行
使用分布式锁框架:可以使用已经实现了锁续约、自动释放锁等功能的分布式锁框架,如 Redlock、Redisson 等。这些框架提供了更完善的分布式锁解决方案,可以避免一些常见的问题。
需要根据具体的业务场景和需求来选择合适的处理方式,以确保分布式锁的可靠性和一致性。
在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。
可以使用 Redis 自带的 SETNX 命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
分布式锁:在分布式系统中,保证多个进程 / 线程对共享资源的互斥访问(如秒杀中的库存扣减,防止超卖)。
作用:
- 互斥性:同一时间只有一个客户端持有锁。
- 防止死锁:设置过期时间,避免锁未释放(如客户端宕机)。
- 可重入性:支持同一客户端多次获取锁(可选,如 Redisson 的可重入锁)。
Redis 实现:
SETNX(SET if Not eXists):SET key value NX EX seconds(原子操作,设置键并过期时间,确保互斥和自动释放)。
import time import uuid import threading from typing import Optional import redis from redis.lock import Lock class RedisDistributedLock: """基于 Redis 实现的分布式锁""" def __init__(self, redis_client: redis.Redis, lock_name: str, expire_time: int = 30, auto_renew: bool = False): """ 初始化分布式锁 Args: redis_client: Redis 客户端实例 lock_name: 锁的名称 expire_time: 锁的过期时间(秒) auto_renew: 是否自动续期 """ self.redis_client = redis_client self.lock_name = lock_name self.expire_time = expire_time self.auto_renew = auto_renew self.lock_value = str(uuid.uuid4()) # 唯一标识锁的持有者 self.renew_thread = None self._stop_renew = threading.Event() def acquire(self, blocking: bool = True, timeout: Optional[float] = None) -> bool: """ 获取锁 Args: blocking: 是否阻塞等待 timeout: 等待锁的超时时间(秒) Returns: 是否成功获取锁 """ start_time = time.time() while True: # 使用 SETNX 命令原子性地获取锁 acquired = self.redis_client.set( self.lock_name, self.lock_value, nx=True, ex=self.expire_time ) if acquired: # 成功获取锁,启动自动续期线程 if self.auto_renew: self._start_renew() return True if not blocking or (timeout is not None and time.time() - start_time > timeout): return False # 短暂休眠避免频繁重试 time.sleep(0.1) def release(self) -> bool: """ 释放锁 Returns: 是否成功释放锁 """ # 停止自动续期 self._stop_renew.set() if self.renew_thread and self.renew_thread.is_alive(): self.renew_thread.join(timeout=1.0) # 使用 Lua 脚本确保原子性地释放锁 lua_script = """ if redis.call("GET", KEYS[1]) == ARGV[1] then return redis.call("DEL", KEYS[1]) else return 0 end """ return self.redis_client.eval(lua_script, 1, self.lock_name, self.lock_value) def _start_renew(self) -> None: """启动自动续期线程""" self._stop_renew.clear() self.renew_thread = threading.Thread(target=self._renew_lock_periodically) self.renew_thread.daemon = True self.renew_thread.start() def _renew_lock_periodically(self) -> None: """定期续期锁""" while not self._stop_renew.wait(timeout=self.expire_time / 3): # 使用 Lua 脚本确保原子性地续期锁 lua_script = """ if redis.call("GET", KEYS[1]) == ARGV[1] then return redis.call("PEXPIRE", KEYS[1], ARGV[2]) else return 0 end """ # 续期时间为毫秒 self.redis_client.eval(lua_script, 1, self.lock_name, self.lock_value, self.expire_time * 1000) # 使用示例plainplainplainplainplainplain if __name__ == "__main__": # 创建 Redis 客户端 redis_client = redis.Redis(host='localhost', port=6379, db=0) # 创建分布式锁实例 with RedisDistributedLock(redis_client, "my_distributed_lock", expire_time=30, auto_renew=True) as lock: if lock.acquire(blocking=True, timeout=10): try: print("成功获取锁,执行关键代码") # 模拟需要加锁的业务逻辑 time.sleep(20) finally: # 确保锁被释放 lock.release() print("锁已释放") else: print("获取锁超时")1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126Redisson:提供分布式锁的高级实现(可重入、看门狗自动续期等),简化开发。
# 其它
Set 可以实现交集、并集等操作,从而实现共同好友等功能。
ZSet 可以实现有序性操作,从而实现排行榜等功能。
# Redis 与 Memcached 对比
两者都是非关系型内存键值数据库,主要有以下不同:
# 数据类型丰富
Memcached 仅支持字符串类型,而 Redis 支持五种不同的数据类型,可以更灵活地解决问题。
# 数据持久化
Redis 支持两种持久化策略:RDB 快照和 AOF 日志,而 Memcached 不支持持久化。
# 分布式
Memcached 不支持分布式,只能通过在客户端使用一致性哈希来实现分布式存储,这种方式在存储和查询时都需要先在客户端计算一次数据所在的节点。
Redis Cluster 实现了分布式的支持。
# 内存管理机制
在 Redis 中,并不是所有数据都一直存储在内存中,可以将一些很久没用的 value 交换到磁盘,而 Memcached 的数据则会一直在内存中。
Memcached 将内存分割成特定长度的块来存储数据,以完全解决内存碎片的问题。但是这种方式会使得内存的利用率不高,例如块的大小为 128 bytes,只存储 100 bytes 的数据,那么剩下的 28 bytes 就浪费掉了。
# 缓存问题
以下是关于 Redis 缓存穿透、缓存击穿、缓存雪崩的对比图表,结合定义、成因、影响及解决方案,并附补充说明:
# 对比图表
| 维度 | 缓存穿透 | 缓存击穿 | 缓存雪崩 |
|---|---|---|---|
| 定义 | 查询不存在的 key,请求直达数据库 | 热点 key在缓存过期瞬间,大量请求直达数据库 | 大量缓存 key 同时过期或Redis 服务宕机,导致请求直达数据库 |
| 成因 | 1. 恶意攻击(如大量无效 key) 2. 业务逻辑错误(如参数校验缺失) | 1. 热点 key 过期时间集中 2. 并发量突然激增 | 1. 缓存过期时间设置过于集中 2. Redis 集群故障(如主节点宕机) |
| 典型场景 | 恶意调用 API 查询不存在的用户 ID | 秒杀活动中,商品 ID 对应的缓存过期瞬间 | 电商大促时,大量商品缓存同时过期或 Redis 集群崩溃 |
| 影响 | 数据库被无效请求压垮,可能导致宕机 | 数据库瞬间承受高并发压力,响应延迟激增 | 数据库被海量请求击穿,系统整体崩溃或服务不可用 |
| 核心解决方案 | 1. 布隆过滤器:提前过滤无效 key 2. 缓存空值:将无效 key 的空结果缓存(设短过期时间) 3. 参数校验:严格校验请求参数合法性 | 1. 互斥锁(如 Redisson):保证同一时间只有一个线程重建缓存 2. 热点 key 永不过期:通过异步线程更新缓存,避免主动过期 3. 随机退避:请求重试时添加随机延迟,避免集中请求 | 1. 分散过期时间:在基础过期时间上添加随机值(如 TTL=300+random(100)) 2. Redis 高可用架构:主从+哨兵/Cluster,避免单点故障 3. 流量控制:熔断(如 Hystrix)、限流(如 Guava RateLimiter) 4. 降级策略:返回默认值或静态页面,减轻数据库压力 |
| 补充说明 | - 空值缓存会占用内存,需合理设置过期时间 - 布隆过滤器适用于数据基数固定的场景 | - 互斥锁可能引入性能开销,需评估并发量 - 永不过期需配合异步更新机制 | - 监控缓存命中率、数据库 QPS,设置预警机制 - 避免全量数据同时加载到缓存 |
# 扩展对比图(示意图)
┌───────────────┐
│ 缓存穿透 │
│ (无效key) │
└──────┬────────┘
▼
┌───────────────┐ ┌───────────────┐
│ 布隆过滤器 │ │ 缓存空值 │
└──────┬────────┘ └──────┬────────┘
▼ ▼
┌───────▼───────┐ ┌──────▼─────────┐
│ 拒绝请求 │ │ 返回空值 │
└───────────────┘ └───────────────┘
┌───────────────┐
│ 缓存击穿 │
│ (热点key过期)│
└──────┬────────┘
▼
┌───────────────┐ ┌─────────────────┐
│ 互斥锁(加锁) │ │ 永不过期+异步更新 │
└──────┬────────┘ └──────┬──────────┘
▼ ▼
┌───────▼────────┐ ┌──────▼─────────┐
│ 重建缓存 │ │ 直接返回缓存值 │
└───────────────┘ └─────────────────┘
┌────────────────────┐
│ 缓存雪崩 │
│ (大量key过期/宕机)│
└──────┬────────────┘
▼
┌───────────────┐ ┌───────────────┐
│ 分散过期时间 │ │ 高可用架构 │
└──────┬────────┘ └──────┬────────┘
▼ ▼
┌───────▼────────┐ ┌──────▼─────────┐
│ 避免集中失效 │ │ 故障转移 │
└───────────────┘ └───────────────┘
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 总结
- 缓存穿透:聚焦无效请求,需从“过滤”和“兜底”层面解决。
- 缓存击穿:针对单个热点 key,核心是“防止并发重建缓存”。
- 缓存雪崩:关注系统性风险,需通过架构设计和流量控制提升稳定性。
实际应用中,可结合业务场景组合使用多种方案(如布隆过滤器+互斥锁+分散过期时间),并通过监控工具(如 Prometheus、Redis Insight)实时跟踪缓存状态,提前预警潜在风险。
# 缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据会导致数据库压力过大,严重会击垮数据库。
- 解决办法
- 数据校验,非法请求拦截
- 布隆过滤器(Bloom Filter)
- Nginx 黑名单过滤
# 缓存击穿
指一个 Key 非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个 Key 在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个完好无损的桶上凿开了一个洞。
- 解决办法
- 加互斥锁
- 设置热点数据永远不过期
参考:
Redis 缓存雪崩、击穿、穿透 - SegmentFault 思否 (opens new window)
《今天面试了吗》-Redis (opens new window)
# 缓存雪崩
一般缓存都是定时任务去刷新,或者是查不到之后去更新的,定时任务刷新就有一个问题:
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。这个没有完美解决办法,但可以分析用户行为,尽量让失效时间点均匀分布。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
- 解决办法
- 在批量往 Redis 存数据的时候,把每个 Key 的失效时间都加个随机值就好了,这样可以保证数据不会在同一时间大面积失效
- Redis 是集群部署,将热点数据均匀分布在不同的 Redis 库中也能避免全部失效的问题
- 设置热点数据永远不过期,有更新操作就更新缓存
# 键的过期时间
Redis 可以为每个键设置过期时间,当键过期时,会自动删除该键。
对于散列表这种容器,只能为整个键设置过期时间(整个散列表),而不能为键里面的单个元素设置过期时间。
# 过期键删除策略
定时过期
每个设置过期时间的 key 都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的 CPU 资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
惰性过期
只有当访问一个 key 时,才会判断该 key 是否已过期,过期则清除。该策略可以最大化地节省 CPU 资源,却对内存非常不友好。极端情况可能出现大量的过期 key 没有再次被访问,从而不会被清除,占用大量内存。
定期过期
每隔一定的时间,会扫描一定数量的数据库的 expires 字典中一定数量的 key,并清除其中已过期的 key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得 CPU 和内存资源达到最优的平衡效果。 (expires 字典会保存所有设置了过期时间的 key 的过期时间数据,其中,key 是指向键空间中的某个键的指针,value 是该键的毫秒精度的 UNIX 时间戳表示的过期时间。键空间是指该 Redis 集群中保存的所有键。)
# Redis 如何做内存优化
- 数据结构优化:
- 使用 Hash 存储对象(减少键数量,如用户信息:user:{id} 拆分为 user:{id}:name 等,不如直接用哈希 user:{id} 存储多个字段)。
- 小数据使用压缩列表(如列表、哈希、集合元素少时,Redis 自动使用 ziplist,节省内存)。
- 避免大键(如大字符串、大列表),拆分或压缩存储。
- 配置优化:
- 设置合理的过期时间,自动清理无效数据。
- 启用内存淘汰策略(如 allkeys-lru),释放内存。
- 定期清理:使用 SCAN 遍历键,删除无用键(如前缀匹配删除)。
# 数据淘汰策略
可以设置内存最大使用量,当内存使用量超出时,会施行数据淘汰策略。
Redis 具体有 6 种淘汰策略:
| 策略 | 描述 |
|---|---|
| volatile-lru | 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰 |
| volatile-ttl | 从已设置过期时间的数据集中挑选将要过期的数据淘汰 |
| volatile-random | 从已设置过期时间的数据集中任意选择数据淘汰 |
| allkeys-lru | 从所有数据集中挑选最近最少使用的数据淘汰 |
| allkeys-random | 从所有数据集中任意选择数据进行淘汰 |
| noeviction | 禁止驱逐数据 |
| volatile - lfu(Redis 4.0 引入) | 从已设置过期时间的数据集中挑选访问频率最少的数据淘汰 |
| allkeys - lfu(Redis 4.0 引入) | 从所有数据集中挑选访问频率最少的数据淘汰 |
作为内存数据库,出于对性能和内存消耗的考虑,Redis 的淘汰算法实际实现上并非针对所有 key,而是抽样一小部分并且从中选出被淘汰的 key。
使用 Redis 缓存数据时,为了提高缓存命中率,需要保证缓存数据都是热点数据。可以将内存最大使用量设置为热点数据占用的内存量,然后启用 allkeys-lru 淘汰策略,将最近最少使用的数据淘汰。
Redis 4.0 引入了 volatile-lfu 和 allkeys-lfu 淘汰策略,LFU 策略通过统计访问频率,将访问频率最少的键值对淘汰。
使用策略规则:
如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用 allkeys-lru
如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用 allkeys-random
# 持久化
# 事务
Redis 支持事务。Redis 的事务是通过 MULTI、EXEC、WATCH 和 UNWATCH、DISCARD 等命令实现的。
- MULTI 命令用于开启一个事务
- WATCH 和 UNWATCH 命令用于对事务进行监视和取消监视。在事务中,所有的命令都会被放入一个队列中,直到执行 EXEC 命令时才会一起执行。如果在执行 EXEC 命令之前,有其他客户端对被监视的键进行了修改,那么事务将会被取消,不会执行任何命令。
- DISCARD:取消事务并清空事务队列。当执行 DISCARD 命令后,Redis 会取消当前客户端的事务,并清空事务队列中的所有命令。这意味着事务中的所有命令都不会被执行。DISCARD 命令可以用于放弃之前的事务,重新开始一个新的事务。
- EXEC 命令用于执行事务中的命令
是否满足 ACID
- Redis 具备了一定的原子性,但不支持回滚。
笔记
DISCARD 命令只能取消当前事务中的命令执行,并不能回滚已经执行的命令。
在 Redis 事务中,如果 EXEC 命令执行过程中发生了错误,比如其中一个命令执行失败,那么事务中所有已经执行的命令都会被回滚,但是 Redis 并不会抛出异常或者提供回滚的机制。因此,Redis 的事务并不保证原子性。
- Redis 具备 ACID 中一致性的概念。
- Redis 具备隔离性。
- Redis 无法保证持久性。
- Redis 具备了一定的原子性,但不支持回滚。
Redis 的事务支持机制与传统关系型数据库有显著差异,核心要点如下:
# 一、事务基础支持
事务命令组
通过
MULTI开启事务队列,EXEC执行队列命令,DISCARD放弃事务示例流程:
> MULTI > SET user:1 "Alice" > INCR counter > EXEC1
2
3
4所有命令一次性提交执行
原子性特性
- 语法错误原子性:队列中存在语法错误命令(如
SETT)时,EXEC会拒绝执行所有命令 - 运行时错误非原子性:逻辑错误(如对字符串执行
INCR)只会跳过错误命令,其他命令仍执行
- 语法错误原子性:队列中存在语法错误命令(如
# 二、与传统事务的区别
| 特性 | Redis 事务 | 传统数据库事务 (如 MySQL) |
|---|---|---|
| 原子性 | 仅保证队列整体提交,逻辑错误不中断 | 完全原子性(失败则全部回滚) |
| 回滚能力 | 不支持命令执行后的回滚 | 支持完整回滚 |
| 隔离性 | 单线程模型天然隔离 | 通过锁机制实现多级隔离 |
# 三、扩展控制功能
乐观锁机制
WATCH命令监控指定键值,若被修改则事务自动终止示例:
WATCH balance MULTI DECRBY balance 50 EXEC # 若balance被其他客户端修改,此处返回nil1
2
3
4
批量操作优化
- 通过事务替代多次网络往返,降低延迟
- 适合非强一致性场景(如计数器批量更新)
# 四、生产建议
适用场景
- 批量操作非关联性命令(如更新多个缓存键)
- 结合
WATCH实现简单乐观锁控制
规避风险
- 避免在事务中混合读/写逻辑复杂操作
- 对关键业务需补充应用层补偿机制(如日志重试)
Redis 事务通过命令队列 + 单线程执行实现了轻量级事务模型,但需明确其无法完全替代传统数据库事务的 ACID 特性。
# 引用链接
- Redis 到底支不支持事务? - CSDN 博客 (opens new window)
- Redis 到底支不支持事务啊? - CSDN 博客 (opens new window)
- Redis 支持事务吗?如何实现? - 掘金开发者社区 (opens new window)
- redis 支持事务吗? - 博客园 (opens new window)
- Redis 事务:原子性与回滚的真相揭秘 - 程序那点事 (opens new window)
- 让你彻底搞懂 Redis 事务 - 程序那点事 (opens new window)
- redis 自带的事务功能很鸡肋 - 51CTO 博客 (opens new window)
- Redis 支持事务吗?Redis 为什么不严格保证事务 ACID?_redis 支持事务吗,如果支持为啥不能回滚,不支持原子性是如何保证的?-CSDN 博客 - CSDN 博客 (opens new window)
- 【redis】事务详解,相关命令 multi、exec、discard 与 watch 的原理 - cloud.tencent.com.cn (opens new window)
- 0x08.Redis 支持事务吗?如何实现? - CSDN 博客 (opens new window)
- 一文讲透 Redis 事务 (事务模式 VS Lua 脚本) - 无响应三线程 (opens new window)
- 这些年背过的面试题——Redis 篇 - 阿里云开发者社区 (opens new window)
- Redis 实现分布式事务的示例 - 脚本之家 (opens new window)
- Redis 中的事务和 Redis 乐观锁详解 - 脚本之家 (opens new window)
- Redis 高性能内存数据库(四) - 博客园 (opens new window)
- Redis | Redis 的事务一-阿里云开发者社区 - 阿里云开发者社区 (opens new window)
- 不可不知的 Redis 秘籍:事务命令全攻略! - 云端源想 (opens new window)
- 多实例服务使用 redis 分布式锁 redis 实现分布式事务控制 - 51CTO 博客 (opens new window)
- 剖析!Redis 事务实现原理 - 宠物知识科普 (opens new window)
- 一文讲透 Redis 事务 - 腾讯云 (opens new window)
- redis 管道和事务 redis 事务实现原理 - 51CTO 博客 (opens new window)
- 【redis】-- redis 的事务 - 博客园 (opens new window)
- Redis 事务支持 ACID 么? - 知乎 (opens new window)
# 事件
Redis 服务器是一个事件驱动程序。
# 文件事件
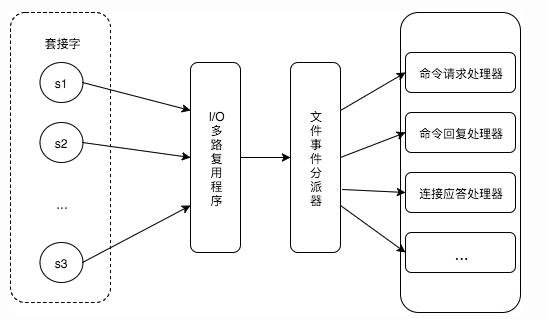
服务器通过套接字与客户端或者其它服务器进行通信,文件事件就是对套接字操作的抽象。
Redis 基于 Reactor 模式开发了自己的网络事件处理器,使用 I/O 多路复用程序来同时监听多个套接字,并将到达的事件传送给文件事件分派器,分派器会根据套接字产生的事件类型调用相应的事件处理器。
# 时间事件
服务器有一些操作需要在给定的时间点执行,时间事件是对这类定时操作的抽象。
时间事件又分为:
- 定时事件:是让一段程序在指定的时间之内执行一次;
- 周期性事件:是让一段程序每隔指定时间就执行一次。
Redis 将所有时间事件都放在一个无序链表中,通过遍历整个链表查找出已到达的时间事件,并调用相应的事件处理器。
# 事件的调度与执行
服务器需要不断监听文件事件的套接字才能得到待处理的文件事件,但是不能一直监听,否则时间事件无法在规定的时间内执行,因此监听时间应该根据距离现在最近的时间事件来决定。
事件调度与执行由 aeProcessEvents 函数负责,伪代码如下:
def aeProcessEvents():
# 获取到达时间离当前时间最接近的时间事件
time_event = aeSearchNearestTimer()
# 计算最接近的时间事件距离到达还有多少毫秒
remaind_ms = time_event.when - unix_ts_now()
# 如果事件已到达,那么 remaind_ms 的值可能为负数,将它设为 0
if remaind_ms < 0:
remaind_ms = 0
# 根据 remaind_ms 的值,创建 timeval
timeval = create_timeval_with_ms(remaind_ms)
# 阻塞并等待文件事件产生,最大阻塞时间由传入的 timeval 决定
aeApiPoll(timeval)
# 处理所有已产生的文件事件
procesFileEvents()
# 处理所有已到达的时间事件
processTimeEvents()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
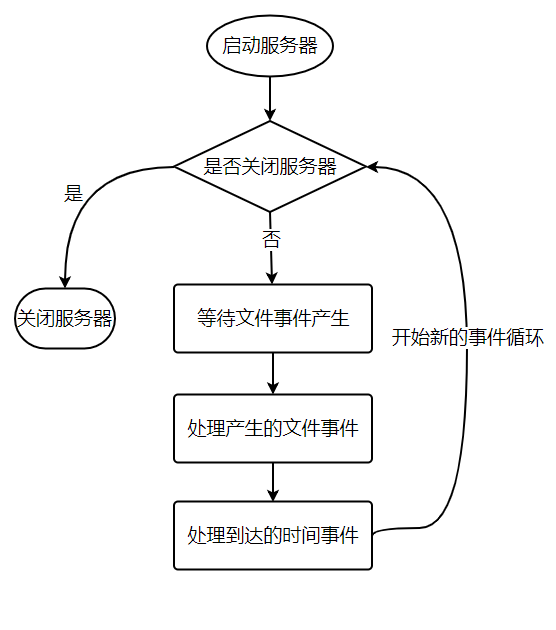
将 aeProcessEvents 函数置于一个循环里面,加上初始化和清理函数,就构成了 Redis 服务器的主函数,伪代码如下:
def main():
# 初始化服务器
init_server()
# 一直处理事件,直到服务器关闭为止
while server_is_not_shutdown():
aeProcessEvents()
# 服务器关闭,执行清理操作
clean_server()
2
3
4
5
6
7
8
从事件处理的角度来看,服务器运行流程如下:
# 复制
通过使用 slaveof host port 命令来让一个服务器成为另一个服务器的从服务器。
一个从服务器只能有一个主服务器,并且不支持主主复制。
# 连接过程
主服务器创建快照文件,发送给从服务器,并在发送期间使用缓冲区记录执行的写命令。快照文件发送完毕之后,开始向从服务器发送存储在缓冲区中的写命令;
从服务器丢弃所有旧数据,载入主服务器发来的快照文件,之后从服务器开始接受主服务器发来的写命令;
主服务器每执行一次写命令,就向从服务器发送相同的写命令。
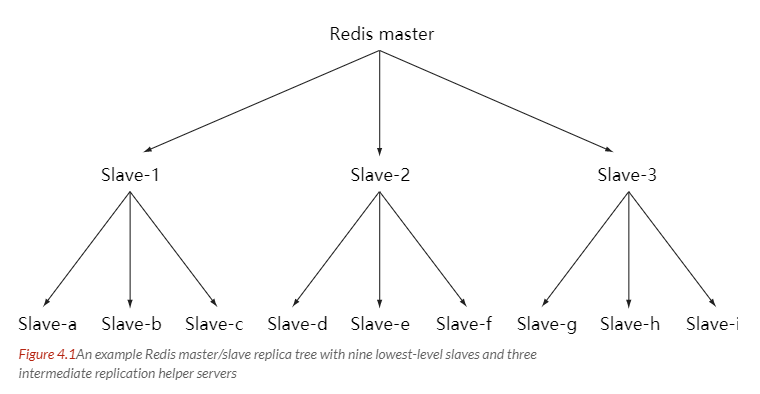
# 主从链
随着负载不断上升,主服务器可能无法很快地更新所有从服务器,或者重新连接和重新同步从服务器将导致系统超载。为了解决这个问题,可以创建一个中间层来分担主服务器的复制工作。中间层的服务器是最上层服务器的从服务器,又是最下层服务器的主服务器。
# Sentinel
Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入下线状态时,自动从从服务器中选举出新的主服务器。
# 分片
分片是将数据划分为多个部分的方法,可以将数据存储到多台机器里面,这种方法在解决某些问题时可以获得线性级别的性能提升。
假设有 4 个 Redis 实例 R0,R1,R2,R3,还有很多表示用户的键 user:1,user:2,... ,有不同的方式来选择一个指定的键存储在哪个实例中。
- 最简单的方式是范围分片,例如用户 id 从 0~1000 的存储到实例 R0 中,用户 id 从 1001~2000 的存储到实例 R1 中,等等。但是这样需要维护一张映射范围表,维护操作代价很高。
- 还有一种方式是哈希分片,使用 CRC32 哈希函数将键转换为一个数字,再对实例数量求模就能知道应该存储的实例。
根据执行分片的位置,可以分为三种分片方式:
- 客户端分片:客户端使用一致性哈希等算法决定键应当分布到哪个节点。
- 代理分片:将客户端请求发送到代理上,由代理转发请求到正确的节点上。
- 服务器分片:Redis Cluster。
# 一个简单的论坛系统分析
该论坛系统功能如下:
- 可以发布文章;
- 可以对文章进行点赞;
- 在首页可以按文章的发布时间或者文章的点赞数进行排序显示。
# 文章信息
文章包括标题、作者、赞数等信息,在关系型数据库中很容易构建一张表来存储这些信息,在 Redis 中可以使用 HASH 来存储每种信息以及其对应的值的映射。
Redis 没有关系型数据库中的表这一概念来将同种类型的数据存放在一起,而是使用命名空间的方式来实现这一功能。键名的前面部分存储命名空间,后面部分的内容存储 ID,通常使用 : 来进行分隔。例如下面的 HASH 的键名为 article:92617,其中 article 为命名空间,ID 为 92617。

# 点赞功能
当有用户为一篇文章点赞时,除了要对该文章的 votes 字段进行加 1 操作,还必须记录该用户已经对该文章进行了点赞,防止用户点赞次数超过 1。可以建立文章的已投票用户集合来进行记录。
为了节约内存,规定一篇文章发布满一周之后,就不能再对它进行投票,而文章的已投票集合也会被删除,可以为文章的已投票集合设置一个一周的过期时间就能实现这个规定。

# 对文章进行排序
为了按发布时间和点赞数进行排序,可以建立一个文章发布时间的有序集合和一个文章点赞数的有序集合。(下图中的 score 就是这里所说的点赞数;下面所示的有序集合分值并不直接是时间和点赞数,而是根据时间和点赞数间接计算出来的)

# 参考资料
- Carlson J L. Redis in Action[J]. Media.johnwiley.com.au, 2013.
- 黄健宏. Redis 设计与实现 [M]. 机械工业出版社, 2014. (opens new window)
- REDIS IN ACTION (opens new window)
- Skip Lists: Done Right (opens new window)
- 论述 Redis 和 Memcached 的差异 (opens new window)
- Redis 3.0 中文版- 分片 (opens new window)
- Redis 应用场景 (opens new window)
- Using Redis as an LRU cache (opens new window)