 Redis 中的底层数据结构(3)——字典(dict)
Redis 中的底层数据结构(3)——字典(dict)
本文将详细说明 Redis 中字典的实现。
在 Redis 源码(这里使用 3.2.11 版本)中,字典的实现在dict.h和dict.c中。
# Redis 字典概述
# 1.Redis 字典的数据结构示意图
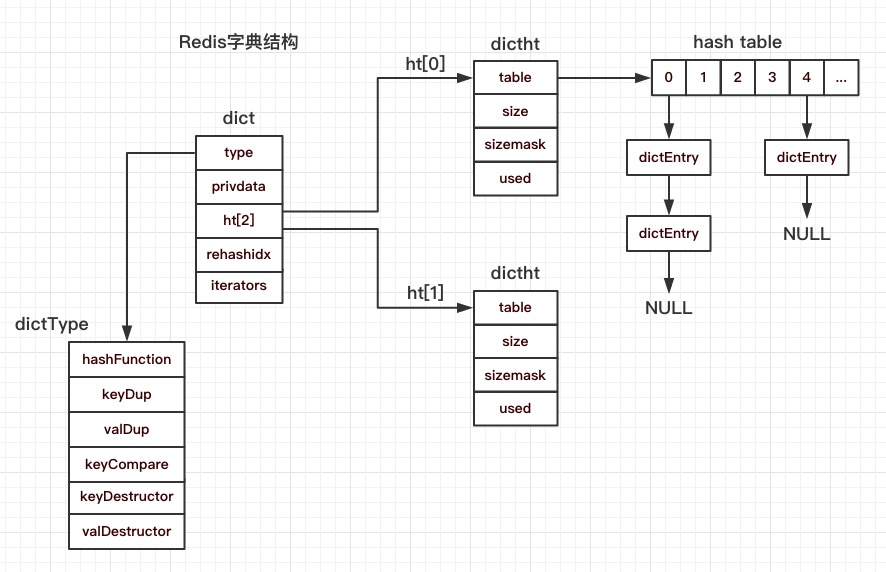
# 2.Redis 字典概述
dict 的 type 属性是一个 dictType 类型的结构体指针,dictType 结构体包含了字典的哈希函数、复制 key、复制 value、销毁 key、销毁 value 和比较两个 key 的函数指针。ht[2]维护了两个 dictht,ht[0]和 ht[1]。ht[0]主要负责保存字典哈希表的散列数组内容,即一堆 dictEntry。ht[1]用于 rehash,rehash 的内容在之后会详细说明。dictht 的table是一个 dictEntry 指针的数组,这里面的每一个元素都是一个 dictEntry,当有新的 key-value 时,先用哈希函数计算散列值,再将散列值映射到散列数组中,然后用 dictEntry 包装 key-value pair,放入散列数组相应的槽中,如果有多个 key 的散列值相同,它们将在散列数组中位于同一个槽中,相邻的 dictEntry 的next指针链接起来,形成一个 dictEntry 链表,这个链表的头节点保存在散列数组的相应槽中。
# 3.Redis 字典的哈希函数
dict.c源码中提供了三种哈希函数,分别是:
1). dictIntHashFunction: Thomas Wang's 32 bit Mix 哈希算法,对一个无符号整型数进行一系列的移位运算,效率较高。
2). dictGenHashFunction: Austin Appleby 的 MurmurHash2 算法。
3). dictGenCaseHashFunction: 一个对大小写不敏感的哈希函数(基于 djb 哈希算法)。
有兴趣的同学可以直接阅读dict.c的 hash functions 部分。
# 4.Rehash 过程
由于一个字典哈希表的散列数组具有一个初始的大小,这在dict.h中有定义:
#define DICT_HT_INITIAL_SIZE 4
之后如果向该字典中添加更多的 key-value pair,就需要扩充散列数组的大小,另外如果一个字典原来有很多 key,之后又删除了一部分 key,为了节省内存,也会对该字典进行缩容。这就需要进行 rehash。rehash 将字典原来的 key 重新计算散列值并映射到一个新的散列数组(大小发生改变)上。rehash 赋予字典动态扩容/缩容的能力。
Redis 处于非 rehash 时,字典中的 key 都保存在 ht[0]的散列数组中,当某一时刻需要进行 rehash 时,会在 ht[1]上扩大或缩小散列数组的大小,接着把 ht[0]里的所有 key 重新计算散列值并映射到 ht[1]的散列数组中。当完成所有 key 的 rehash 后,将 ht[0]和 ht[1]对调,原来的 ht[1]经过 rehash 成为了新的 ht[0]。
Redis 的 rehash 还有一个值得注意的特点,由于 rehash 可能比较耗时,导致 Redis 无法处理其他事情,因此 Redis 不会一次性一个字典做全量 rehash,而是把 rehash 操作分摊到很多时间点上,比如在字典中查找、新增、删除 key-value pair 时,执行一步 rehash 过程,这可以称为增量 rehash。在后面列出的代码中将会看到这是如何实现的。
# 字典中的数据结构
以下是dict.h中的字典相关的结构体代码:
/* 保存key-value对的结构体 */
typedef struct dictEntry {
void *key; // 字典键
union { // value是一个联合,只能存放下列类型值的其中一个
void *val; // 空类型指针一枚
uint64_t u64; // 无符号整型一枚
int64_t s64; // 有符号整型一枚
double d; // 双精度浮点数一枚
} v;
struct dictEntry *next; // 指向下一个键值对节点的指针
} dictEntry;
/* 字典操作的方法 */
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); // 哈希函数指针,使用key来计算哈希值
void *(*keyDup)(void *privdata, const void *key); // 复制key的函数指针
void *(*valDup)(void *privdata, const void *obj); // 复制value的函数指针
int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 比较两个key的函数指针
void (*keyDestructor)(void *privdata, void *key); // 销毁key的函数指针
void (*valDestructor)(void *privdata, void *obj); // 销毁value的函数指针
} dictType;
/* 这是我们的哈希表结构。每个字典都有两个这样的结构,因为
* 我们实现了从旧哈希表迁移数据到新哈希表的增量rehash。
*/
/* 哈希表结构 */
typedef struct dictht {
dictEntry **table; // 散列数组
unsigned long size; // 散列数组长度
unsigned long sizemask; // 散列数组长度掩码 = 散列数组长度-1
unsigned long used; // 散列数组中已经被使用的节点数量
} dictht;
/* 字典结构 */
typedef struct dict {
dictType *type; // 字典类型
void *privdata; // 私有数据
dictht ht[2]; // 一个字典中有两个哈希表,原因如上述
long rehashidx; // 数据rehash的当前索引位置
int iterators; // 当前使用的迭代器数量
} dict;
/* 如果safe被设置成1则表示这是一个安全的迭代器,这意味着你可以在迭代字典时调用
* dictAdd、dictFind等一些函数。否则这是一个不安全的迭代器,只能在迭代时调用
* dictNext()函数。
*/
/* 字典迭代器 */
typedef struct dictIterator {
dict *d; // 字典指针
long index; // 散列数组的当前索引值
int table, safe; // 哈希表编号(0/1)和安全标志
dictEntry *entry, *nextEntry; // 当前键值对结构体指针,下一个键值对结构体指针
long long fingerprint; // 字典的指纹
} dictIterator;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
以下是dict.h中的函数原型,宏部分只列出了DICT_HT_INITIAL_SIZE:
/* 散列数组的初始大小 */
#define DICT_HT_INITIAL_SIZE 4
#define dictHashKey(d, key) (d)->type->hashFunction(key) // 获取指定key的哈希值
#define dictGetKey(he) ((he)->key) // 获取指定节点的key
#define dictGetVal(he) ((he)->v.val) // 获取指定节点的value
#define dictGetSignedIntegerVal(he) ((he)->v.s64) // 获取指定节点的value,值为signed int
#define dictGetUnsignedIntegerVal(he) ((he)->v.u64) // 获取指定节点的value,值为unsigned int
#define dictGetDoubleVal(he) ((he)->v.d) // 获取指定节点的value,值为double
#define dictSlots(d) ((d)->ht[0].size+(d)->ht[1].size) // 获取字典中哈希表的总长度,总长度=哈希表1散列数组长度+哈希表2散列数组长度
#define dictSize(d) ((d)->ht[0].used+(d)->ht[1].used) // 获取字典中哈希表已被使用的节点数量,已被使用的节点数量=哈希表1散列数组已被使用的节点数量+哈希表2散列数组已被使用的节点数量
#define dictIsRehashing(d) ((d)->rehashidx != -1) // 字典当前是否正在进行rehash操作
/* API */
dict *dictCreate(dictType *type, void *privDataPtr); // 创建一个字典
int dictExpand(dict *d, unsigned long size); // 扩充字典大小
int dictAdd(dict *d, void *key, void *val); // 向字典中添加键值对
dictEntry *dictAddRaw(dict *d, void *key); // 向字典中添加一个只有key的dictEntry
int dictReplace(dict *d, void *key, void *val); // 设置/替换指定key的value(key不存在就设置key-value,存在则替换value)
dictEntry *dictReplaceRaw(dict *d, void *key); // 和dictReplace,设置/替换指定key(只设置key)
int dictDelete(dict *d, const void *key); // 根据key删除字典中的一个key-value对
int dictDeleteNoFree(dict *d, const void *key); // 根据key删除字典中的一个key-value对,但并不释放相应的key和value
void dictRelease(dict *d); // 释放一个字典
dictEntry * dictFind(dict *d, const void *key); // 根据key在字典中查找一个key-value对
void *dictFetchValue(dict *d, const void *key); // 根据key从字典中获取它对应的value
int dictResize(dict *d); // 重新计算并设置字典的哈希数组大小,调整到能包含所有元素的最小大小
dictIterator *dictGetIterator(dict *d); // 获取一个字典的普通(非安全)迭代器
dictIterator *dictGetSafeIterator(dict *d); // 获取一个字典的安全迭代器
dictEntry *dictNext(dictIterator *iter); // 获取迭代器的下一个key-value对
void dictReleaseIterator(dictIterator *iter); // 释放字典迭代器
dictEntry *dictGetRandomKey(dict *d); // 随机获取字典中的一个key-value对
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count); // 从字典中随机取样count个key-value对
void dictGetStats(char *buf, size_t bufsize, dict *d); // 获取字典状态
unsigned int dictGenHashFunction(const void *key, int len); // 一种哈希算法
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len); // 对大小写不敏感的哈希算法
void dictEmpty(dict *d, void(callback)(void*)); // 清空字典数据并调用回调函数
void dictEnableResize(void); // 开启字典resize
void dictDisableResize(void); // 禁用字典resize
int dictRehash(dict *d, int n); // 字典rehash
int dictRehashMilliseconds(dict *d, int ms); // 在ms时间内rehash,超过则停止
void dictSetHashFunctionSeed(unsigned int initval); // 设置rehash函数种子
unsigned int dictGetHashFunctionSeed(void); // 获取rehash函数种子
unsigned long dictScan(dict *d, unsigned long v, dictScanFunction *fn, void *privdata); // 遍历整个字典,每次访问一个元素都会调用fn操作其数据
/* 哈希表类型 */
extern dictType dictTypeHeapStringCopyKey;
extern dictType dictTypeHeapStrings;
extern dictType dictTypeHeapStringCopyKeyValue;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 字典的实现
在实现部分,将会列出dict.c中比较重要的一些函数定义。
先看dict.c中的一些静态变量和静态函数声明:
/* dictEnableResize()和dictDisableResize()函数允许我们在需要时启用/禁用哈希表的重新规划空间的
* 功能。这对Redis来说非常重要,因为我们使用写时复制且不希望在有子进程进行保存操作时移动太多内存
* 中的数据。
*
* 需要注意的是即使dict_can_resize被设置为0,在某些情况下也会触发字典重新规划空间的操作:
* 当一个哈希表中的元素个数和散列数组(桶)的比例大于dict_force_resize_ratio时,
* 触发字典重新规划空间的操作。 */
static int dict_can_resize = 1; // 字典重新规划空间开关
static unsigned int dict_force_resize_ratio = 5; // 字典被强制进行重新规划空间时的(元素个数/桶大小)比例
static int _dictExpandIfNeeded(dict *ht); // 判断字典是否需要扩容
static unsigned long _dictNextPower(unsigned long size); // 字典扩容的大小(字典的容量都是2的整数次方大小),该函数返回大于或等于size的2的整数次方的数字最小的那个
static int _dictKeyIndex(dict *ht, const void *key); // 返回指定key在散列数组中的索引值
static int _dictInit(dict *ht, dictType *type, void *privDataPtr); // 初始化一个字典
2
3
4
5
6
7
8
9
10
11
12
13
_dictReset函数重置一个已经被 ht_init()函数初始化过的哈希表。注意:这个函数只应该被 ht_destroy()函数调用。
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
2
3
4
5
6
7
dictCreate函数创建一个哈希表。
dict *dictCreate(dictType *type, void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d)); // 分配内存
_dictInit(d,type,privDataPtr); // 初始化哈希表
return d;
}
2
3
4
5
6
7
_dictInit函数初始化哈希表。
int _dictInit(dict *d, dictType *type, void *privDataPtr)
{
_dictReset(&d->ht[0]); // 初始化第一个哈希表
_dictReset(&d->ht[1]); // 初始化第二个哈希表
d->type = type; // 初始化字典类型
d->privdata = privDataPtr; // 初始化私有数据
d->rehashidx = -1; // 初始化rehash索引
d->iterators = 0; // 初始化字典迭代器
return DICT_OK;
}
2
3
4
5
6
7
8
9
10
dictResize函数重新计算并设置字典的哈希数组大小,调整到能包含所有元素的最小大小,保持已使用节点数量/桶大小的比率接近<=1。
int dictResize(dict *d)
{
int minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR; // 禁用字典resize或当前字典正在rehash时返回错误
minimal = d->ht[0].used; // 已使用节点的数量
if (minimal < DICT_HT_INITIAL_SIZE) // 已使用节点数量小于散列数组的初始大小时,新空间大小设置为散列数组的初始大小
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal); // 扩充字典大小
}
2
3
4
5
6
7
8
9
10
dictExpand函数扩充或创建哈希表。
int dictExpand(dict *d, unsigned long size)
{
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size); // 计算一个合适的哈希表大小,大小为2的整数次方
/* 当字典正在进行rehash或字典哈希表中已使用节点数量大于size都返回错误 */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* 新的空间大小和当前的相同,没必要进行rehash */
if (realsize == d->ht[0].size) return DICT_ERR;
/* 为新的哈希表分配空间然后初始化它的所有指针为NULL */
n.size = realsize; // 新哈希表散列数组长度
n.sizemask = realsize-1; // 新哈希表散列数组长度掩码
n.table = zcalloc(realsize*sizeof(dictEntry*)); // 新哈希表散列数组空间分配
n.used = 0; // 新哈希表已使用节点数量
/* 如果d还未被初始化,就不需要rehash,直接把n赋值给字典的第一个哈希表。 */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* 准备第二个哈希表用来进行增量rehash */
d->ht[1] = n; // 1号哈希表现在是被扩展了,数据会从0号哈希表被移动到1号哈希表
d->rehashidx = 0;
return DICT_OK;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
dictRehash函数分 N 步进行增量 rehash。当旧哈希表中还有 key 没移动到新哈希表时,函数返回 1,否则返回 0。一次 rehash 过程包含把一个桶从旧哈希表移动到新哈希表(由于我们在同一个桶中使用链表形式保存 key-value 对,所以一个桶中可能有一个以上的 key 需要移动)。然而由于哈希表中可能有一部分是空的,并不能保证每一步能对至少一个桶进行 rehash,因此我们规定一步中最多只能访问 N*10 个空桶,否则这么大量的工作可能会造成一段长时间的阻塞。
int dictRehash(dict *d, int n) {
int empty_visits = n*10; // 一步rehash中最多访问的空桶的次数
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) { // 分n步进行rehash
dictEntry *de, *nextde;
/* 注意rehashidx不能越界,因为由于ht[0].used != 0,我们知道还有元素没有被rehash */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) { // 遇到空桶了
d->rehashidx++; // rehashidx移动到下一个桶
if (--empty_visits == 0) return 1; // 当前一次rehash过程遇到的空桶数量等于n*10则直接结束
}
de = d->ht[0].table[d->rehashidx]; // 获得当前桶中第一个key-value对的指针
/* 把当前桶中所有的key从旧哈希表移动到新哈希表 */
while(de) { // 遍历桶中的key-value对链表
unsigned int h;
nextde = de->next; // 链表中下一个key-value对的指针
/* 获取key的哈希值并计算其在新哈希表中桶的索引值 */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h]; // 设置当前key-value对的next指针指向1号哈希表相应桶得地址
d->ht[1].table[h] = de; // 将key-value对移动到1号哈希表中(rehash后的新表不会出现一个桶中有多个元素的情况)
d->ht[0].used--; // 扣减0号哈希表已使用节点的数量
d->ht[1].used++; // 增加1号哈希表已使用节点的数量
de = nextde; // 移动当前key-value对得指针到链表的下一个元素
}
d->ht[0].table[d->rehashidx] = NULL; // 当把一个桶中所有得key-value对都rehash以后,设置当前桶指向NULL
d->rehashidx++;
}
/* 检查我们已经对表中所有元素完成rehash操作 */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table); // 释放0号哈希表的哈希数组
d->ht[0] = d->ht[1]; // 把1号哈希表置为0号
_dictReset(&d->ht[1]); // 重置1号哈希表
d->rehashidx = -1;
return 0; // 完成整个增量式rehash
}
return 1; // 还有元素没有被rehash
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
timeInMilliseconds函数获取当前时间戳,单位毫秒。
long long timeInMilliseconds(void) {
struct timeval tv;
gettimeofday(&tv,NULL);
return (((long long)tv.tv_sec)*1000)+(tv.tv_usec/1000);
}
2
3
4
5
6
dictRehashMilliseconds函数在 ms 时间内 rehash,超过则停止。
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds(); // 起始时间
int rehashes = 0; // rehash次数
while(dictRehash(d,100)) { // 分100步rehash
rehashes += 100;
if (timeInMilliseconds()-start > ms) break; // 超过规定时间则停止rehash
}
return rehashes;
}
2
3
4
5
6
7
8
9
10
_dictRehashStep函数这个函数会执行一步的 rehash 操作,只有在哈希表没有安全迭代器时才会使用。当在 rehash 过程中使用迭代器时,我们不能操作两个哈希表,否则有些元素会被遗漏或者被重复 rehash。在字典的键查找或更新操作过程中,如果符合 rehash 条件,就会触发一次 rehash,每次执行一步。
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1); // 没有迭代器在使用时,执行一次一步的rehash
}
2
3
dictAdd函数向目标哈希表添加一个 key-value 对。
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key); // 先只添加key
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val); // 设置value
return DICT_OK;
}
2
3
4
5
6
7
8
dictAddRaw函数是低级别的字典添加操作。此函数添加一个 ket-value 结构但并不设置 value,然后返回这个结构给用户,这可以确保用户按照自己的意愿设置 value。此函数还作为用户级别的 API 直接暴露出来,这主要是为了在散列值内存储非指针类型的数据,比如:
entry = dictAddRaw(dict,mykey);
if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
返回值:
如果 key 已经存在返回 NULL。
如果成功添加了 key,函数返回 hash 结构供用户操作。
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); // 字典正在进行rehash时,执行一步增量式rehash过程
/* 获取key对应的索引值,当key已经存在时_dictKeyIndex函数返回-1,添加失败 */
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
/* 为新的key-value对分配内存
* 把新添加的元素放在顶部,这很类似数据库的做法:最近添加的元素有更高的访问频率。 */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; // 如果字典正在rehash,直接把新元素添加到1号哈希表中
entry = zmalloc(sizeof(*entry)); // 分配内存
entry->next = ht->table[index];
ht->table[index] = entry; // 把新元素插入哈希表相应索引下链表的头部
ht->used++; // 增加哈希表已使用元素数量
dictSetKey(d, entry, key); // 设置key
return entry;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
dictReplace函数向字典添加一个元素,不管指定的 key 是否存在。key 不存在时,添加后函数返回 1,否则返回 0,dictReplace()函数此时只更新相应的 value。
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, auxentry;
/* 尝试添加元素,如果key不存在dictAdd()函数调用成功,并返回1。 */
if (dictAdd(d, key, val) == DICT_OK)
return 1;
/* key已经存在,获取key-value对 */
entry = dictFind(d, key);
/* 对key-value对设置新value并释放旧value的内存。需要注意的是这个先设置再释放的顺序很重要,
* 因为新value很有可能和旧value完全是同一个东西。考虑引用记数的情况,你应该先增加引用记数(设置新value),
* 再减少引用记数(释放旧value),这个顺序不能被颠倒。 */
auxentry = *entry;
dictSetVal(d, entry, val);
dictFreeVal(d, &auxentry);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
dictReplaceRaw函数是 dictAddRaw()的简化版本,它总是返回指定 key 的 key-value 对结构,即使 key 已经存在不能被添加时(这种情况下会直接返回这个已经存在的 key 的 key-value 对结构)。
dictEntry *dictReplaceRaw(dict *d, void *key) {
dictEntry *entry = dictFind(d,key);
return entry ? entry : dictAddRaw(d,key); // key存在时返回它的key-value对结构,否则调用dictAddRaw
}
2
3
4
5
dictGenericDelete函数查找并移除一个元素。dictDelete函数移除字典中的指定 key,并释放相应的 key 和 value。dictDeleteNoFree函数移除字典中的指定 key,不释放相应的 key 和 value。
static int dictGenericDelete(dict *d, const void *key, int nofree)
{
unsigned int h, idx;
dictEntry *he, *prevHe;
int table;
if (d->ht[0].size == 0) return DICT_ERR; // 字典0号哈希表大小为0时直接返回错误
if (dictIsRehashing(d)) _dictRehashStep(d); // 如果字典d正在rehash,执行一步的rehash过程
h = dictHashKey(d, key); // 计算key的hash值
for (table = 0; table <= 1; table++) { // 遍历0号和1号哈希表移除元素
idx = h & d->ht[table].sizemask; // 获取key所在的哈希数组索引值
he = d->ht[table].table[idx]; // 获取idx索引位置指向的第一个entry
prevHe = NULL;
while(he) { // 遍历idx索引位置上的entry链表,移除key为指定值的元素
if (key==he->key || dictCompareKeys(d, key, he->key)) { // 找到该entry
/* Unlink the element from the list */
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
if (!nofree) { // nofree标志表示是否需要释放这个entry的key和value
dictFreeKey(d, he); // 释放key
dictFreeVal(d, he); // 释放value
}
zfree(he); // 释放enrty
d->ht[table].used--; // 减少已存在的key数量
return DICT_OK;
}
prevHe = he; // 没找到则向后查找
he = he->next;
}
/* 如果字典不是正在进行rehash,直接跳过对1号哈希表的搜索,因为只有在rehash过程中,
* 添加的key-value才会直接写到1号哈希表中,其他时候都是直接写0号哈希表。 */
if (!dictIsRehashing(d)) break;
}
return DICT_ERR; /* not found */
}
int dictDelete(dict *ht, const void *key) {
return dictGenericDelete(ht,key,0);
}
int dictDeleteNoFree(dict *ht, const void *key) {
return dictGenericDelete(ht,key,1);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
_dictClear函数销毁整个字典。dictRelease函数清空并释放字典。
int _dictClear(dict *d, dictht *ht, void(callback)(void *)) {
unsigned long i;
/* Free all the elements */
for (i = 0; i < ht->size && ht->used > 0; i++) { // 遍历整个哈希表
dictEntry *he, *nextHe;
if (callback && (i & 65535) == 0) callback(d->privdata); // 销毁私有数据
if ((he = ht->table[i]) == NULL) continue; // 跳过没有数据的桶
while(he) { // 遍历桶中的entry销毁数据
nextHe = he->next;
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
ht->used--; // 递减哈希表中的元素数量
he = nextHe;
}
}
/* 释放哈希表的哈希数组 */
zfree(ht->table);
/* 重置整个哈希表 */
_dictReset(ht);
return DICT_OK; /* never fails */
}
void dictRelease(dict *d)
{
_dictClear(d,&d->ht[0],NULL);
_dictClear(d,&d->ht[1],NULL);
zfree(d);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
dictFind函数查找字典 key。
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
unsigned int h, idx, table;
if (d->ht[0].used + d->ht[1].used == 0) return NULL; // 0号和1号哈希表都没有元素,返回NULL
if (dictIsRehashing(d)) _dictRehashStep(d); // 如果字典正在rehash,执行一次一步rehash
h = dictHashKey(d, key); // 计算key的哈希值
for (table = 0; table <= 1; table++) { // 在0号和1号哈希表种查找
idx = h & d->ht[table].sizemask; // 计算索引值
he = d->ht[table].table[idx]; // 获取哈希数组相应索引的第一个元素
while(he) { // 遍历元素链表,查找key
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL; // 如果字典不是正在进行rehash,直接跳过对1号哈希表的搜索,并返回NULL
}
return NULL;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
dictFetchValue函数获取字典中指定 key 的 value。
void *dictFetchValue(dict *d, const void *key) {
dictEntry *he;
he = dictFind(d,key); // 用key找到key-value entry
return he ? dictGetVal(he) : NULL;
}
2
3
4
5
6
dictFingerprint函数返回字典的指纹。字典的指纹是一个 64 位的数字,它表示字典在一个给定时间点的状态,其实就是一些字典熟悉的异或结果。当初始化了一个不安全的迭代器时,我们可以拿到字典的指纹,并且在迭代器被释放时检查这个指纹。如果两个指纹不同就表示迭代器的所有者在迭代过程中进行了被禁止的操作。
long long dictFingerprint(dict *d) {
long long integers[6], hash = 0;
int j;
integers[0] = (long) d->ht[0].table; // 0号哈希表
integers[1] = d->ht[0].size; // 0号哈希表的大小
integers[2] = d->ht[0].used; // 0号哈希表中元素数量
integers[3] = (long) d->ht[1].table; // 1号哈希表
integers[4] = d->ht[1].size; // 1号哈希表的大小
integers[5] = d->ht[1].used; // 1号哈希表中元素数量
/* 我们对N个整形数计算hash值的方法是连续地把上一个数字的hash值和下一个数相加,形成一个新值,
* 再对这个新值计算hash值,以此类推。像这样:
*
* Result = hash(hash(hash(int1)+int2)+int3) ...
*
* 用这种方式计算一组整型的hash值时,不同的计算顺序会有不同的结果。 */
for (j = 0; j < 6; j++) {
hash += integers[j];
/* 使用Tomas Wang's 64 bit integer哈希算法 */
hash = (~hash) + (hash << 21); // hash = (hash << 21) - hash - 1;
hash = hash ^ (hash >> 24);
hash = (hash + (hash << 3)) + (hash << 8); // hash * 265
hash = hash ^ (hash >> 14);
hash = (hash + (hash << 2)) + (hash << 4); // hash * 21
hash = hash ^ (hash >> 28);
hash = hash + (hash << 31);
}
return hash;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
dictGetIterator函数获取一个字典的不安全迭代器。dictGetSafeIterator函数获取一个字典的安全迭代器。
dictIterator *dictGetIterator(dict *d)
{
dictIterator *iter = zmalloc(sizeof(*iter)); // 为迭代器分配空间
iter->d = d;
iter->table = 0; // 迭代的是0号哈希表
iter->index = -1;
iter->safe = 0; // 0表示不安全
iter->entry = NULL;
iter->nextEntry = NULL;
return iter;
}
dictIterator *dictGetSafeIterator(dict *d) {
dictIterator *i = dictGetIterator(d);
i->safe = 1; // 1表示安全
return i;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
dictNext函数获取迭代器的下一个元素。
dictEntry *dictNext(dictIterator *iter)
{
while (1) {
if (iter->entry == NULL) { // 当前桶的entry链表已经迭代完毕
dictht *ht = &iter->d->ht[iter->table]; // 获取迭代器的哈希表指针
if (iter->index == -1 && iter->table == 0) { // 刚开始迭代0号哈希表时
if (iter->safe)
iter->d->iterators++; // 如果是安全的迭代器,就将当前使用的迭代器数量+1
else
iter->fingerprint = dictFingerprint(iter->d); // 不安全迭代器需要设置字典指纹
}
iter->index++; // 移动到下一个桶
if (iter->index >= (long) ht->size) { // 迭代器的当前索引值超过哈希表大小
if (dictIsRehashing(iter->d) && iter->table == 0) { // 字典正在rehash且当前是0号哈希表时
iter->table++; // 开始迭代1号哈希表
iter->index = 0; // 设置开始迭代索引为0
ht = &iter->d->ht[1]; // 更新哈希表指针
} else {
break; // 如果字典不在rehash且迭代结束,就跳出并返回NULL,表示没有下一个元素了
}
}
iter->entry = ht->table[iter->index]; // 获取当前桶上的第一个元素
} else {
iter->entry = iter->nextEntry; // 获取当前桶中entry的下一个entry
}
if (iter->entry) {
/* 保存nextEntry指针,因为迭代器用户有可能会删除当前entry */
iter->nextEntry = iter->entry->next;
return iter->entry;
}
}
return NULL;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
dictReleaseIterator函数释放字典迭代器。
void dictReleaseIterator(dictIterator *iter)
{
if (!(iter->index == -1 && iter->table == 0)) { // 如果当前迭代器时初始化状态且是0号哈希表
if (iter->safe) // 释放安全迭代器时需要递减当前使用的迭代器数量(安全迭代器只能有一个)
iter->d->iterators--;
else
assert(iter->fingerprint == dictFingerprint(iter->d)); // 迭代器的字典指纹和实时的字典指纹不符时报错
}
zfree(iter);
}
2
3
4
5
6
7
8
9
10
dictGetRandomKey函数从哈希表中随机返回一个 entry。适用于实现随机算法。
dictEntry *dictGetRandomKey(dict *d)
{
dictEntry *he, *orighe;
unsigned int h;
int listlen, listele;
if (dictSize(d) == 0) return NULL; // 字典没有元素时直接返回NULL
if (dictIsRehashing(d)) _dictRehashStep(d); // 字典在rehash过程中,执行一次一步的rehash
if (dictIsRehashing(d)) { // 字典正在rehash
do {
/* 我们知道0-rehashidx-1之间的索引范围内没有元素 */
h = d->rehashidx + (random() % (d->ht[0].size +
d->ht[1].size -
d->rehashidx));
he = (h >= d->ht[0].size) ? d->ht[1].table[h - d->ht[0].size] :
d->ht[0].table[h];
} while(he == NULL);
} else { // 字典不在rehash时,随机生成一个索引值,直到此索引值上有entry
do {
h = random() & d->ht[0].sizemask;
he = d->ht[0].table[h];
} while(he == NULL);
}
/* 我们找到了一个非空的桶,但它是一个链表结构,所以我们要从链表中随机获取一个元素。
* 唯一明智的方式是计算链表长度并随机选择一个索引值。*/
listlen = 0;
orighe = he;
while(he) { // 计算链表长度
he = he->next;
listlen++;
}
listele = random() % listlen;
he = orighe;
while(listele--) he = he->next;
return he;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
dictGetSomeKeys函数对字典进行随机采样,从一些随机位置返回一些 key。此函数并不保证返回'count'中指定个数的 key,并且也不保证不会返回重复的元素,不过函数会尽力做到返回'count'个 key 和尽量返回重复的 key。函数返回指向 dictEntry 数组的指针。这个数组的大小至少能容纳'count'个元素。函数返回保存在'des'中 entry 的数量,如果哈希表中的元素小于'count'个,或者在一个合理的时间内没有找到指定个数的元素,这个数字可能会比入参'count'要小。需要注意的是,此函数并不适合当你需要一个数量刚好的采样集合的情况,但当你仅仅需要进行“采样”时来进行一些统计计算时,还是适用的。用函数来获取 N 个随机 key 要比执行 N 次 dictGetRandomKey()要快。
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count) {
unsigned long j; // 字典内部的哈希表编号,0或1
unsigned long tables; // 哈希表数量
unsigned long stored = 0, maxsizemask; // 获取到的随机key数量,掩码
unsigned long maxsteps; // 最大步骤数,考虑到开销问题,超过这个值就放弃继续获取随机key
if (dictSize(d) < count) count = dictSize(d);
maxsteps = count*10; // 最大步骤数为需要获取的key的数量的10倍
/* 运行count次一步rehash操作 */
for (j = 0; j < count; j++) {
if (dictIsRehashing(d))
_dictRehashStep(d);
else
break;
}
tables = dictIsRehashing(d) ? 2 : 1; // 字典rehash过程中就有两个哈希表要采样,正常情况下是1个
maxsizemask = d->ht[0].sizemask;
if (tables > 1 && maxsizemask < d->ht[1].sizemask) // rehash过程中如果1号哈希表比0号哈希表搭则使用1号哈希表的掩码
maxsizemask = d->ht[1].sizemask; //
/* 获取一个随机索引值 */
unsigned long i = random() & maxsizemask;
unsigned long emptylen = 0; // 迄今为止的连续空entry数量
while(stored < count && maxsteps--) {
for (j = 0; j < tables; j++) {
/* 和dict.c中的rehash一样: 由于ht[0]正在进行rehash,那里并没有密集的有元素的桶
* 需要访问,我们可以跳过ht[0]中位于0到idx-1之间的桶,idx是字典的数据rehash的当前索引位置
* 这个位置以前的桶中的数据都已经被移动到ht[1]了。 */
if (tables == 2 && j == 0 && i < (unsigned long) d->rehashidx) {
/* 此外,在rehash过程中,如果我们获取的随机索引值i大于ht[1]的大小,则ht[0]
* 和ht[1]都已经没有可用元素让我们获取,此时我们可以直接跳过。
* (这一版发生在字典空间从大表小的情况下)。 */
if (i >= d->ht[1].size) i = d->rehashidx;
continue;
}
if (i >= d->ht[j].size) continue; //获取的随机索引值i超出范围,直接开始下一次循环
dictEntry *he = d->ht[j].table[i]; // 获取到一个entry
/* 计算连续遇到的空桶的数量,如果到达'count'就跳到其他位置去获取('count'最小值为5) */
if (he == NULL) {
emptylen++;
if (emptylen >= 5 && emptylen > count) {
i = random() & maxsizemask; // 重新获取随机值i
emptylen = 0; // 重置连续遇到的空桶的数量
}
} else { // 遇到了非空桶
emptylen = 0; // 重置连续遇到的空桶的数量
while (he) {
/* 把桶中entry链表中的所有元素加入到结果数组中 */
*des = he;
des++;
he = he->next;
stored++;
if (stored == count) return stored;
}
}
}
i = (i+1) & maxsizemask;
}
return stored;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
dictScan函数用于迭代字典中的所有元素。
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de;
unsigned long m0, m1;
if (dictSize(d) == 0) return 0;
if (!dictIsRehashing(d)) {
t0 = &(d->ht[0]);
m0 = t0->sizemask;
/* Emit entries at cursor */
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
} else {
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
do {
/* Emit entries at cursor */
de = t1->table[v & m1];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Increment bits not covered by the smaller mask */
v = (((v | m0) + 1) & ~m0) | (v & m0);
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
}
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits of the smaller table */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
return v;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
以下是一些私有函数的实现:
_dictExpandIfNeeded函数判断字典是否需要扩容,如果需要则扩容,否则什么也不做。
static int _dictExpandIfNeeded(dict *d)
{
/* 正在进行增量式rehash,直接返回 */
if (dictIsRehashing(d)) return DICT_OK;
/* 如果哈希表为空(散列数组大小为0),把它的大小扩容到初始状态(散列数组的初始大小) */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* 如果元素数量和散列数组的比值达到或超过1:1,且我们允许调整哈希表的大小(全局变量dict_can_resize为1)
* 或者虽然我们不允许调整哈希表大小(全局变量dict_can_resize为0),但是元素数量/散列数组的值
* 已经超过安全阈值(全局变量dict_force_resize_ratio),我们把哈希表大小调整为当前已使用桶数量的两倍。 */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
_dictNextPower函数返回大于且最接近 size 的 2 的正整数次方的数字,因为哈希表的大小一定是 2 的正整数次方。
static unsigned long _dictNextPower(unsigned long size)
{
unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) return LONG_MAX; // 防止size溢出
while(1) {
if (i >= size)
return i;
i *= 2;
}
}
2
3
4
5
6
7
8
9
10
11
_dictKeyIndex函数计算一个给定 key 在字典中的索引值。如果 key 已经存在,返回-1。需要注意的是如果哈希表正在进行 rehash,返回的总是 1 号哈希表(新哈希表)的索引值。
static int (dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
/* 如果需要,扩容字典 */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
/* 计算key的哈希值*/
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask; // 计算key的索引值
/* 遍历当前桶的entry链表查找指定的key是否已经存在 */
he = d->ht[table].table[idx]; // 桶中第一个元素
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) // 找到此key说明已存在,返回-1
return -1;
he = he->next; // 下一个元素
}
if (!dictIsRehashing(d)) break; // 字典不在rehash,只查看0号哈希表即可,跳过1号哈希表
}
return idx;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
dictEmpty函数清空字典数据并调用回调函数。
void dictEmpty(dict *d, void(callback)(void*)) {
_dictClear(d,&d->ht[0],callback); // 清空0号哈希表,并调用回调函数
_dictClear(d,&d->ht[1],callback); // 清空1号哈希表,并调用回调函数
d->rehashidx = -1; // 设置不在rehash过程中
d->iterators = 0; // 设置当前迭代器数量为0
}
2
3
4
5
6
dictEnableResize函数允许调整字典大小。dictDisableResize函数禁止调整字典大小。
void dictEnableResize(void) {
dict_can_resize = 1;
}
void dictDisableResize(void) {
dict_can_resize = 0;
}
2
3
4
5
6
7