 JJY 开发记录文档
JJY 开发记录文档
# 工具
- Splunk:搜索系统日志
- 云效:项目管理
- spug:代码部署
# 代码模式配置
# 应用占位
对app_id占用
# 动作占位
以上操作需要在编辑成功后手动复制到表中
SELECT * FROM app_action_meta WHERE app_id = 264
修改 is_end=0(不可作为截止动作),request_type=POST(默认都为 post)
# 执行动作
# 在 init 中
account_check/connection_config 中 id 为应用 id match_field id 为动作 id
# SampleData
触发动作需要实现 如何添加? 规则是什么?
# 触发动作
对于有字段需要用户填写的触发动作,需要手动修改additional=1,这样才能渲染出输入框
# 测试上线
- 申请测试数据库写入数据
- 申请安装包
- 提交代码到自己的开发分支
- 如果有第三方依赖,申请安装依赖
- 到 developer 分支合并修改的代码并提交
- 进入开发配置平台发布上测试申请(自行上线测试)
- 进入测试环境自测
# 生产上线
- 切换 master 分支 pull 最新的代码
- 切换到工作分支,合并 master 最新代码,如果有 conflict 则解决之
- 提交代码到远程工作分支
- 代码管理-合并请求-将工作分支合并到 master 分支
- 将开发数据库中的 sql 提交生产数据库中的审批工单(可以去测试上面复制)
- 等待代码合并通过
- 等待数据库审批通过后去开发者平台提交生产上线申请,其中备注栏可以填写安装依赖的信息
- 等待审批通过并执行
- 等待审批通过,完成上线
# 开发者平台
# oauth2 流程
去平台申请
client_id和client_secret配置授权回调地址
代表用户获取访问权限请求授权地址
authorize返回 code拼接请求地址,拉起访问授权页面
获取令牌,访问
token页面,此时响应如下:{ "token_type": "Bearer", "scope": "user.read%20Fmail.read", "expires_in": 3600, "access_token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiIsIng1dCI6Ik5HVEZ2ZEstZnl0aEV1Q...", "refresh_token": "AwABAAAAvPM1KaPlrEqdFSBzjqfTGAMxZGUTdM0t4B4..." }1
2
3
4
5
6
7利用 access_token 可以访问接口
利用 refresh_token 可以刷新 token
{
"token_type": "Bearer",
"scope": "Notes.Create Notes.Read Notes.ReadWrite email profile Notes.Read.All Notes.ReadWrite.All",
"expires_in": 3600,
"ext_expires_in": 3600,
"access_token": "EwBwA8l6BAAUkj1...4obR6Ag==",
"refresh_token": "M.R3_BAY.-CZVsfCyzxlGjk1Uy0GJXCnA6bh7WFTguj5rG7G3mZjXT...v6RZi*5mcjTQw$$"
}
2
3
4
5
6
7
8
# 对于 group 字段的编写
参考应用“聚水潭”执行动作——新建盘点单:
配置内字典列表的字段时:选择“动作字段设置”——字段组
配置列表套列表的数据类型
outPutData = [ { "key": "data", "label": "xxx", "type": "group", "items": [ { "key": "so_id", "label":"外部单号", "type": "string", "required": True }, { "key": "warehouse", "label":"仓库", "required": True, "multiples": False, "type": "number", "dropdown": True, "choices": [ { "key": 1, "label": "主仓" }, { "key": 2, "label": "销退仓" }, { "key": 3, "label": "进货仓" }, { "key": 4, "label": "次品仓" } ] }, { "key": "remark", "label":"备注", "type": "string", "required": False }, { "key": "items", "label": "商品明细", "type": "group", "help_txt":"最大50", "items": [ { "key": "sku_id", "label":"商品编码", "type": "string", "required": True },{ "key": "qty", "label":"数量", "type": "number", "required": True },{ "key": "batch_id", "label":"批次号", "type": "string", "help_txt":"批次号存在批次信息和有效期必填", "required": False },{ "key": "produced_date", "label":"批次日期", "type": "string", "help_txt":"时间戳;示例1644822870", "required": False },{ "key": "expiration_date", "label":"有效期", "type": "string", "help_txt":"时间戳;示例1644822870", "required": False }, ] } ] } ]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
# token
# tushare
4c562465125a1b5822095898168cd21a8870bac2dbbee0ed24fce68f
d95ea8510cd48dcaf50422b0fa4e7312643245ba731fbd308f084385
db42fb5372bce72ab61f22ef0a3310d5c441f09d17817f1cafd3ace2
b280312f2903dbec185c07535e9ab3f67df9bfe2220e08e46742b9b5
e53a32fc435f5fc25ab450333bda9d545856f1dfa1afc3d11699edcc
2
3
4
5
# 其他
# 部署上线
spug
# 迁移脚本
- 迁移大数据量时耗时
以下是几个常见的优化方式:
缓存数据:避免无必要的数据库访问,可以提高执行效率。对于读取频繁的数据,可以设置缓存,减少数据库访问次数。缓存可以使用 Redis、Memcached 等工具来实现。
批量操作:使用批量操作可以减少频繁的数据库访问操作,从而提高执行效率。例如,使用批量插入、批量更新、批量删除等方式。
数据库连接池:连接池是一种常见的优化方式,可以减少创建和销毁连接的开销,提高数据库的访问效率。连接池管理数据库连接的创建和销毁,每次访问数据库时,从连接池中获取连接,当访问结束后,将连接归还到连接池中。
优化 SQL 语句:通过优化 SQL 语句,可以减少对数据库的访问次数,提高执行效率。其中一些优化技巧包括:避免 SELECT *,尽量使用索引,避免使用子查询,使用 JOIN 替代子查询等。
数据库分片:对于数据量较大的数据库,可以将数据划分成多个分片,从而实现并行处理,提高执行效率。数据库分片可以根据业务需求来设定,例如按照时间、地理位置或者用户 ID 等进行分片。
以上是常见的一些优化方式,综合使用这些方法可以极大地提高数据库的执行效率和减少耗时。
# 实践
- 创建:
- 数据库使用连接池,创建时间减少 30%
- 回滚:
- 初始为 14 秒
- redis 缓存查询的数据。时间减少 30%,到 8 秒
- 批量提交,再减少 50%,到 6 秒
- 线程池(3s)
创建 15-11,删除 14-8.4 -3
# 订单处理
# 订单超卖问题

# 第一种方法 悲观锁
悲观并发控制(又名 “悲观锁”,Pessimistic Concurrency Control,缩写 “PCC”)是一种并发控制的方法。它可以阻止一个事务以影响其他用户的方式来修改数据。如果一个事务执行的操作读某行数据应用了锁,那只有当这个事务把锁释放,其他事务才能够执行与该锁冲突的操作。
悲观并发控制主要用于数据争用激烈的环境,以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本的环境中。
简而言之,悲观锁主要用于保护数据的完整性。当多个事务并发执行时,某个事务对数据应用了锁,则其他事务只能等该事务执行完了,才能进行对该数据进行修改操作。
update goods set num = num - 1 WHERE id = 1001 and num > 0
假设现在商品只剩下一件了,此时数据库中 num = 1;
但有 100 个线程同时读取到了这个 num = 1,所以 100 个线程都开始减库存了。
但你会最终会发觉,其实只有一个线程减库存成功,其他 99 个线程全部失败。
需要注意的是,FOR UPDATE 生效需要同时满足两个条件时才生效:
数据库的引擎为 innoDB
操作位于事务块中(BEGIN/COMMIT)
悲观锁采用的是「先获取锁再访问」的策略,来保障数据的安全。但是加锁策略,依赖数据库实现,会增加数据库的负担,且会增加死锁的发生几率。此外,对于不会发生变化的只读数据,加锁只会增加额外不必要的负担。在实际的实践中,对于并发很高的场景并不会使用悲观锁,因为当一个事务锁住了数据,那么其他事务都会发生阻塞,会导致大量的事务发生积压拖垮整个系统。
# 第二种办法 乐观锁
select version from goods WHERE id= 1001
update goods set num = num - 1, version = version + 1 WHERE id= 1001 AND num > 0 AND version = @version(上面查到的version);
2
3
这种方式采用了版本号的方式,其实也就是 CAS 的原理。
假设此时 version = 100, num = 1; 100 个线程进入到了这里,同时他们 select 出来版本号都是 version = 100。
然后直接 update 的时候,只有其中一个先 update 了,同时更新了版本号。
那么其他 99 个在更新的时候,会发觉 version 并不等于上次 select 的 version,就说明 version 被其他线程修改过了。那么我就放弃这次 update
# 第三种方法 redis 消息队列
在秒杀的情况下,高频率的去读写数据库,会严重造成性能问题。所以必须借助其他服务, 利用 redis 的单线程预减库存。比如商品有 100 件。那么我在 redis 存储一个 k,v。例如
每一个用户线程进来,key 值就减 1,等减到 0 的时候,全部拒绝剩下的请求。
那么也就是只有 100 个线程会进入到后续操作。所以一定不会出现超卖的现象。
# 第四种办法 redis 分布式锁
$expire = 10;//有效期10秒
$key = 'lock';//key
$value = time() + $expire;//锁的值 = Unix时间戳 + 锁的有效期
$lock = $redis->setnx($key, $value);
//判断是否上锁成功,成功则执行下步操作
if(!empty($lock))
{
//下单逻辑...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
第四种方法,可以参考本书的这个章节:Redis 实现分布式锁 (opens new window)
ref:
- mysql 超卖_mysql 解决超卖问题的锁分析_基少成多的博客-CSDN 博客 (opens new window)
- 答面试官问:如何防超卖,有几种实现方式 | Laravel China 社区 (opens new window)
# 超时订单如何处理
设置x-delayed-message,具体见
python - How could I send a delayed message in rabbitmq using the rabbitmq-delayed-message-exchange plugin? - Stack Overflow (opens new window) 和 Delayed Message Exchange - LavinMQ (opens new window)
redis 自动过期的实现方式是:定时任务离线扫描并删除部分过期键;在访问键时惰性检查是否过期并删除过期键。redis 从未保证会在设定的过期时间立即删除并发送过期通知。实际上,过期通知晚于设定的过期时间数分钟的情况也比较常见。 此外键空间通知采用的是发送即忘(fire and forget)策略,并不像消息队列一样保证送达。当订阅事件的客户端会丢失所有在断线期间所有分发给它的事件。
- TTL+死信队列
# 防止订单重复支付
支付的话,一般是走支付网关(支付中心),然后支付中心与第三方支付渠道(微信、支付宝、银联)交互。
支付成功以后,异步通知支付中心,支付中心更新自身支付订单状态,再通知业务应用,各业务再更新各自订单状态。
这个过程中经常可能遇到的问题是掉单,无论是超时未收到回调通知也好,还是程序自身报错也好。
总之由于各种各样的原因,没有如期收到通知并正确的处理后续逻辑等等,都会造成用户支付成功了,但是服务端这边订单状态没更新。
这个时候有可能产生投诉,或者用户重复支付。
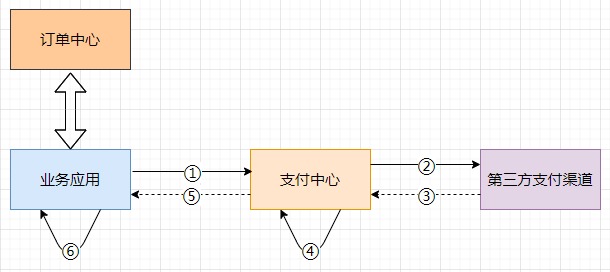
由于③⑤造成的掉单称之为外部掉单,由④⑥造成的掉单我们称之为内部掉单。
- 如何防止掉单
- 支付订单增加一个中间状态“支付中”,当同一个订单去支付的时候,先检查有没有状态为“支付中”的支付流水,当然支付(prepay)的时候要加个锁。支付完成以后更新支付流水状态的时候再讲其改成“支付成功”状态。
- 支付中心这边要自己定义一个超时时间(比如:30 秒),在此时间范围内如果没有收到支付成功回调,则应调用接口主动查询支付结果,比如 10s、20s、30s 查一次,如果在最大查询次数内没有查到结果,应做异常处理
- 支付中心收到支付结果以后,将结果同步给业务系统,可以发 MQ,也可以直接调用,直接调用的话要加重试(比如:SpringBoot Retry)
- 无论是支付中心,还是业务应用,在接收支付结果通知时都要考虑接口幂等性,消息只处理一次,其余的忽略
- 业务应用也应做超时主动查询支付结果
对于上面说的超时主动查询可以在发起支付的时候将这些支付订单放到一张表中,用定时任务去扫。
- 防止订单重复提交
创建订单的时候,用订单信息计算一个哈希值,判断 redis 中是否有 key,有则不允许重复提交,没有则生成一个新 key,放到 redis 中设置个过期时间,然后创建订单。
其实就是在一段时间内不可重复相同的操作。
大厂是如何防止订单重复支付的?三分钟彻底搞懂! (opens new window)
# 余额更新问题
- 先更新数据库,然后删除缓存,使用队列更新 redis 的 key
笔记
使用队列去更新 Redis 是一种常见的异步更新策略,有以下几个原因:
减少对数据库的直接访问:直接更新 Redis 可能会导致大量的并发请求直接访问数据库,对数据库造成较大的负载压力。通过使用队列,可以将更新请求先放入队列中,再由后台的任务或者工作线程从队列中取出并处理,减少对数据库的直接访问。
提高性能和响应速度:通过将更新请求放入队列中,可以异步地处理这些请求,不会阻塞主线程或客户端请求的响应。这样可以提高系统的性能和响应速度,避免因为更新 Redis 而导致的延迟。
避免数据不一致:使用队列可以保证更新操作的顺序性,避免并发更新导致数据不一致的问题。通过将更新请求按顺序放入队列中,然后依次处理,可以确保数据的一致性。
容错和恢复能力:如果更新 Redis 的过程中发生异常或失败,使用队列可以提供一种容错和恢复的机制。可以通过重试机制或者错误处理策略来处理更新失败的情况,保证数据的完整性和可靠性。
综上所述,使用队列去更新 Redis 可以提供更好的性能、响应速度和容错能力,同时保证数据的一致性。
# 幂等问题
- 页面防抖
- 页面埋点,当发起请求时设置有效期存到 redis 中,二次请求时,redis 存在 key 则不再创建订单,否则拦截掉;
如何实现下单的幂等性-腾讯云开发者社区-腾讯云 (opens new window)
笔记
防重和幂等是两个不同的概念,但它们都与请求的重复执行相关。
防重(Deduplication):防重是指在同一时间内,对于重复的请求,只处理一次,避免重复操作。它主要是为了防止网络延迟、重试等原因导致的请求重复执行。通常可以通过在请求中携带一个唯一标识,或者在后台通过记录已处理的请求来实现。
幂等性(Idempotence):幂等性是指对于同一个操作的重复执行,结果保持一致,不会产生副作用。在幂等操作中,无论执行一次还是多次,最终的结果都是一样的。在 API 设计中,幂等性是一个重要的原则,可以保证在重试、失败重发等情况下,不会对系统状态造成影响。常见的幂等操作包括创建资源、更新资源、删除资源等。
尽管防重和幂等都与请求的重复执行有关,但它们的目的和应用场景略有不同。防重更关注于避免重复处理请求,而幂等性更关注于操作结果的一致性。在实际应用中,可以结合使用防重和幂等的方法,来保证系统的稳定性和数据的一致性。
- 参考链接
- 微信支付 - 一笔订单,但是误付了两笔钱!这种重复付款异常到底该如何解决?|原创 - 程序通事 - SegmentFault 思否 (opens new window)
- 从无到有,支付路由系统升级打怪之路|原创 (opens new window)
- 如何防止重复下单 - 掘金 (opens new window)
# 设计模式
在实现一个购物功能时,可能会用到以下设计模式:
工厂模式(Factory Pattern):用于创建不同类型的商品对象,例如创建电子产品、衣服、食品等不同种类的商品。
单例模式(Singleton Pattern):用于管理购物车对象,确保系统中只有一个购物车实例。
观察者模式(Observer Pattern):用于实现购物车中商品数量的实时更新,当商品数量发生变化时,通知相关的观察者(例如购物车界面)进行更新。
适配器模式(Adapter Pattern):用于将不同支付方式(例如支付宝、微信支付、银行卡支付等)的接口转换成统一的支付接口,以方便客户端调用。
策略模式(Strategy Pattern):用于实现不同的促销策略,例如满减、折扣、赠品等,可以根据不同的策略进行价格计算。
# 现金收费抽象类
class CashSuper(object):
def accept_cash(self,money):
pass
class Purchase(CashSuper):
"""购买
价格x有效期
"""
def accept_cash(self,money):
return money
class ReNew(CashSuper):
"""
续费
原来购买的商品 商品乘以续费的有效期
"""
def __init__(self,discount=1):
self.discount = discount
def accept_cash(self,money):
return money * self.discount
class Upgrade(CashSuper):
"""
升级
新购买的商品-原来购买的商品价格 乘以购买有效期
"""
def __init__(self,money_condition=0,money_return=0):
self.money_condition = money_condition
self.money_return = money_return
def accept_cash(self,money):
if money>=self.money_condition:
return money - (money / self.money_condition) * self.money_return
return money
#具体策略类
class Context(object):
def __init__(self,csuper):
self.csuper = csuper
def get_result(self,money):
return self.csuper.accept_cash(money)
if __name__ == '__main__':
money = input("原价: ")
strategy = {}
strategy[1] = Context(Purchase())
strategy[2] = Context(ReNew(0.8))
strategy[3] = Context(Upgrade(100,10))
mode = input("选择折扣方式: 1) 原价 2) 8折 3) 满100减10: ")
if mode in strategy:
csuper = strategy[mode]
else:
print("不存在的折扣方式")
csuper = strategy[1]
print("需要支付: ",csuper.get_result(money))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
详细参阅支付系统策略模式实现代码
状态模式(State Pattern):用于管理订单的状态,例如创建、支付、发货、完成等状态的转换和处理。
模板方法模式(Template Method Pattern):用于定义购物流程的框架,例如选择商品、添加到购物车、填写收货地址、选择支付方式等步骤。
建造者模式(Builder Pattern):用于创建复杂的订单对象,可以根据用户的选择和需求,逐步构建订单对象。
迭代器模式(Iterator Pattern):用于遍历购物车中的商品列表,提供一种统一的方式来访问购物车中的商品。
以上设计模式可以帮助开发者更好地组织和管理购物功能的代码,提高代码的可复用性、可维护性和可扩展性。
# 面试可能提问
请介绍一下你在购物功能方面的开发经验和技能。
- 横表与竖表问题
- 项目刚开始的时候将需要付费的功能点很少,放在企业信息表中,通过垂直分表将功能点独立出来,然后抽象出几个类,如功能点、产品、产品包、资源包,区分功能,完成需求开发。
你在购物功能开发中遇到的最大挑战是什么?你是如何解决的?
- 存量数据处理 数据流程产品的资源包最开始记录在企业表中,需要创建资源包,同时系统中存在已付费用户,需要对用户的数据进行统计并迁移
- 原始数据处理及备份
- 关键数据缓存,提高效率
- 引用包数据量变大后插入效率变慢,通过修改源码提高效率
- 数据迁移完成之后的验证
内存泄漏
filprofiler、memray、guppy、objgraph 等
数据删除效率问题
casbin 数据量太大之后写入太慢
数据分片操作
你如何确保购物功能的安全性和数据保护?
你对购物功能的性能优化有什么经验和方法?
功能点扣费记录时,随着数据量的增加,会有大量历史记录存入表中,导致页面查询效率变低。
- 需要通过索引进行优化。
- 默认只展示最近一月的数据
- 对历史数据进行冷处理,放入备份数据表,然后在查询时区分,新数据在主库中查询,旧数据使用备份库查询
请描述一下你在购物功能开发中遇到的一个复杂的需求,并说明你是如何实现的。
付费存在初次购买、续费、升级等需求,需要使用不同的策略进行计算付费价格和有效期,策略模式
你如何处理购物车中的库存管理问题?有什么策略可以避免库存不足的情况?
你对用户体验和界面设计有什么看法?在购物功能中,你会如何提高用户体验?
你如何处理购物功能中的支付和结算流程?有没有遇到过支付安全性的问题?如何解决的?
你如何处理购物功能中的订单管理和物流跟踪?
你是否了解购物功能中的退货和售后服务流程?请描述一下你的经验和处理方式。
你如何与其他团队成员(如设计师、产品经理等)合作,以实现购物功能的开发?
你是否熟悉购物功能中的促销活动和优惠券的实现?请描述一下你的经验和方法。
你对支付系统的未来发展有什么想法和建议?
- 重复下单问题
- 重复下单退款问题
请描述一下你对购物功能中的数据分析和用户行为追踪的理解和实践。
你如何保持对购物功能开发中的最新技术和趋势的了解?