 Redis 中的底层数据结构(1)——双端链表
Redis 中的底层数据结构(1)——双端链表
本文将详细说明 Redis 中双端链表的实现。
在 Redis 源码(这里使用 3.2.11 版本)中,双端链表的实现在adlist.h和adlist.c中。
# 双端链表中的数据结构
双端链表是 Redis 中列表键的内部实现之一。
先来看一下双端链表的数据结构:
/* 双端链表节点数据结构 */
typedef struct listNode {
struct listNode *prev; // 前一个节点指针
struct listNode *next; // 后一个节点指针
void *value; // 节点的数据域
} listNode;
/* 双端链表迭代器数据结构 */
typedef struct listIter {
listNode *next; // 下一个节点指针
int direction; // 迭代方向
} listIter;
/* 双端链表数据结构 */
typedef struct list {
listNode *head; // 链表头节点指针
listNode *tail; // 链表尾节点指针
void *(*dup)(void *ptr); // 链表节点复制函数
void (*free)(void *ptr); // 链表节点释放函数
int (*match)(void *ptr, void *key); // 链表节点比较函数
unsigned long len; // 链表长度
} list;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
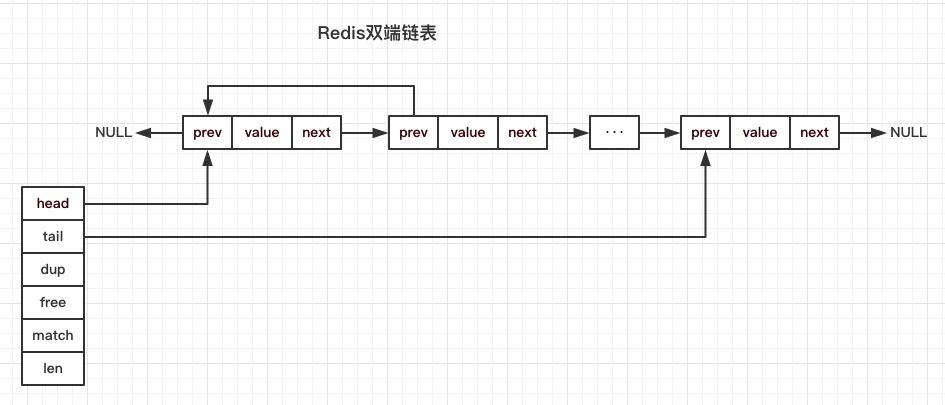
双端链表节点结构的prev指向前向节点,next指向后继节点,value是节点的数据域指针。
双端链表结构的header和tail分别指向链表的头节点和尾节点,方便从链表头部和尾部开始遍历链表。len保存了链表长度,即节点数量。
双端链表迭代器数据结构保存了next表示下一个节点的指针,direction表示迭代方向(头->尾/尾->头)。
注意三个和节点有关的函数:
void *(*dup)(void *ptr);声明了一个节点复制的函数指针,被指向的函数返回值类型为void *。void (*free)(void *ptr);声明了一个节点释放的函数指针,被指向的函数返回值类型为void。int (*match)(void *ptr, void *key);声明了一个节点比较的函数指针,被指向的函数返回值类型为int。
# 双端链表的宏和函数原型
先看双端链表的一组宏:
#define listLength(l) ((l)->len) // 获取链表长度
#define listFirst(l) ((l)->head) // 获取链表头节点
#define listLast(l) ((l)->tail) // 获取链表尾节点
#define listPrevNode(n) ((n)->prev) // 获取当前节点的前一个节点
#define listNextNode(n) ((n)->next) // 获取当前节点的后一个节点
#define listNodeValue(n) ((n)->value) // 获取当前节点的数据
#define listSetDupMethod(l,m) ((l)->dup = (m)) // 设置链表的节点复制函数
#define listSetFreeMethod(l,m) ((l)->free = (m)) // 设置链表的节点数据域释放函数
#define listSetMatchMethod(l,m) ((l)->match = (m)) // 设置链表的节点比较函数
#define listGetDupMethod(l) ((l)->dup) // 获取链表的节点复制函数
#define listGetFree(l) ((l)->free) // 获取链表的节点释放函数
#define listGetMatchMethod(l) ((l)->match) // 获取链表的节点比较函数
2
3
4
5
6
7
8
9
10
11
12
这些宏实际上就是一些结构体指针的间接引用赋值和取值,用来代替函数实现一些简单的操作,这样做相对于定义函数可以提高效率,毕竟上面这些宏如果用函数实现开销要大一些。
下面是双端链表相关的函数原型:
list *listCreate(void); // 创建一个空的链表
void listRelease(list *list); // 释放一个链表
list *listAddNodeHead(list *list, void *value); // 为链表添加头节点
list *listAddNodeTail(list *list, void *value); // 为链表添加尾节点
list *listInsertNode(list *list, listNode *old_node, void *value, int after); // 为链表插入节点
void listDelNode(list *list, listNode *node); // 删除指定节点
listIter *listGetIterator(list *list, int direction); // 获取指定迭代方向的链表迭代器
listNode *listNext(listIter *iter); // 使用迭代器获取下一个节点
void listReleaseIterator(listIter *iter); // 释放链表迭代器
list *listDup(list *orig); // 复制一个链表
listNode *listSearchKey(list *list, void *key); // 在链表中查找数据域等于key的节点
listNode *listIndex(list *list, long index); // 在链表中查找指定索引的节点
void listRewind(list *list, listIter *li); // 使迭代器的当前位置回到链表头,正向迭代
void listRewindTail(list *list, listIter *li); // 使迭代器的当前位置回到链表尾,反向迭代
void listRotate(list *list); // 移除链表当前的尾节点,并把它设置为头节点
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 双端链表的函数实现
下面的代码几乎包含了 Redis 双端链表的所有函数定义。双端链表作为一种通用数据结构,在现实中非常常用,其中的插入、删除、迭代、查找等操作也是数据结构课程中链表相关的基础知识。这部分的内容比较简单,Redis 的源码实现也非常简练高效,且代码质量很好。
listCreate函数创建一个新链表。被创建的链表可以使用 AlFreeList()函数释放,但是每个节点的数据域需要在调用 AlFreeList()函数之前调用用户自定义的节点释放函数来释放。
list *listCreate(void)
{
struct list *list;
if ((list = zmalloc(sizeof(*list))) == NULL) // 为链表结构开辟内存空间
return NULL;
list->head = list->tail = NULL; // 初始化头尾节点为NULL
list->len = 0; // 初始化链表长度为0
list->dup = NULL; // 初始化链表复制函数为NULL
list->free = NULL; // 初始化节点数据域释放函数为NULL
list->match = NULL; // 初始化节点比较函数为NULL
return list;
}
2
3
4
5
6
7
8
9
10
11
12
13
listRelease函数释放整个链表,此函数不能失败。
void listRelease(list *list)
{
unsigned long len;
listNode *current, *next;
current = list->head; // 当前节点从头节点开始
len = list->len;
while(len--) { // 从头至尾遍历整个链表
next = current->next; // 先保存当前节点的下一个节点指针
if (list->free) list->free(current->value); // 使用节点释放函数释放当前节点的数据域
zfree(current); // 释放当前节点
current = next; // 更新当前节点指针
}
zfree(list); // 释放整个链表
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
listAddNodeHead函数在链表头添加一个数据域包含指向'value'指针的新节点。出错时,会返回 NULL 且不会执行任何操作(链表不会有任何改变)。成功时,会返回你传入的'list'指针。
list *listAddNodeHead(list *list, void *value)
{
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL) // 初始化一个新节点
return NULL;
node->value = value; // 设置新节点的数据域为指定值
if (list->len == 0) { // 如果当前链表长度为0,头尾节点同时指向新节点
list->head = list->tail = node;
node->prev = node->next = NULL;
} else { // 如果当前链表长度大于0,设置新节点为头节点
node->prev = NULL;
node->next = list->head;
list->head->prev = node;
list->head = node;
}
list->len++; // 更新链表长度
return list;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
listAddNodeTail函数在链表尾添加一个数据域包含指向'value'指针的新节点。出错时,会返回 NULL 且不会执行任何操作(链表不会有任何改变)。成功时,会返回你传入的'list'指针。
list *listAddNodeTail(list *list, void *value)
{
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL) // 初始化一个新节点
return NULL;
node->value = value; // 设置新节点的数据域为指定值
if (list->len == 0) { // 如果当前链表长度为0,头尾节点同时指向新节点
list->head = list->tail = node;
node->prev = node->next = NULL;
} else { // 如果当前链表长度大于0,设置新节点为尾节点
node->prev = list->tail;
node->next = NULL;
list->tail->next = node;
list->tail = node;
}
list->len++; // 更新链表长度
return list;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
listInsertNode函数插入新节点到链表中某个节点的指定位置(前/后)。
list *listInsertNode(list *list, listNode *old_node, void *value, int after) {
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL) // 初始化一个新节点
return NULL;
node->value = value; // 设置新节点的数据域为指定值
if (after) { // 插入到老节点的后面
node->prev = old_node; // 设置新节点的上一个节点为老节点
node->next = old_node->next; // 设置新节点的下一个节点为老节点的下一个节点
if (list->tail == old_node) { // 如果链表尾节点为老节点,更新尾节点为新节点
list->tail = node;
}
} else { // 插入到老节点的前面
node->next = old_node; // 设置新节点的下一个节点为老节点
node->prev = old_node->prev; // 设置新节点的上一个节点为老节点的上一个节点
if (list->head == old_node) { // 如果链表头节点为老节点,更新头节点为新节点
list->head = node;
}
}
if (node->prev != NULL) { // 更新新节点和它上一个节点的关系
node->prev->next = node;
}
if (node->next != NULL) { // 更新新节点和它下一个节点的关系
node->next->prev = node;
}
list->len++; // 更新链表长度
return list;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
listDelNode函数从指定链表中移除指定节点。此函数不能失败。
void listDelNode(list *list, listNode *node)
{
if (node->prev) // 更新指定节点和它上一个节点的关系
node->prev->next = node->next;
else
list->head = node->next; // 指定节点是头结点时,设置指定节点的下一个节点为头结点
if (node->next) // 更新指定节点和它下一个节点的关系
node->next->prev = node->prev;
else
list->tail = node->prev; // 指定节点是尾结点时,设置指定节点的上一个节点为尾结点
if (list->free) list->free(node->value); // 释放指定节点的数据域
zfree(node); // 释放指定节点
list->len--; // 更新链表长度
}
2
3
4
5
6
7
8
9
10
11
12
13
14
listGetIterator函数返回一个链表的迭代器'iter'。初始化之后每次调用 listNext()函数都会返回链表的下一个元素。此函数不能失败。
listIter *listGetIterator(list *list, int direction)
{
listIter *iter;
if ((iter = zmalloc(sizeof(*iter))) == NULL) return NULL; // 初始化链表迭代器
if (direction == AL_START_HEAD)
iter->next = list->head;
else
iter->next = list->tail;
iter->direction = direction; // 设置迭代方向
return iter;
}
2
3
4
5
6
7
8
9
10
11
12
listReleaseIterator函数释放迭代器内存。
void listReleaseIterator(listIter *iter) {
zfree(iter);
}
2
3
listRewind函数使迭代器的当前位置回到链表头,正向迭代。
void listRewind(list *list, listIter *li) {
li->next = list->head;
li->direction = AL_START_HEAD;
}
2
3
4
listRewindTail函数使迭代器的当前位置回到链表尾,反向迭代。
void listRewindTail(list *list, listIter *li) {
li->next = list->tail;
li->direction = AL_START_TAIL;
}
2
3
4
listNext函数返回迭代器的下一个元素。如果没有下一个元素,此函数返回 NULL,否则返回指定列表下一个元素的指针。
listNode *listNext(listIter *iter)
{
listNode *current = iter->next; // 获取下一个节点指针
if (current != NULL) {
if (iter->direction == AL_START_HEAD) // 正向迭代时更新迭代器下一个节点指针为当前节点的后一个节点
iter->next = current->next;
else // 反向迭代时更新迭代器下一个节点指针为当前节点的前一个节点
iter->next = current->prev;
}
return current;
}
2
3
4
5
6
7
8
9
10
11
12
listDup函数复制整个链表。内存不足时返回 NULL。成功则返回原始链表的拷贝。节点数据域的'Dup'方法由 listSetDupMethod()函数设置,用来拷贝节点数据域。如果没有设置改函数,拷贝节点的数据域会使用原始节点数据域的指针,这相当于浅拷贝。原始链表不管在改函数成功还是失败的情况下都不会被修改。
list *listDup(list *orig)
{
list *copy;
listIter iter;
listNode *node;
if ((copy = listCreate()) == NULL) // 初始化拷贝链表
return NULL;
copy->dup = orig->dup; // 拷贝链表和原始链表的节点复制函数相同
copy->free = orig->free; // 拷贝链表和原始链表的节点数据域释放函数相同
copy->match = orig->match; // 拷贝链表和原始链表的节点比较函数相同
listRewind(orig, &iter); // 使迭代器的当前位置回到链表头,正向迭代
while((node = listNext(&iter)) != NULL) { // 遍历原始链表
void *value;
if (copy->dup) { // 设置了节点数据域复制函数
value = copy->dup(node->value); // 复制节点数据域
if (value == NULL) { // 数据域为NULL直接释放拷贝链表并返回NULL
listRelease(copy);
return NULL;
}
} else // 未设置节点数据域复制函数
value = node->value; // 直接取原始链表节点的数据域指针赋值
if (listAddNodeTail(copy, value) == NULL) { // 把复制得到的value添加到拷贝链表的尾部
listRelease(copy);
return NULL;
}
}
return copy;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
listSearchKey函数在链表中查找包含指定 key 的节点。使用由 listSetMatchMethod()函数设置的'match'方法来判断是否匹配。如果没有设置'match'方法,就使用每个节点的'value'指针直接和'key'指针进行比较。匹配成功时,返回第一个匹配的节点指针(搜索从链表头开始)。没有找到匹配的节点就返回 NULL。
listNode *listSearchKey(list *list, void *key)
{
listIter iter;
listNode *node;
listRewind(list, &iter);
while((node = listNext(&iter)) != NULL) { // 遍历整个链表
if (list->match) { // 如果设置了节点数据域比较函数,就调用它进行比较
if (list->match(node->value, key)) {
return node;
}
} else { // 否则直接比较key和node->value
if (key == node->value) {
return node;
}
}
}
return NULL;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
listIndex函数把链表当成一个数组,返回指定索引的节点。负索引值用来从尾巴开始计算,-1 表示最后一个元素,-2 表示倒数第二个元素,以此类推。当索引值超出返回返回 NULL。
listNode *listIndex(list *list, long index) {
listNode *n;
if (index < 0) { // index小于0,从尾部开始遍历
index = (-index)-1;
n = list->tail;
while(index-- && n) n = n->prev;
} else { // index大于0,从头部开始遍历
n = list->head;
while(index-- && n) n = n->next;
}
return n;
}
2
3
4
5
6
7
8
9
10
11
12
13
listRotate函数移除链表当前的尾节点,并把它设置为头节点。
void listRotate(list *list) {
listNode *tail = list->tail;
if (listLength(list) <= 1) return;
/* Detach current tail */
list->tail = tail->prev; // 设置尾节点为当前尾节点的前一个节点
list->tail->next = NULL; // 设置新尾节点后向关系
/* Move it as head */
list->head->prev = tail; // 设置当前头节点的前一个节点为原来的尾节点
tail->prev = NULL; // 设置新头节点前向关系
tail->next = list->head; // 设置新头节点后向关系
list->head = tail; // 更新新头节指针
}
2
3
4
5
6
7
8
9
10
11
12
13
14