 基于 DRBD 实现的双活方案文档阅读记录
基于 DRBD 实现的双活方案文档阅读记录
# 双机双活文档阅读
# 文档列表
DRBD 配置及设置
DRBD 双主模式.doc
客户端调用
EBSC 客户端接口说明.doc
客户端设计
双机双活 ODSP 设计.docx
服务端设计
EBSC 系统详细设计方案 v1.0.docx
基于双控的双机双活设计方案 V1.0.1.docx
# 概念
# 双机双活
存储跨站点双活技术是一个对称式的方案架构,两边一比一配比,中间通过链路( FC 或者 IP )连接,其最核心的难点公认是链路这个部分,这点从各家厂商方案披露支持的 RTT (往返延迟)和距离可以看出端倪。链路中断将造成两端健康的存储节点都认为对方挂掉,试图争取 Shared Resource (共享资源),并试图修改集群成员关系,各自组成一个集群,产生 Brain-Split (脑裂)现象,如果没有合理的机制去防范脑裂,将因互相抢夺共享资源自立集群,而导致共享卷数据读写不一致,产生更严重的后果。
在存储双活方案,防范脑裂通用的做法就是使用仲裁机制,在第三站点放置仲裁服务器或者仲裁存储阵列。通常有以下三种方式:
- 优先级站点方式。这种方式最简单,在没有第三方站点的情况下使用,从两个站点中选一个优先站点,发生脑裂后优先站点仲裁成功。但如集群发生脑裂后,优先站点也发生故障,则会导致业务中断,因此这种方案并非推荐的方案;
- 软件仲裁方式。这种方式应用比较普遍,采用专门的仲裁软件来实现,仲裁软件放在第三站点,可以跑在物理服务器或虚拟机上,甚至可以部署到公有云上;
- 阵列仲裁盘方式。这种方式是在第三站点采用另外一台阵列创建仲裁盘。这种方式稳定性,可靠性比较高。
# 具体到公司产品
使用 DRBD 双主模式,支持 GFS2、Oracle RAC 等共享集群文件系统的双机双活场景。
将两个存储系统组成“两点集群”,将系统的磁盘以软硬件的方式进行实时数据镜像,对外提供无差别服务。
脑裂是双活方案需必须要解决的故障。两个系统的数据镜像网络故障时脑裂发生,每一个工作节点都以为对端离线而对外提供服务导致数据撕裂损坏。这种情况下,既要保证数据不发生撕裂,也要决策出一个系统继续提供服务,仲裁服务应运而生。仲裁服务一般运行在存储系统以外的系统上,需要提供额外的链路来保证仲裁的可靠执行。
# RTO/RPO
# RTO:恢复时间目标
RTO 指的是应用程序可以中断或关闭多少时间而不会对业务造成重大损害。有些应用程序可能会停机数天而不会产生严重的后果。而一些高优先级的应用程序只能停下来几秒钟,否则将会让企业和客户难以应对,并导致业务丢失。
RTO 不仅仅是业务损失和恢复之间的持续时间。这个目标还包括 IT 部门必须采取的步骤来恢复应用程序及其数据。如果 IT 已经投入高优先级应用程序的故障转移服务,那么它们可以在几秒钟内安全地表达 RTO(IT 部门必须恢复本地环境,但由于应用程序正在云中进行处理,因此 IT 部门可能需要一些时间)。
企业的 RTO 任务是根据优先级和潜在业务损失对应用程序进行分类,并相应地匹配企业的资源。例如,接近零的 RTO 的典型计划将需要故障转移服务。4 小时 RTO 允许从裸机恢复开始进行本地恢复,并以完整的应用程序和数据可用性结束。对于 8 小时以上的 RTO,IT 团队可以与本地系统集成商签署维护合同。
# RPO:恢复点目标
恢复点目标是指企业的损失容限:在对业务造成重大损害之前可能丢失的数据量。该目标表示为从丢失事件到最近一次在前备份的时间度量。
如果以定期计划的 24 小时增量备份全部或大部分数据,那么在最坏的情况下,企业将丢失 24 小时的数据。对于某些应用来说,这是可以接受的,对于其他人来说并不是这样。
例如,如果企业的应用程序具有 4 小时 RPO,那么备份和数据丢失之间的***间隔时间将为 4 小时。拥有 4 小时的 RPO 并不一定意味着企业将失去 4 小时的数据。例如一个文字处理应用程序在午夜停止运行并在凌晨出现故障,那么可能没有丢失太多(或任何)数据。但是如果一个任务繁忙的应用程序在上午 10 点关闭并且直到下午 2 点才恢复,那么企业可能会失去 4 个小时的高价值并且可能无法替代的数据。在这种情况下,需要进行更加频繁的备份,以便访问特定于应用程序的 RPO。
这取决于应用优先级,单个 RPO 的范围通常为 24 小时、12 小时、8 小时、4 小时。以秒为单位测量到接近零。只要对生产系统的影响最小,8 小时以上的 RPO 就可以利用现有的备份解决方案。4 小时的 RPO 将需要计划的快照复制,而接近零的 RPO 将需要连续复制。在 RPO 和 RTO 都接近于零的情况下,将连续复制与故障转移服务结合使用,以实现接近 100%的应用程序和数据可用性。
参见恢复时间目标(RTO)和恢复点目标(RPO)的理解差异 - 51CTO.COM (opens new window)
# gRPC
A high-performance, open source universal RPC framework
一种实现 RPC 通信的框架。
RPC
所谓 RPC(remote procedure call 远程过程调用)框架实际是提供了一套机制,使得应用程序之间可以进行通信,而且也遵从 server/client 模型。使用的时候客户端调用 server 端提供的接口就像是调用本地的函数一样。
# why
gRPC 是一个现代的开源高性能 RPC 框架,可以在任何环境中运行。它可以高效地连接数据中心内和跨数据中心的服务,支持可插拔的负载平衡、跟踪、运行状况检查和身份验证。它也适用于分布式计算的最后一英里连接设备、移动应用程序和浏览器后端服务。
# 特点
- http2.0
- 通过 protobuf 来定义接口
- gRPC 可以方便地支持流式通信
- 省时、省传输空间
gRPC – Python (opens new window)
gRPC – Overview (opens new window)
gRPC 详解 - 简书 (opens new window)
gRPC 的那些事 - streaming | 鸟窝 (opens new window)
Python gRPC 入门 - 掘金 (opens new window)
# protobuf(Protocol Buffer)
类比 json、XML
谷歌用于序列化结构化数据(如 XML)的性能优异、跨语言、跨平台的序列化库。更小、更快和更简单。一旦定义了数据的结构化方式,就可以使用特殊生成的源代码轻松地从各种数据流和使用各种语言编写和读取结构化数据。
Protocol Buffers | Google Developers (opens new window)
Protobuf 终极教程 | 鸟窝 (opens new window)
Google Protobuf 简明教程 - 简书 (opens new window)
# why
- 足够简单
- 序列化后体积很小:消息大小只需要 XML 的 1/10 ~ 1/3
- 解析速度快:解析速度比 XML 快 20 ~ 100 倍
- 多语言支持
- 更好的兼容性,Protobuf 设计的一个原则就是要能够很好的支持向下或向上兼容
# 基于双控的双机双活设计方案 V1.0.1(server)
# 术语
| 序号 | 术语或者缩略语 | 说明性定义 |
|---|---|---|
| 1 | EBSC | 仲裁服务(External Brain-Split Shared Controller) |
| 2 | 仲裁服务器 | 运行 EBSC 服务的计算机系统 |
| 3 | 仲裁网络 | 存储系统与仲裁服务器之间的网络连接 |
| 4 | 镜像网络 | 双机系统进行数据镜像的网络 |
| 5 | 仲裁结点 | 使用 EBSC 服务的存储系统结点 |
| 6 | 共享仲裁 | 多套存储系统共用 EBSC 服务 |
| 7 | DCM | 仲裁服务共享数据管理单元 |
| 8 | GSC | 仲裁服务管理单元 |
| 9 | 抢占仲裁 | 通过特定接口尝试成为仲裁拥有者 |
| 10 | 仲裁拥有者 | 成功设置仲裁服务特定属性的仲裁结点 |
# 示意图
# 双机双活
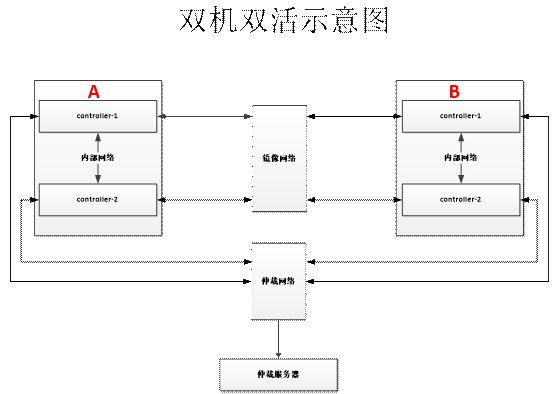
双活 AA,每个节点有两个控制器(双控),存储节点之间通过 DRBD 实现数据备份(备份使用的网络通路叫做镜像网络)
仲裁服务器用于发生 drbd 脑裂、某一节点宕机时通过报告-记录-查询提供有限的建议性的查询机制的仲裁服务,无法提供强制性的隔离措施。换而言之,只是个状态记录器。
仲裁服务与存储节点之间通过 仲裁网络 通信,提供 gRPC 和 cli 两种方式接口
# 仲裁服务
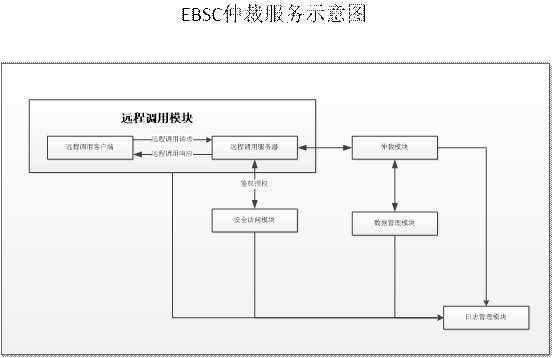
- 远程调用模块
- 安全访问模块(暂未实现?)
- 仲裁模块
- 数据管理模块
- 日志模块
# 模块实现
# 仲裁服务
init
init UUID
def init_server(): check_args_validate() node_is_connectable() get_uuid_from_dcm() init_gsc_and_set_gsc_config() register_gsc_to_dcm() return 1 or 01
2
3
4
5
6
7流程参见 V1.0 8.1.1、初始化仲裁服务
reset
恢复初始化状态保留 UUID。在故障解决后,从任意一个节点上可以恢复仲裁功能。
def reset_server(): check_args_validate() get_state_from_gsc() clear_quorum() save_is_ok = save_to_conf() if save_is_ok: return 0 else: rollback_conf() # 回滚具体操作是?之前会做备份? return 11
2
3
4
5
6
7
8
9
10get_status
def monitor_server(): check_args_validate() get_state_from_gsc() update_wdg_of_gsc() # log1
2
3
4add_node
添加节点采用会员邀请制(现有 node 发起)
def add_node(): check_args_validate() init_new_member() get_state_from_gsc() register_member_to_gsc()1
2
3
4
5del_node
删除节点不能是仲裁抢占成功者
def del_node():
check_args_validate()
has_node = get_state_from_gsc(id)
if not has_node:
return 0
else:
check_node_is_gainer()
if True:
return 1
else:
del_node_from_gsc()
return 0
2
3
4
5
6
7
8
9
10
11
12
仲裁服务
acquire
def acquire_quorum(): check_args_validate() get_state_from_gsc(id) if False: return 1 else: turn_to_next = False # 完成状态获取 # 设置自身优先级 # 获取优先级,对比竞争成员优先级 with read_lock(): get_quorum_priority() set_acquire_priority() # 优先级 high/middle/low cmp_priority() if self_is_top(): turn_to_next=True else: wait_priority_process() # TODO: 此处等待逻辑是? if has_more_top_req: return 1 else: turn_to_next=True # 获得入场券,可以去做竞争者了 if turn_to_next: with write_lock(): # 来晚了,仲裁结束,已经给别人了 if finished_quorum: if not self_is_owner: is_partner=check_owner_is_my_partner() # 同组成员 if is_partner: msg_it() # 释放写锁 release_write_lock() return 1 # 抢占失败 else: has_copied = check_has_create_replicate_data() if not has_copied: do_copy() # 记录优先级最高的节点并写入配置 update_config() save_to_conf() # 持久化 return 01
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43query_result
- 抢占成功(0,1)
- 同组成员抢占成功(0,2)
- 其他组抢占成功(什么时候返回此状况?see also:6.2.1)
def query_quorum(): # 是否和判断节点是仲裁获得者相同 check_args_validate() has_node = get_state_from_gsc(id) if has_node: on_process = check_is_quorum_process() if not on_process: return (0,0) # 无仲裁 wait_quorum_process() is_gainer = check_node_is_gainer() if is_gainer: return(0,1) # 抢占成功 else: is_group = check_is_group_option() # 分组场景 if is_group: is_partner=check_owner_is_my_partner() # 同组成员 if is_partner: return(0,2) # 组内成员抢到了 else: return 1 else: return 1 # 不是分组场景,返回失败 return 11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
release
抢占成功的节点,在故障解决后,释放抢占权限,恢复仲裁服务。(下一轮?)
def release_quorum(): check_args_validate() has_node = get_state_from_gsc(id) if has_node: is_gainer = check_node_is_gainer() if is_gainer: clear_quorum() mack_quorum_work_again() else: return 11
2
3
4
5
6
7
8
9
10
# 数据存储管理
# 持久化
文件(yml)存储持久化
每个系统以目录隔离
数据文件+指纹文件
- 写配置
def write_conf(): copy_data() update_config() yaml.dumps(data) singnal_data = compute_and_varify() try: with open(singnal_file,'w+') as f: f.write(singnal_data) try: save_conf_to_config() mv_copy_to_data() # 替换原来的数据 return 0 except writeError: do_rollback = True except writeError: do_rollback = True if do_rollback: rollback_config() return 11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21- 读配置
- pass
# 内存数据
DCM: GSC 的注册、查询、删除
GSC: 保证服务内成员并发安全
# 全局配置(DCM)
互斥机制+uuid
# GSC
单个仲裁系统内部成员互斥访问
# 日志管理
- stdout
- json
# 鉴权
- TSL 端对端加密
- 认证机制拦截器
# 双机双活 ODSP 设计(client)
# 接口定义
# 基础接口
- 实现一个 gRPC 客户端(等同于 socket_client),用于与客户端实现 C-S 交流
# 为什么使用 grpc
仲裁端返回 protobuf 数据结构,参见 v1.0 5.3、数据结构
控制器配置以及改组操作
# C
用户在页面分组输入每个控制器 IP 包括仲裁节点 IP,每个控制器的优先级设置
# R
hostname、组名
# U
组修改/重置,控制器 ip、优先级、影响因子(是什么含义?)成功后修改数据库
EBSCUpdate
req:uuid,gn,sip,update_args
# D
组删除
同步之后升主操作,激活输出
- 获取 drbdname/sanlun name
- drbd 升主,激活 target,数据记录
- 接管时同步后升主:离线接管检查时,去除对双主 drbd 状态的验证(为什么?)
触发仲裁
- EBSCFreeze
判断本机状态是否正常
向 server 发起仲裁请求
抢占成功关闭虚拟 ip 网络,记录网口状态
仲裁前需要判断***仲裁环***是否激活,激活时才可仲裁
查询历史仲裁记录
- EBSCInquire
request: ctrl ip,分组名、uuid、server ip
response: 仲裁时间与结果
单个仲裁环激活
检查仲裁网络是否正常,对仲裁结果 reset,成功后修改数据库(active=1)
EBSCReset
req:uuid,gn,sip
仲裁环删除
删除仲裁环信息,成功后对数据库清理
- EBSCDestroy
req: uuid,gn,sip
仲裁环监控线程
- 监控仲裁环状态 (控制器不在线时提示)
- 获取系统所有仲裁组,按主为单位进行轮询监控(什么意思?)
- 监控 ip 连通性,无法连通时修改 db,同时修改激活状态为 False
- 调用 EBSCInquire 接口判断控制器是否仲裁过,仅在未仲裁时讲仲裁组激活状态改为已激活
# 接管时的操作
# 逻辑
查询仲裁结果(上一步中的 5 为什么不行?)
resp: 组内成员成功、其他组成功、无抢占、error
def get_arbitrament_data(): if self_mem_success: mk_remote_drbd_out_put() set_cache_inactive() mk_primary_drbd_secondary() takeover_mem_up() elif other_group_success: drbd_connect() # 自动连接? drbd_parimary() else: log_it()1
2
3
4
5
6
7
8
9
10
11
# 恢复时的操作
def recover_op1():
get_recover_info()
if has_drbd:
check_all_loop_is_active() # loop: 仲裁环
if not is_active:
do_active_all_loop_op()
def recover_op2():
def drbd_rsync():
drbd_parimary()
active_target_output()
drbd_rsync()
2
3
4
5
6
7
8
9
10
11
12
13
# 初始化时操作
def init_op():
update_db_set_arbitra_inactive() # active:1 inactive:0
2
# 市场方案
# 华为 HyperMetro
静态优先
主要应用在无第三方仲裁服务器的场景,在发生链路中断脑裂现象时,强制使优先的存储节点继续提供服务,一般不建议采用该方式,因为在静态优先存储发生故障时,非静态优先的存储和优先的存储间通讯也中断,按照该模式,主机存储访问将全部中断;
仲裁服务器
HyperMetro 支持按双活 Pair 或双活一致性组(多对双活 Pair )为单位进行仲裁,仲裁精细度高,通常可配置以业务为粒度进行仲裁(双活一致性组),仲裁之后,业务均衡分布访问两个存储,实现站点间链路故障时,主机就近访问。
# EMC Vplex
在搭建 Vplex 双活时,可根据需要包括或不包括 Witness 。 Witness 只能作为虚拟机部署,且只支持 VMware 虚拟化,并部署在与两个 Vplex 集群不同的故障域中 ( 第三方站点 ) 。在两个 Vplex 集群之间进行仲裁,发生站点故障和集群间通信中断时, Witness 起到仲裁效果,提高业务连续性。
分离规则
分离规则是在与远程集群间的连接中断(例如,链路或远程集群故障)时,确定 I/O 一致性组处理方式的预定义规则。在异常情况下,集群通信恢复之前,大多数工作负载需要获得特定虚拟卷集,才能在一个 Vplex 集群上继续 I/O 访问,并在另一个 Vplex 集群上暂停 I/O 访问。
在 Vplex Metro 配置中,分离规则可以设置为静态优选集群。方法是设置: winner:cluster-1 、 winner:cluster-2 或 No Automatic Winner (无自动优胜者)。
在没有部署 Vplex Witness 情况下, I/O 一致性组将在优选集群中继续提供 I/O 服务,并在非首选集群中暂停 I/O 服务。
Vplex Witness
Vplex Witness 通过管理 IP 网络连接至两个 Vplex Metro 集群。 Vplex Witness 通过将其自身的观察与集群定期报告的信息进行协调,让集群可区分是集群内故障还是集群间链路故障,并在这些情况下自动继续相应站点上的 I/O 服务。
Vplex Witness 仅影响属于 Vplex Metro 配置中同步一致性组成员的虚拟卷,并且仅当分离规则没有指明集群 1 或集群 2 是一致性组优选集群时才会影响(也就是说,“无自动优胜者”规则生效时, Vplex Witness 才会影响一致性组)。
在没有 Vplex Witness 时,如果两个 Vplex 集群失去联系,生效的一致性组分离规则将定义哪个集群继续 I/O 服务以及哪个集群暂停 I/O 服务。
# why
如果仅使用分离规则来决定哪个站点是优胜者时,可能会增加站点故障时不必要的复杂性,因为可能需要手动干预才能恢复正常运行的站点 I/O 。
而采用 Vplex Witness 则会动态地自动处理此类事件,这也是它成为 Oracle Extend RAC 部署时,绝对必要项的原因。
Vplex Witness 提供了以下几项内容: 一是在数据中心之间自动实现负载均衡;二是两个数据中心为 Active/Active 模式;三是可以实现存储层故障处理完全自动化。
为了让 Vplex Witness 能够正确区分各种故障情况,必须将 Vplex Witness 部署在独立于两个站点集群之外的故障域,并且采用互不相同的网络接口。这将规避单个站点故障同时影响 Vplex 集群和 Vplex Witness 的风险。例如,如果将 Vplex Metro 配置的两个集群部署在同一数据中心的两个不同楼层,则建议将 Vplex Witness 部署在其他楼层;如果将 Vplex Metro 配置的两个集群部署在两个不同的数据中心,则建议在第三个数据中心部署 Vplex Witness 。
# IBM SVC
在 SVC 集群中有一个概念称为 Configuration Node ,即配置节点,是配置 SVC 集群后,系统自动产生的保存着所有系统配置行为的节点,不能人工更改配置节点。
当配置节点失效后,系统会自动选择新的配置节点,配置节点十分重要,它对 SVC 节点仲裁胜利起着决定性作用,仲裁胜利的排序规则通常如下:
- 配置节点(配置节点获得仲裁胜利的概率最高);
- 距离仲裁站点近的节点(探测延时较低的 SVC 节点获得仲裁胜利的概率次之);
- 距离仲裁站点远的节点(探测延时较低的 SVC 节点获得仲裁胜利的概率最低)。
例如,当两站点间光纤链路中断,第三站点仲裁节点活动时,脑裂发生,将通过投票仲裁选举获胜的站点,按照上述的仲裁胜利规则, Configuration Node 位于节点 2 ,选举站点 2 优先赢得仲裁,通过站点 2 恢复业务的正常存储访问。当第三站点仲裁节点不活动时,不影响主机的正常存储访问。
但倘若此时,两站点间光纤链路也中断了,发生脑裂,这时因为节点 2 为 Configuration Node ,它所拥有候选的 Quorum 将变为 Active Quorum ,该 Quorum 选举站点 2 为仲裁胜利站点,通过站点 2 恢复业务的正常存储访问。
# HDS GAD
GAD 的仲裁机制原理是采用仲裁磁盘的方式实现,暂不支持通过 IP 仲裁节点实现;仲裁磁盘是第三站点外部存储系统虚拟化的卷,可以是存储阵列,也可以是受支持的服务器磁盘,用于当链路路径或存储系统发生故障时,确定主机 I/O 应在哪个存储系统上继续访问。主存储和从存储每 500 毫秒检查一次仲裁磁盘的物理路径状态;
当主存储系统和从存储系统无法通信时,将执行以下操作:
当主存储系统无法通过数据路径和从存储系统进行通信时,会将此状态写入仲裁磁盘;
当从存储系统从仲裁磁盘检测到发生路径故障时,它将停止接受主机的读写操作 ;
从存储系统将与仲裁磁盘进行通信 , 将已停止读写操作的状态通知仲裁磁盘 ;
当主存储系统检测到从存储系统无法接受主机读写操作时,主存储系统将挂起 GAD Pair Volume 、主存储系统恢复主机读写访问操作。
如果主存储系统在通信中断后的 5 秒内,无法从仲裁磁盘检测到从存储系统不接受主机 I/O 的状态通知,主存储系统将挂起 GAD Pair Volume ,并恢复主机 I/O 访问;
如果主存储和从存储系统同时向仲裁磁盘写入通信停止的状态,则认为该通信中断由存储序列号较小的存储系统写入。由该存储系统挂起 GAD Pair Volume ,恢复该存储的主机读写访问操作。
如果仲裁磁盘故障,两个存储间的通信中断时,主存储和从存储系统均无法写入通信中断状态到仲裁磁盘,将导致两个存储的全都无法接收主机读写 I/O ,需要强制删除 GAD Pair Volume 恢复业务。